Häufigkeiten, Modus und Balkendiagramme in Excel
In dieser Anleitung werden Häufigkeiten und Modusstatistiken sowie Balkendiagramme für qualitative Daten (die auch als kategoriale oder nominelle Daten bezeichnet werden) in Excel mit der XLSTAT-Software veranschaulicht.
Datensatz zur Beschreibung quantitativer Daten
Die Daten repräsentieren die Ergebnisse einer Umfrage, wie Menschen, die in zwei verschiedenen Städten leben, zur Arbeit pendeln. Die Zeilen entsprechen den Befragten und Spalten der Transportart sowie der Stadt, in der sie leben.
Die Stadt und die Art des Pendelns sind hier qualitative Variablen, die auch als nominale oder kategoriale Variablen bezeichnet werden. Die Werte, die eine qualitative Variable annehmen kann (Fahrrad, Bus, Auto… im Falle des Transportmodus) werden Kategorien oder Ebenen genannt.
Unser Ziel ist es, Transportvorlieben beim Pendeln zur Arbeit pro Stadt anhand allgemeiner deskriptiver Statistiken und Diagramme zu beschreiben: 1. Deskriptive Statistiken:
-
Der Modus, der die häufigste Art und Weise zu Pendel widerspiegelt (die häufigste Kategorie).
-
Die Häufigkeit gibt an, wie oft jeder Pendelmodus als Antwort angezeigt wird.
-
Die relative Häufigkeit, also die Häufigkeit geteilt durch die Gesamtzahl der Antworten.
-
Balkendiagramme und gestapelte Balkendiagramme, die die relativen Häufigkeiten nach Kategorien grafisch darstellen.
Auf diese Weise können wir die Kennzahlen der Umfrage extrahieren und mögliche Unterschiede in der Art und Weise erkennen, in der die Menschen in den beiden Städten pendeln.
Einrichten des Dialogfelds für deskriptive Statistiken
1. Wählen Sie nach dem Öffnen von XLSTAT den Menüpunkt XLSTAT / Daten beschreiben/ Deskriptive Statistiken aus (siehe unten).
2. Das Dialogfeld deskriptive Statistiken wird angezeigt.
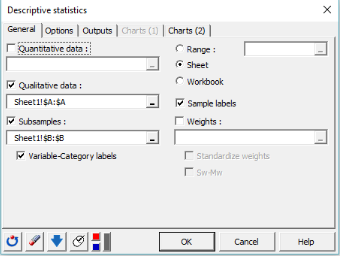
3. Wählen Sie in der Registerkarte Allgemein im Feld Qualitative Daten die Spalte aus, die der Transportart entspricht.
Da das Ziel darin besteht, die Transportpräferenz pro Stadt zu beschreiben, wählen wir im Feld Unterstichproben die Spalte, die der Stadt entspricht.
Wir möchten auch Variablen-Kategoriebeschriftungen in der Ausgabe anzeigen. Dazu gehören der Variablenname als Präfix und der Kategoriename als Suffix.
Wählen Sie schließlich die Option Sheet aus, um die Ergebnisse auf einem neuen Blatt anzuzeigen, und die Stichprobenbeschriftung, um die erste Zeile der Datentabelle als Beschriftungen zu betrachten.
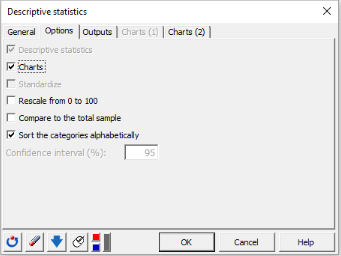
4. Aktivieren Sie in der Registerkarte Optionen die folgenden Optionen:
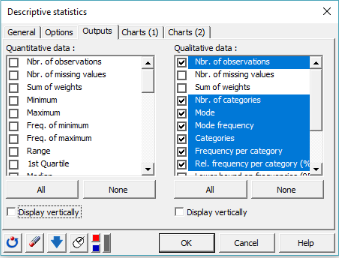
5. Wählen Sie in der Registerkarte Ergebnisse die folgenden Statistiken aus: Anzahl der Beobachtungen, Anzahl der Kategorien, Modus, Modusfrequenz, Kategorien, Häufigkeit pro Kategorie und rel. Häufigkeit pro Kategorie (%).
6. Aktivieren Sie in der Registerkarte Diagramme (2) die folgenden Optionen.
Die Balkendiagramme ermöglichen die Darstellung der Häufigkeiten oder relativen Häufigkeiten der verschiedenen Kategorien als Balken. Hier verwenden wir die relativen Häufigkeiten.
Wir möchten auch die gestapelten Balken anzeigen, um die relativen Unterschiede zwischen den Kategorien in jeder Stichprobe anzuzeigen.
Interpretation der Ergebnisse
Interpretation der deskriptiven Statistiken für qualitative Daten
Die Ergebnisse werden auf dem neuen Blatt mit der Bezeichnung Desc angezeigt (siehe unten).
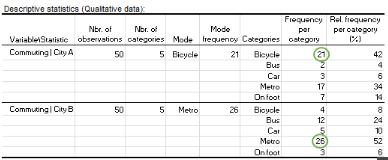
Die Tabelle enthält die folgenden Informationen für die beiden Stichproben:
-
Anzahl der Beobachtungen: 100 Personen nahmen an der Umfrage teil, 50 von jeder Stadt.
-
Anzahl der Kategorien: In den Antworten wurden 5 verschiedene Transportarten aufgeführt.
-
Der Modus und die Modusfrequenz: Das Fahrrad wird von Personen bevorzugt, die in der Stadt A (Modusfrequenz = 21) leben, während die U-Bahn der beliebteste Pendelmodus für die Bewohner der Stadt B ist (Modusfrequenz = 26).
-
Die Häufigkeit pro Kategorie: Drei Befragte aus Stadt B antworteten, dass sie zu Fuß zur Arbeit pendeln, während 12 angaben, sie würden mit dem Bus fahren.
-
Die relative Häufigkeit pro Kategorie (%): 45% der Befragten, die in Stadt A leben, fahren mit dem Fahrrad zur Arbeit, während nur 3% ihr Auto benutzen.
Die beiden letzten Statistiken werden auch als Flachsortierung bezeichnet.
Interpretieren von Balkendiagrammen und gestapelten Balkendiagrammen
-
Balkendiagramm
Die nächsten beiden Diagramme bieten einen Vergleich der verschiedenen Kategorien für jede Unterprobe. Ein Balken steht für die relative Häufigkeit einer bestimmten Kategorie. Der höchste Balken entspricht dem Modus, dh der Kategorie mit der größten relativen Häufigkeit
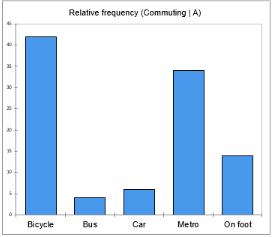
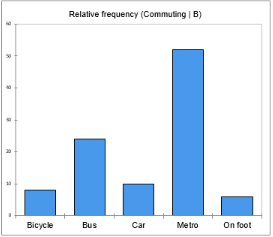 Aus dem ersten Diagramm können wir leicht bestätigen, dass Fahrrad die häufigste Ausprägung von Stadt A ist, wobei mindestens 40% der Befragten diese Form des Pendelns wählen. Personen aus der Stadt B scheinen die öffentlichen Verkehrsmittel zu bevorzugen, da die Bars der U-Bahn und des Busses eine relative Häufigkeit von mehr als 70% aufweisen.
Aus dem ersten Diagramm können wir leicht bestätigen, dass Fahrrad die häufigste Ausprägung von Stadt A ist, wobei mindestens 40% der Befragten diese Form des Pendelns wählen. Personen aus der Stadt B scheinen die öffentlichen Verkehrsmittel zu bevorzugen, da die Bars der U-Bahn und des Busses eine relative Häufigkeit von mehr als 70% aufweisen.
Man kann also sagen, dass die Stadt A fahrradfreundlicher ist als die Stadt B oder dass die in Stadt B lebenden Menschen relativ weit von ihrem Zuhause entfernt arbeiten, sodass Radfahren oder Wandern für sie nicht die beste Option ist.
-
Gestapelte Balkendiagramme
Der Vorteil eines gestapelten Balkens besteht darin, dass wir die Aufgliederung jeder Probe in ihre einzelnen Kategorien analysieren können. Hier zeigt das gestapelte Balkendiagramm den prozentualen Beitrag der verschiedenen Pendelmodi zu jeder Stadt.
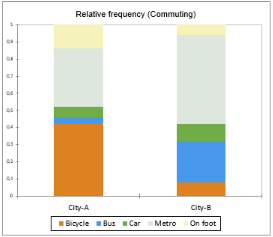
Zum Beispiel stellen wir fest, dass etwa die Hälfte der in Stadt B lebenden Personen mit der U-Bahn (grauer Teil des zweiten Balkens) zur Arbeit gehen, während das Laufen für einige von ihnen eine Option ist (gelber Teil des zweiten Balkens). In der Stadt A hat das Radfahren zur Arbeit eine große Anziehungskraft (orangefarbener Teil des zweiten Balkens), Bus und Auto sind die am wenigsten genutzten (grüne und blaue Teile des ersten Balkens), die mit den anderen Transportmitteln in Verbindung stehen.
Was kommt als nächstes: Verwenden von Kreuztabellen, um die Zusammenhänge zwischen zwei qualitativen Variablen zu untersuchen
Die Kontingenztabelle, auch Kreuztabelle genannt, ist eine effiziente Möglichkeit, die Beziehung zwischen zwei kategorialen Variablen zusammenzufassen. XLSTAT bietet ein Werkzeug zum Generieren einer Kontingenztabelle mit einer 3D-Ansichtsoption und berechnet verschiedene Statistiken, um die Beziehung zwischen den beiden Variablen zu messen. Schauen Sie sich dieses Tutorial an.
War dieser Artikel nützlich?
- Ja
- Nein