Simulation model with scenario variables tutorial
This tutorial will help you to set up and run a simulation model with a scenario variable in Excel using the XLSTAT statistical software.
Simulation models
Simulation models allow us to obtain information such as the mean, median, or confidence intervals for variables that do not have an exact value, but for which we either know or assume a distribution. If some "result" variables depend on these "distributed" variables via known or assumed formulas, then the "result" variables also have a distribution. With Sim, you can define the distributions and then obtain an empirical distribution of the input and output variables and the corresponding statistics through simulations.
Simulation models are used in many fields, such as finance, insurance, medicine, oil and gas prospecting, accounting, and sales forecasting.
There are four elements to consider when constructing a simulation model:
-
Distributions are assigned to random variables. XLSTAT offers you a choice of more than 30 distributions to describe the uncertainty of the values that a variable can take. For example, you can choose a triangular distribution when you have a variable that you know can vary between two bounds, but with a value that is more likely (a mode). At each iteration of the the simulation model computation, a random draw is performed for each defined distribution.
-
Scenario variables allow you to include a quantity that is fixed in the simulation model, except during tornado analysis, where it can vary between two bounds.
-
Result variables correspond to the outputs of the model. They depend either directly or indirectly, via one or more Excel formulas, on the random variables to which distributions have been assigned and, if available, on the scenario variables. The goal of the simulation model calculation is to obtain the distribution of the result variables.
-
Statistics allow us to track a particular statistic for a result variable. For example, we might want to monitor the standard deviation of a result variable.
A correct model should contain at least one distribution and one result variable. Models can contain any number of these four elements. A model can be limited to a single Excel sheet or use an entire Excel folder.
Dataset to run a simulation including scenario variables and statistics
This tutorial uses the same model as in the first tutorial. It is extended by a scenario variable and a statistic.
Our simulation model is based on the sales and costs of a business. The benefit in this simple case is simply the difference between sales and costs. Based on historical data for costs and sales analyzed with the distribution fitting tool, we found that costs follow a normal distribution (mu=120, sigma=10). Sales also follow a normal distribution (mu=80, sigma=20) - See Fitting a distribution to a sample of data in Excel for more details.
We also assume that 80% of costs and 30% of sales depend on an exchange rate. The exchange rate is set to 1 at the beginning. During the tornado analysis, several scenarios are simulated with an exchange rate of 0.8 to 1.2.
The sales and costs are defined as in the tutorial Running a simple simulation model with XLSTAT. The formula of the benefit is more complicated because we now take into account the exchange rate: = (0.3 * E2 * B2 + 0.7 B2) -( 0.8 * E2 B3+ 0.2 * B3).
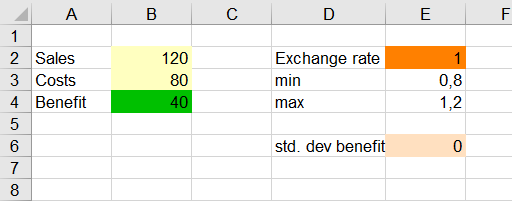 The scenario variable and statistic are now added to the model created on the Model sheet. Select cell E2, which contains the value of the exchange rate, as the active cell. The scenario variable will be defined there.
The scenario variable and statistic are now added to the model created on the Model sheet. Select cell E2, which contains the value of the exchange rate, as the active cell. The scenario variable will be defined there.
Setting up a scenario variable
-
Open XLSTAT.
-
Select the XLSTAT > Monte Carlo Simulations > Define a scenario variable command. The Define a scenario variable dialog box appears. Select the Excel cell that contains “exchange rate” to define the name of the variable.
-
For the lower limit, select the cell with the value 0.8 and for the upper limit, select the cell with the value 1.2. This will define the limits between which the exchange rate will vary.
-
Select the continuous data type because the exchange rate can take any value between 0.8 and 1.2.

-
Click on OK, and the corresponding XLSTAT_SimSVar function call will be inserted in the active cell.
Defining a statistic
-
Select the result cell located to the right of the cell with "std. dev benefit" to define a statistic and track the standard deviation of the result variable "benefit" during the simulation run. This statistic is calculated at each simulation iteration.
-
Select the XLSTAT > Monte Carlo Simulations > Define a statistic command.
-
The Define a statistic dialog box appears. Select the Excel cell with the name “std. dev benefit” (D6). Check the option Descriptive statistics and select standard deviation (n-1) in the list.

-
Click on OK, and the corresponding function call to XLSTAT_SimStat is inserted in the active cell (E6).
Running a simulation with scenario variables and statistics
The Monte Carlo simulation allows you to run the simulation step by step if you wish. This allows you to verify that your model behaves as expected. In this example, you can follow the evolution of the defined statistics step by step.
To initialize the simulation model and clear the information stored from a previous stepwise simulation, click the XLSTAT > Monte Carlo Simulations > Reinitialize the simulation model command.
You will see the results of the first simulation iteration in the cells for "Sales", "Costs" and "Benefit". The scenario variable is only used during the tornado analysis and does not change its value for now. The statistic is not calculated yet, because there must be at least two historical values to calculate the standard deviation.
To perform further simulation steps, select the command XLSTAT > Monte Carlo Simulations > Do a simulation step.
You can see how the standard deviation statistic converges quickly.
How to start the simulation run?
-
To start the simulation run, select the XLSTAT > Monte Carlo Simulations > Run command, or click the appropriate button of the Monte Carlo Simulations toolbar.
-
The Run dialog box appears. Set the number of simulations to 1000.

-
On the Outputs tab, enter the parameters of the Tornado and Spider Analysis.

-
The computation will start as soon as you click OK.
Interpreting the results of a simulation model with scenario variables and statistics
The first results are the same as the ones described in the first tutorial.
The Tornado and Spider analysis are not based on the iterations of the simulation, but on a point-by-point analysis of all input variables (random variables with distributions and scenario variables).
In the tornado analysis, for each outcome variable, each input random variable, and each scenario variable are examined one by one. We allow their value to vary between two bounds and record the value of the result variable to learn how each random and scenario variable affects the result variables. For a random variable, the values examined can be either around the median or around the standard value of the cell, with bounds defined by percentiles or deviation percentages. For a scenario variable, the analysis is performed between the two bounds specified when the variables were defined. The number of points is an option that can be changed by the user before running the simulation model.
In the tornado analysis, the results for the scenario variable are displayed. Its effects are as important as those of the other two variables "Costs" and "Sales".
Further details are visible in the spider diagram. The exchange rate is clearly negatively correlated. A rising exchange rate shrinks the benefit.
Finally, the details of the simulation are displayed. For each of the model variables "Costs", "Sales", "Benefit" and "std. dev benefit", the evolution at each iteration is displayed. We clearly see the evolution of the statistic and can conclude that the statistic quickly converges to 22 and then only oscillates around that value.
Was this article useful?
- Yes
- No