Générer plusieurs distributions dans un modèle de simulation en utilisant la fonction coller
Modèles de simulation
Les modèles de simulation permettent d'obtenir des informations, telles que la moyenne, médiane ou intervalle de confiance pour des variables qui n'ont pas une valeur exacte, mais pour lesquelles nous pouvons connaître, supposer ou calculer une distribution. Si des variables « résultat » dépendent de ces variables « distribution » au travers d'une formule établie, elles auront par voie de conséquence aussi une distribution. Sim vous permet de définir les distributions, puis d'obtenir, par le biais de simulations, une distribution empirique pour les variables d'entrée et de sortie ainsi que les statistiques correspondantes.
Les modèles de simulation sont utilisés dans de nombreux domaines tels que la finance et l'assurance, la médecine, la prospection pétrolière et minière, la comptabilité ou la prévision des ventes.
Quatre éléments sont nécessaires pour la construction d'un modèle de simulation :
- Distributions : elles correspondent à des variables aléatoires, XLSTAT donne un choix de plus de 30 distributions afin d'exprimer l'incertitude quant aux valeurs que peut prendre la variable. Par exemple, on choisira une distribution triangulaire lorsque l'on a une quantité que l'on sait pouvoir varier entre deux bornes mais avec une valeur qui semble plus probable. A chaque itération du calcul du modèle de simulation, un tirage aléatoire est effectué pour chaque distribution qui a été définie.
- Variables scénario : elles permettent d'introduire une quantité fixe dans le modèle de simulation. La seule exception étant pour les analyses tornado où cela peut varier entre deux bornes,
- Variables résultat : elles correspondent aux sorties du modèle. Elles dépendent directement ou indirectement, à travers une ou plusieurs formules Excel, des variables aléatoires auxquelles ont été affectées des distributions et, si disponible, des variables scénario. Le but des calculs d'un modèle de simulation est d’obtenir la distribution des variables résultat.
- Statistiques : elles permettent de suivre une statistique donnée pour une variable résultat. Par exemple, nous pourrions vouloir contrôler la déviation standard d’une variable résultat
Un modèle correct doit comprendre au moins une distribution et une variable résultat. Les modèles peuvent comprendre autant des quatre objets définis ci-dessus que vous le souhaitez. Un modèle peut être limité à une unique feuille Excel ou peut utiliser tout un classeur.
Dans ce tutorial nous créons un modèle de simulation qui simule le paiement des intérêts pour un emprunt sur 5 ans et utilise le taux d’intérêt de la première année pour calculer le profit net. Pendant ce tutoriel nous aborderons la copie de cellules de distribution en utilisant la fonction copier/coller d’Excel.
Jeu de données pour générer différents types de distributions dans un modèle de simulation
Notre modèle de simulation concerne le paiement des intérêts pour un emprunt. Les intérêts sont calculés sur 5 ans. A la fin le profit net est calculé en utilisant la fonction NPV d’Excel, le taux d’intérêt de la première année et le paiement des intérêts pendant les 5 ans. Le taux d’intérêt est distribué de façon égale entre 3.5% et 5.5%. Le capital de l’emprunt est de 10 000 Euros.
Nous commençons avec un modèle statique utilisant un taux moyen d’intérêt de 4.5%. Dans ce cas, le profit net calculé est de 1975 Euros.
.

Ce modèle peut être trouvé dans le fichier “modèle”

Générer des types de distributions dans un modèle de simulation en utilisant la fonction coller
Dans ce qui suit, nous utilisons des références relatives de façon à copier correctement les distributions. Vérifiez dans les options de Sim, que l’option Référence relative est bien cochée avant de créer des variables de distribution. Ceci permet à la fonction copier/coller de changer les références automatiquement.
Créer la première distribution
Sélectionnez la première variable de distribution dans B6, “ taux d’intérêt » de 2008, pour en faire la cellule active.
Une fois XLSTAT lancé, choisissez la commande XLSTAT Sim/ Définir une distribution ou cliquez sur le bouton correspondant dans le menu de Sim.

La boite de dialogue apparait. Choisissez la cellule Excel portant le nom “2008”. Celle ci sera intégrée en tant que référence relative ( format A1) dans la formule.
Choisissez une distribution uniforme avec a = 0.035 et b = 0.055

Une fois que vous avez cliqué sur OK, la fonction correspondante SimDist est insérée dans la cellule active.
Créer une distribution grâce à la fonction coller.
Il est possible d’entrer les quatre autres distributions en utilisant la fonction copier/coller ,à partir de la cellule que nous avons généré, dans les quatre cellules à droite de cette première. Vous avez également la possibilité, tout comme avec n’importe quelle formule Excel, de faire la manipulation suivante : sélectionner la cellule B6 que vous avez généré, utiliser la souris pour allez dans le coin en haut à gauche où le curseur est représenté par une croix noire, cliquez et tenez le bouton gauche de la souris puis faites glisser jusqu’à la cellule F6. De cette façon, vous avez également défini les 5 cellules. Le nom de la distribution sera « 2008 … 2012 »
![]()
Choisissez la cellule de résultat B9 qui contient la formule = NPV(B6,B7,C7,D7,E7,F7) en tant que cellule active. La variable de résultat est alors définie. Sélectionnez XLSTAT/ **XLSTAT / Sim / Définir un résultat ou cliquer sur le bouton correspondent dans la bar de menu SIM.
**La boite de dialogue de résultat apparait. Sélectionnez les données sur le tableau Excel. Choisissez la cellule Excel ou le nom « NPV » apparait.
Une fois que vous avez cliqué sur OK, la fonction correspondante de SimRes est insérée dans la cellule active.
Ce modèle peut être trouvé dans le fichier Excel “modèle”
Lancer la simulation
Pour commencer la simulation , sélectionnez XLSTAT / Sim / Simulation – Lancer les calculs ou cliquez sur le bouton correspondant dans le menu de Sim.
La boite de dialogue Simulation – lancer les calculs apparait.. Fixer le nombre de simulations à 1000.
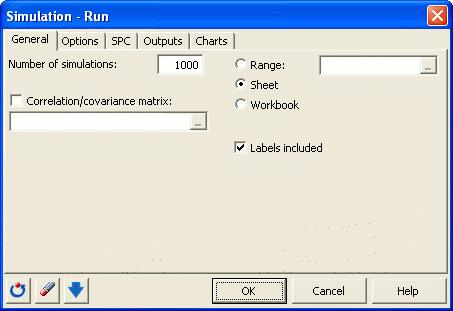
Dans l’onglet options, rentrer les paramètres des analyses Tornado et Spider. Sélectionnez la valeur centrale en tant que valeur par défaut. Choisissez un nombre de points de 10 dans l’intervalle, et une valeur de -10% jusqu’à +10% pour la valeur de la déviation.

Le calcul commence lorsque vous cliquez sur OK.
Interpréter les résultats de la simulation
Le premier résultat est un résumé des éléments inclus dans le modèle. Dés détails sur les variables de distribution et sur les variables de résultats sont affichés.

Sur le tableau ci-dessous, nous retrouvons des statistiques descriptives, des histogrammes et des quantiles pour chaque variable de distribution.

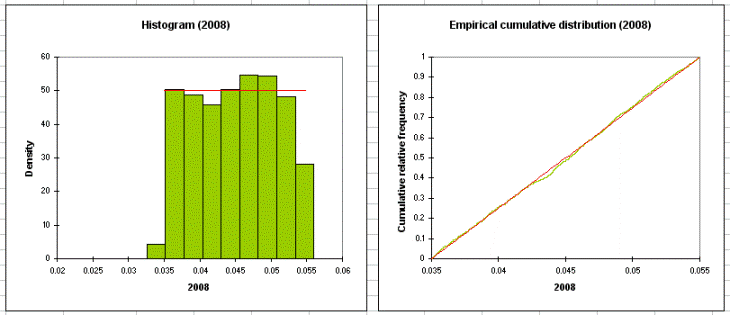
Les tableaux ci dessous nous donnent des détails concernant les variables de résultat (statistique descriptive, histogrammes et quantiles). Puis, les résultats de l’analyse de sensibilité sont affichés. Ses résultats dépendent des iterations des simulations.

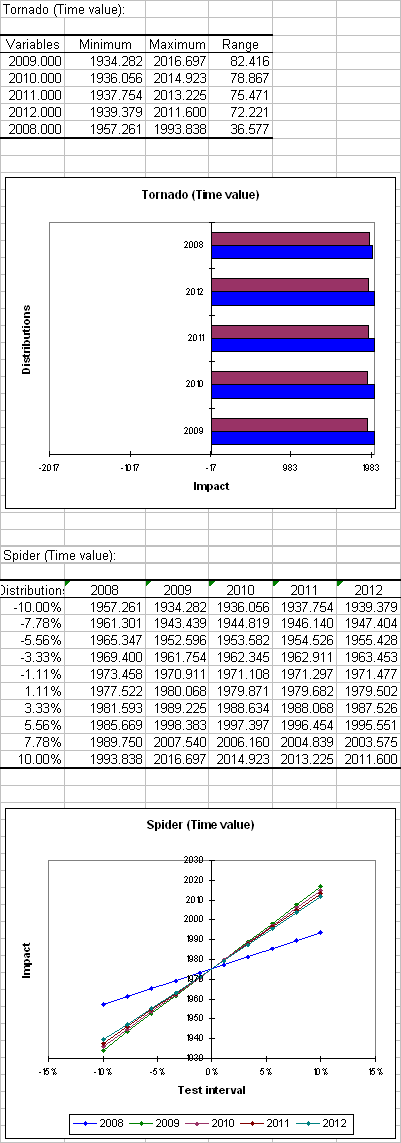
La prochaine section présente l’analyse Tornado. Les analyses de Tornado et Spider ne sont pas basées sur les simulations mais sur une analyse point par point de toutes les variables d’entrée (les variables aléatoires et les variables scénario).
Au cours de l'analyse tornado, pour chaque variable résultat, les variables aléatoires d'entrée et les variables scénario sont analysées une par une. On fait varier leur valeur entre deux bornes et on enregistre la valeur de la variable résultat, afin de savoir comment chaque variable influence la variable résultat. Pour une variable aléatoire, les valeurs explorées peuvent l'être autour de la médiane ou autour de la valeur par défaut de la variable, avec des limites définies par les percentiles ou par la déviation. Pour une variable scénario, l'analyse est effectuée entre les deux limites spécifiées lors de la définition de la variable. Le nombre de points est une option qui peut être modifiée par l'utilisateur avant d'exécuter le modèle de simulation.
L’analyse spider ne fait pas qu’afficher le changement minimum et maximum de la variable de résultats mais aussi la valeur de la variable de résultat pour chaque donnée des variables aléatoires et des variables scénario. Ceci est utile pour vérifier si la dépendance entre les variables de distribution et les variables de résultats est monotone ou pas.
Dans le premier tableau le minimum et le maximum changent et les gammes correspondantes sont affichées pour chaque variable de distribution. Dans ce cas tous les taux d’intérêt sont plus ou moins les mêmes.
Dans la deuxième section, pour l’analyse spider nous pouvons voir que le taux d’intérêt de la première année a moins d’impact que les autres taux d’intérêt. Ceci s’explique car le taux d’intérêt pour la première année est utilisé dans la formule NPV.
Cet article vous a t-il été utile ?
- Oui
- Non