Kanonische Korrespondenzanalyse (KKA) in Excel
Dieses Tutorium zeigt Ihnen, wie Sie eine kanonische Korrespondenzanalyse - CCA - in Excel mithilfe der Statistiksoftware XLSTAT einrichten und interpretieren. Sie sind nicht sicher, ob dies das richtige Tool für die multivariate Datenanalyse ist, das Sie benötigen? Weitere Hinweise finden Sie hier.
Was ist eine kanonische Korrespondenzanalyse?
Die Kanonische Korrespondenzanalyse (auch KKA, auf Englisch Canonical Correspondence Analysis, oder CCA) wurde für Ökologen entwickelt, um das Verschwinden von einer Spezies auf bestimmte Variablen der Umwelt zurückzuführen (Ter Braak, 1986). Nichtsdestoweniger ist diese Methode, deren konzeptueller Rahmen genau definiert ist, auf andere Gebiete übertragbar. Das Geomarketing und die demographischen Analysen werden hiervon profitieren.
Um die KKA zu benutzen benötigen Sie:
- Eine Kontingenztabelle X, die die Häufigkeiten einer Serie von Objekten (in der Ökologie Spezies) für die verschiedenen Stätten, an denen jene gezählt wurden, beinhaltet;
- eine Tabelle Y mit deskriptiven Variablen, die an den gleichen Stätten gemessen wurden;
- optional eine dritte Tabelle Z, die deskriptive Informationen über die Effekte enthält, die Sie entfernen möchten, bevor Sie versuchen die Variabilität von X mittels Y zu erklären. In diesem Fall spricht man auch von einer partiellen KKA.
Das Ziel ist es, eine Karte mit den Objekten, den Stätten und den Variablen zu erzeugen. Datensatz für die Durchführung einer kanonischen Korrespondenzanalyse
Die Absicht ist, zu bestimmen, ob die drei deskriptiven Variablen helfen die Häufigkeiten der Insektenspezies zu erklären.
Erstellen einer kanonischen Korrespondenzanalyse
Um das Dialogfenster der KKA zu aktivieren, starten Sie XLSTAT, wählen dann den Multibloc Datenanalyse / CCA Befehl im XLSTAT Menu.
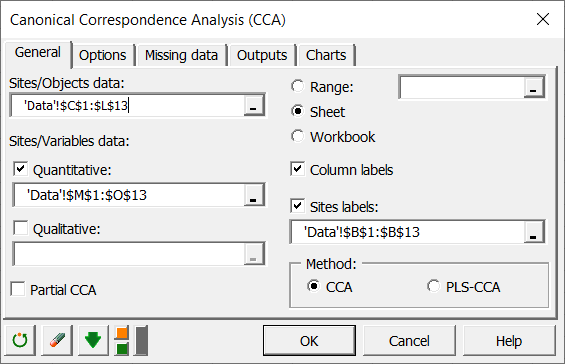
Sobald Sie auf den Button geklickt haben, erscheint das Dialogfenster. Wählen Sie die Daten, die den Stätten/Spezies-Daten entsprechen, (hier handelt es sich Spezies als Objekte) und dann die Daten, die den Stätten/Variablen-Daten entsprechen (in roter Farbe im Excel-Blatt angezeigt). Wählen Sie ebenfalls die Stättenbeschriftungen, stellen sie sicher, dass die Option “Spaltenbeschriftungen” aktiviert ist, damit XLSTAT weiß, dass eine Kopfzeile in der Datenauswahl enthalten ist.
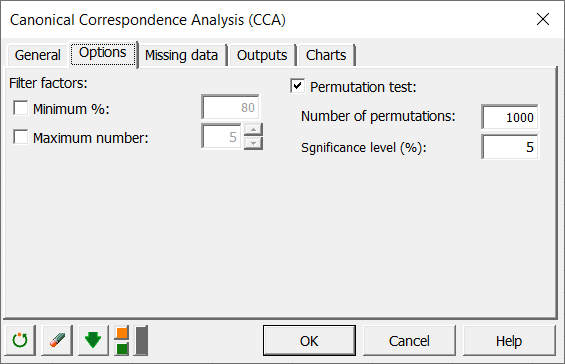
Aktivieren Sie den Reiter "Optionen" und stellen Sie sicher dass die Option “Permutationstest” aktiviert ist, um zu testen, ob der Effekt der drei Variablen auf die beobachteten Häufigkeiten von Insekten signifikant ist oder nicht. Wählen Sie 1000 zufällige Permutationen.
Auf den beiden unten stehenden Abbildungen sehen Sie welche Optionen in den Reitern “Ausgabe” und “Diagramme” gewählt wurden.
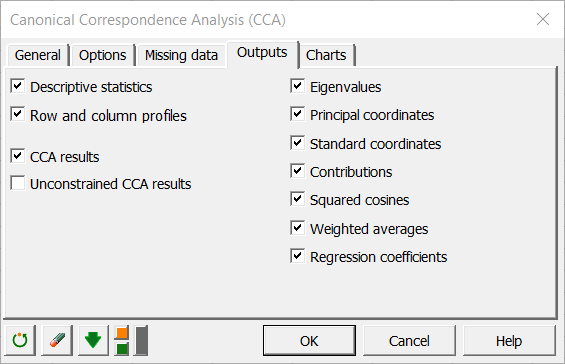
Nach dem Klicken auf den “OK” Button beginnen die Berechnungen und die Ergebnisse werden angezeigt auf einem neuen Excel-Blatt.
Interpretieren der Ergebnisse einer kanonischen Korrespondenzanalyse
Der erste Satz der Ergebnisse entspricht den deskriptiven Statistiken der vielen Variablen. Die Zeilen- und Spaltenprofile der Kontingenzmatrix werden angezeigt. Die Kontingenztabelle entspricht hier der Häufigkeit der Insekten an jeder Stätte. Die "gewichteten Mittel" entsprechen den Mittelwerten der Variablen der zweiten Tabelle, gewichtet mit der marginalen Summe der Zeilen der ersten Tabelle.
Anschließend werden die Ergebnisse des Permutationstest angezeigt.

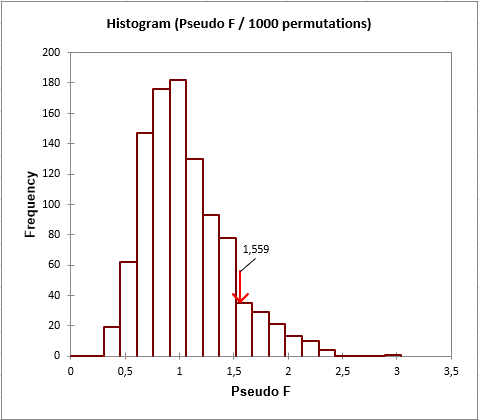
Aus dem Test wird geschlossen, dass die Stätten/Spezies-Daten nicht linear von den Stätten/Variablen-Daten mit einem Signifikanzniveau von 5% abhängen. Betrachtet man es genauer, so sieht man, dass der p-value gerade oberhalb des gewählten Schwellwertes liegt (0.05 gegen 0.089). Daher ist die Schlußfolgerung nicht so offensichtlich. Darüber hinaus möchten wir überprüfen, ob dies für alle Variablen wahr ist, oder ob einige Variablen die Ergebnisse besser erklären als andere.
Die nächste Tabelle zeigt an, wie die Trägheit zwischen der beschränkten KKA (die Analyse, die die erklärenden Variablen benutzt) und der unbeschränkten KKA (die unbeschränkte KKA ist eine Korrespondenzanalyse der Residuen der beschränkten KKA) verteilt ist.
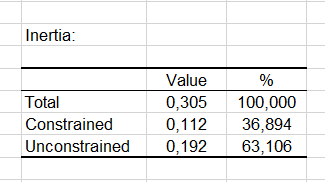
Man sieht, dass die beschränkte KKA nur 40% der Gesamtträgheit erklärt. Daher würde ein Blick auf die Ergebnisse der unbeschränkten Trägheit Sinn bereiten, und die Beziehung zwischen Stätten und Spezies sollte hier nicht im Detail analysiert werden. Um jedoch das Tutorial zu kürzen, werden wir uns auf die unbeschränkte KKA Ergebnisse konzentrieren. (Im Report kurz als KKA Ergebnisse bezeichnet.)
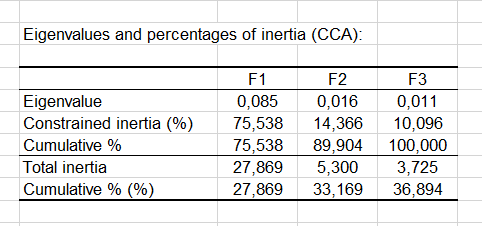
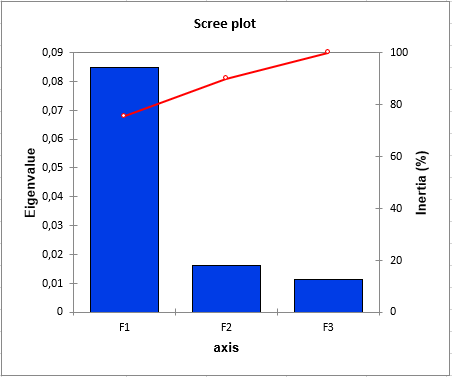
Innerhalb der KKA Eigenwertanalyse stellt man fest, dass der großteil der Trägheit durch die erste Achse beigetragen wird. Mit der zweiten Achse erhält man schein 92.5% der Trägheit. Dies bedeutet, dass die zweidimensionale KKA Karte zur Analyse der Beziehung zwischen den Stätten, den Spezies und den Variablen ausreicht.
Auf der KKA Karte (siehe unten) werden gleichzeitig Objekte (hier Insektenspezies), Stätten und Variablen aufgetragen.

Man sieht auf der Karte, dass eine erhöhte Häufigkeit der Spezies Insekt4 und Insekt5 in Verbindung mit hoher Feuchtigkeit und niedriger Höhe einhergeht. Insekt7 scheint empfindlicher auf den Abstand zu einem See zu sein. Insekt9 schein große Höhen oder geringe Feuchtigkeit zu bevorzugen.
Bemerkung: Wenn Sie die “Objekts” zu “Spezies” auf der KKA Karte verändern wollen, so klicken Sie lediglich auf einen Datenpunkt der zugehörigen Datenserie und wechseln Sie "Objekte" zu "Spezies" in der Excel Formel Toolbar.

War dieser Artikel nützlich?
- Ja
- Nein