Clustering tables by means of CLUSTATIS with Excel
This tutorial shows how to compute and interpret a clustering of tables by means of CLUSTATIS in Excel using the XLSTAT software.
Dataset for running the CLUSTATIS method
The data come from a projective mapping/Napping study carried out in Rennes by AGROCAMPUS OUEST. Eight smoothies were tasted by 24 subjects (panelists) and then placed on a tablecloth. The coordinates were collected for the STATIS analysis. If a panelist considers two products to be similar, the latter ones are placed closed by on the tablecloth, so they have similar coordinates. The original file can be obtained with the R SensoMineR package.
This dataset is also used in our tutorial on STATIS, in order to analyse smoothies directly without subject clustering.
Goal of this tutorial
The aim here is to perform a three-step data analysis: 1. Segment the tables (named here configurations) of data, i.e. the subjects herein, according to their perceptions of the products. The CLUSTATIS method will be used to create the most homogeneous classes possible. 2. Analyse each class of subjects using the STATIS method in order to determine the differences in perceptions of smoothies between classes. 3. Determine clustering quality indices.
Setting up a CLUSTATIS analysis in XLSTAT
Select the XLSTAT / Advanced features/ Sensory data analysis/ CLUSTATIS command (see below).

The CLUSTATIS dialog box appears.
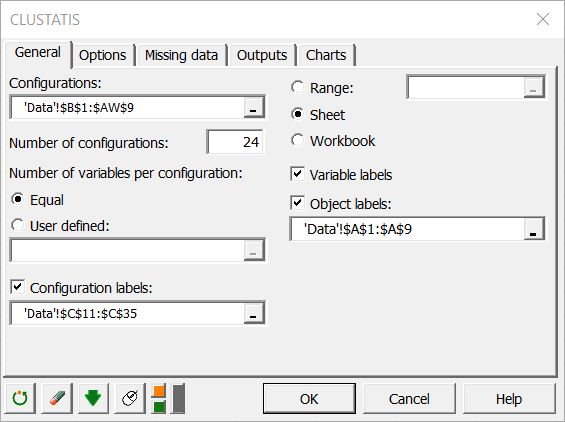
In the General tab, select the data on the Excel sheet of the demo file that corresponds to the configurations (a configuration corresponds here to the set of coordinates given by a subject). The number of configurations must then be entered. Herein, there are 24 contiguous tables corresponding to the 24 subjects.
As each configuration has 2 variables, we can let XLSTAT know that the number of variables is constant by selecting the Equal option. If the number of variables is different for a least one configuration, you need to select a column that contains the number of variables for each configuration.
Finally, activate the options Variable labels and the Object labels (in our case the smoothies).
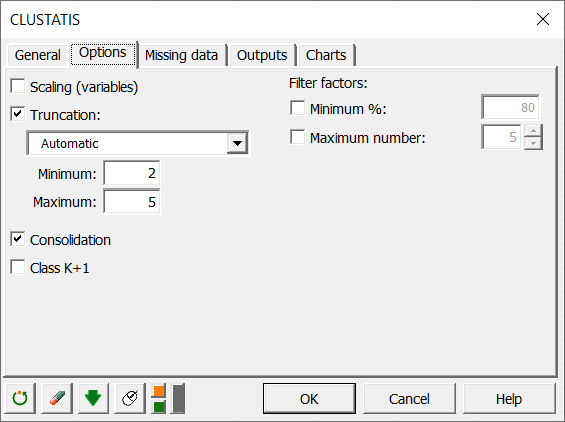
In the Options tab, we chose to not reduce the variables, since within each configuration, all variables are on the same scale. We decided to leave the choice of the number of classes automatic, and to apply a consolidation of the classes obtained by the hierarchical algorithm in order to obtain a more precise cluster analysis.
In the Charts tab, if you select the Display charts on two axes box, you will automatically have the representation on the first 2 factorial axes of the different maps. If you uncheck it, a window will open and you will be able to choose your axes.
Interpreting the results of a CLUSTATIS analysis in Excel using XLSTAT
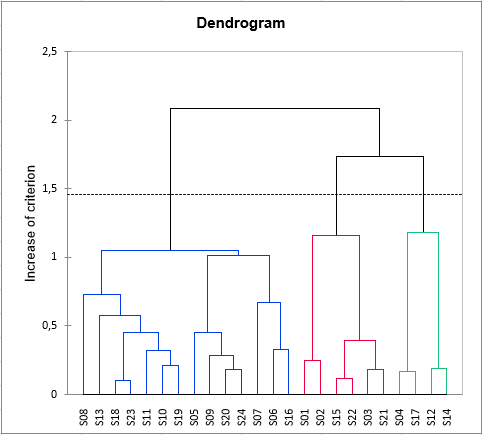
The chart below is the dendrogram. It represents how the algorithm works to group the configurations, then the groups of configurations. As you can see, the algorithm has successfully grouped all the configurations. The dotted line represents the automatic truncation, leading to three groups.
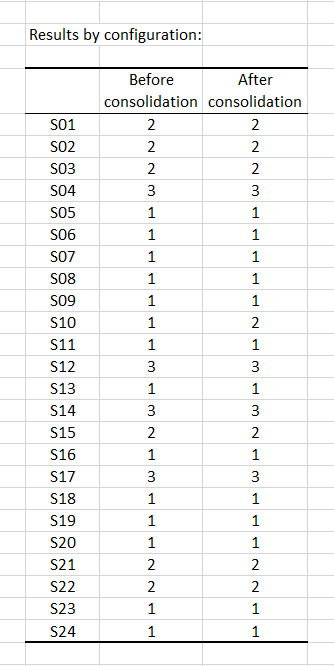
The following table shows the classes of the different configurations before and after consolidation. It appears that only subject 10 changed class with the consolidation.
Then comes the analysis of each of the classes built. The representation of the objects (smoothies here) in each class shows differences in perception between the classes of subjects, especially concerning the smoothie Carrefour_SB. Indeed, the latter is placed with the smoothie Innocent_SB by the subjects in class 1, with Innocent_PBC and Casino_PBC by the subjects in class 2, and with Carrefour_MP by those in class 3.
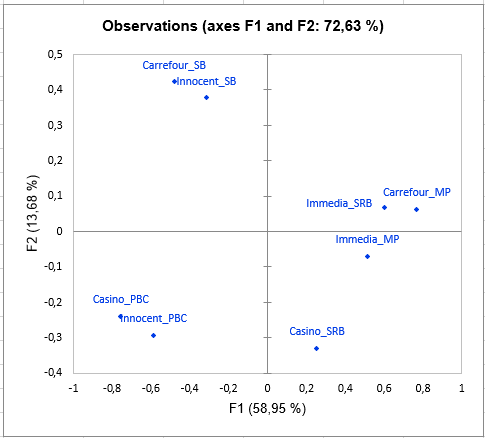
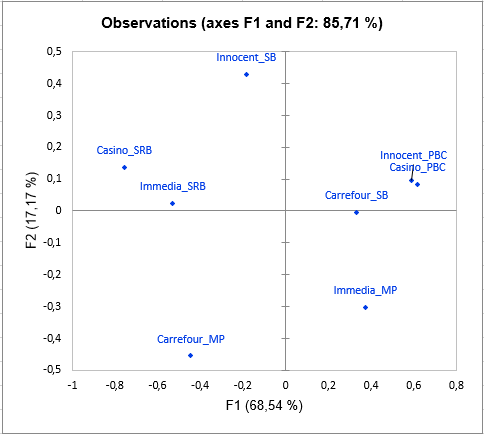
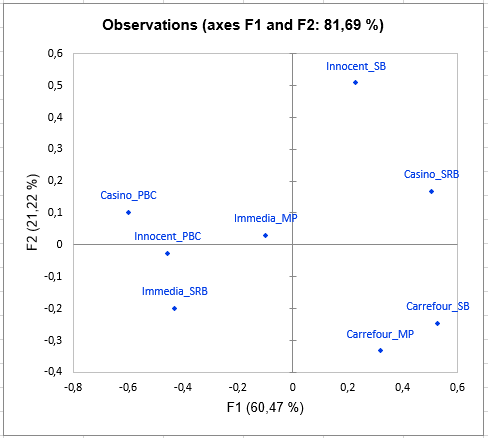
The following graph gives indications on the proximity of the configurations and the consensus of the class in which they are placed. These proximities are represented by the RV coefficient, which is an index of similarity between 0 and 1. In class 2, we can observe that subject 2 is much further from the consensus than the others, which means that it does not conform well to the class. His perception is different from all the classes (since he has been placed in the class that most correspond him by the algorithm). This kind of problem can be solved by adding the "K+1" class in the Options tab, which is an additional class designed to set aside atypical configurations.
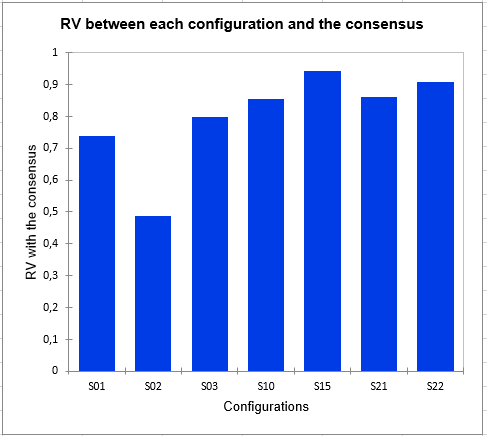
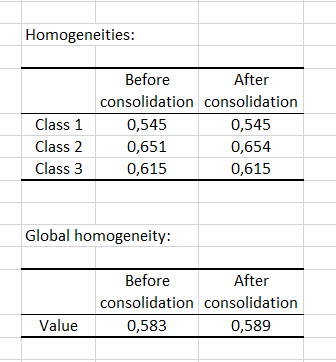
Finally, the homogeneity indexes of each class allow to assess the quality of the cluster analysis. The closer these indices are to 1, the more homogeneous the classes are. Here we see that class 1 is a little less homogeneous than the others. The global homogeneity, which is a weighted average of the homogeneity of each class, is rather correct. However, it could be improved with the addition of a "K+1" class.
Was this article useful?
- Yes
- No