PLS-PM dans Excel : comparaison de groupes
Approche PLS
XLSTAT est le premier logiciel à mettre à la disposition des utilisateurs les méthodes de comparaisons multigroupes introduites dans le cadre de l’approche PLS par Wynne Chin (2005).
L’approche PLS permet de visualiser des relations entre des concepts non observables appelés variables latentes en utilisant un algorithme itératif basé sur des estimations par moindres carrés successives. Vous pourrez trouver des détails sur l’application de l’approche PLS dans le tutoriel « comment appliquer l’approche PLS avec XLSTAT? » ainsi que dans l’aide de XLSTAT.
Nous présentons ici une application spécifique de l’approche PLS lorsque plusieurs groupes d’observations doivent être comparés sur un modèle structurel prédéfini.
Nous prendrons un exemple dans le cadre de l’analyse de la satisfaction des consommateurs avec le modèle ECSI comme dans le tutoriel général avec une variable groupe supplémentaire.
Le module PLSPM de XLSTAT permet d’utiliser deux types de tests afin de comparer des coefficients et paramètres du modèle.
- Un test paramétrique : une adaptation du test t basé sur les écarts-types bootstrap. Pour un path coefficient beta :
 Avec n1 et n2 taille de chacun des groupes et SE’² variance du coefficient obtenue par bootstrap. Cette statistique suit une loi t à n1+n2-2 degrés de liberté. Ce test fonctionne bien lorsque les données ne dévient pas trop de la normalité et que les variances sont proches d’un groupe à l’autre.
Avec n1 et n2 taille de chacun des groupes et SE’² variance du coefficient obtenue par bootstrap. Cette statistique suit une loi t à n1+n2-2 degrés de liberté. Ce test fonctionne bien lorsque les données ne dévient pas trop de la normalité et que les variances sont proches d’un groupe à l’autre. - Un test non paramétrique : un test basé sur des permutations des données associées aux variables manifestes. On se base sur une statistique S qui permet de tester l'égalité des paramètres. Après permutation des éléments associés aux deux groupes, on compare S original et S permuté et on obtient la p-valeur :

Les hypothèses que nous désirons tester sont :
- H0 : les paramètres à comparer ne sont pas significativement différents
- Ha : les paramètres à comparer sont significativement différents
Le premier test suppose que les variances des paramètres sont proches d’un groupe à l’autre et que les résidus sont distribués suivant la loi normale. Il permet de vérifier l’égalité entre les coefficients structurels du modèle. Le second test permet de tester l’égalité des coefficients structurels, des coefficients entre les variables manifestes et les variables latentes et d’un certain nombre d’indices de qualité. Il est basé sur la permutation des observations associé aux deux groupes d’individus et en se basant sur une statistique afin d’obtenir une p-valeur associée au test.
Pour obtenir des détails sur ces procédures, veuillez vous référer à l’aide de XLSTAT.
La comparaison de groupes d’observations avec le module XLSTAT-PLSPM
Nous prendrons le même exemple que dans le tutoriel sur l’approche PLS. Le nouveau fichier peut être téléchargé en cliquant sur le lien donné au début de ce tutoriel.
La première étape consiste à passer en mode d’affichage expert. Dans la barre d'outils XLSTAT-PLSPM, cliquer sur Options XLSTAT-PLSPM, la boîte de dialogue suivante apparaît :

Sélectionner le mode expert et sauvegarder.
Créer un modèle en vous aidant du tutoriel général et en utilisant la feuille PLSPMGraph, les données et le modèle ECSI : 
Cliquer sur définir des groupes dans la barre d’outils path modeling. Sélectionner la variable permettant de définir les groupes (variable « groupes ») :

Cliquer alors sur lancer les calculs dans la barre d’outils path modeling. Un nouvel onglet nommé tests multigroupes apparaît :

Sélectionner le test t, les écarts types bootstrap sont obtenus avec le même nombre d’échantillons bootstrap que les intervalles de confiance définis dans l’onglet options.
Note : Si le bouton intervalle de confiance bootstrap n’est pas sélectionné, le test t ne peut pas être appliqué.
Sélectionner le test de permutation, indiquer le nombre de permutations et le niveau de signification du test afin de rejeter l’hypothèse d’égalité. Ce test permet de tester l’égalité des coefficients structurels (path coefficients), des corrélations entre variables latentes et manifestes et d’un certain nombre d’indices de qualité du modèle.
Note : Si le nombre de groupes est supérieur à deux, alors les tests de permutation ne peuvent pas être appliqués.
Résultats et interprétation des sorties d’une comparaison de groupes avec XLSTAT-PLSPM
Quatre nouvelles feuilles apparaissent en supplément des feuilles D1 et PLSPMGraph :
- PLSPM(1) : les résultats complets associés au premier groupe d’observations
- PLSPM(2) : les résultats complets associés au second groupe d’observations
- PLSPM(test t multigroup) : les sorties du test t sur les path coefficients
- PLSPM(Test de permutations) : les sorties des tests de permutations sur les paramètres sélectionnés.
Les deux premières feuilles peuvent être analysées indépendamment de la même façon que dans le tutoriel sur l’approche PLS.
Les deux groupes d’individus ont été sélectionnés en rapport avec la question : How well do you think “your mobile phone provider” compares with your ideal mobile phone provider?
Les résultats du test t pour les path coefficients sont les suivants :

Les résultats du test de permutation pour les path coefficients sont les suivants :
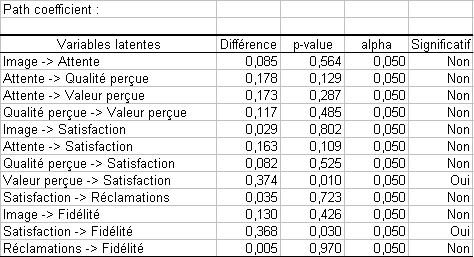
Ces deux tests permettent donc de voir que les path coefficients associés aux liens entre la valeur perçue et la satisfaction et entre la satisfaction et la fidélité sont significativement différents d’un groupe d’individus à un autre. Le lien entre satisfaction et fidélité étant très important, les experts en marketing devront porter une attention toute spéciale aux individus ayant répondu négativement à la question utilisée pour séparer les groupes.
Cet article vous a t-il été utile ?
- Oui
- Non