Multiple Lineare Regression in Excel - Anleitung
Dieses Tutorium wird Ihnen helfen, eine multiple lineare Regression in Excel mithilfe der XLSTAT Software einzurichten und zu interpretieren. Die lineare Regression basiert auf gewöhnlichen kleinsten Quadraten (OLS).
Sie sind nicht sicher, ob es sich hierbei um die Modellierungsfunktion handelt, nach der Sie suchen? Weitere Hinweise finden Sie hier.
Daten zum Ausführen einer multiplen linearen Regression
Die Daten stammen aus Lewis T. und Taylor L.R. (1967). Introduction to Experimental Ecology, New York: Academic Press, Inc.. Die Daten handeln von 237 Kindern, beschrieben durch ihr Geschlecht, Alter in Zoll (1 inch = 2.54 cm), und Gewicht in engl. Pfund (1 pound = 0.45 kg).
Die Methode der linearen Regression gehört zu einer größeren Modellfamilie namens GLM (Generalisierte Lineare Modelle), ebenso wie die ANOVA. Dieser Datensatz wird auch in den beiden Tutorials zur einfachen linearen Regression und ANCOVA verwendet.
Absicht dieses Tutoriums
Durch den Einsatz der multiplen linearen Regression soll ermittelt werden, wie das Gewicht der Kinder in Abhängigkeit der Größe und des Alters variiert und ob ein lineares Modell sinnvoll ist. Die Methode der linearen Regression gehört zu der großen Familie der GLM (Generalized Linear Models), ebenso wie die ANCOVA und ANOVA. Dieser Datensatz wird ebenfalls in beiden Tutorials zur einfachen linearen Regression und zur ANCOVA benutzt, mit der Größe, dem Alter und dem Geschlecht als erklärenden Variablen.
Einrichten einer multiplen linearen Regression
-
Öffnen Sie XLSTAT.
-
Wählen Sie im Menüband Modellierung von Daten / Lineare Regression.
-
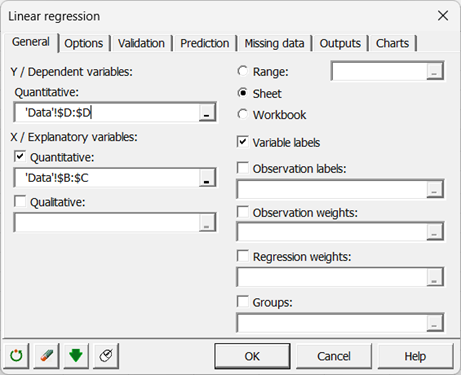
Wählen Sie die Daten auf dem Excel-Blatt aus. Die abhängige Variable (oder zu modellierende Variable) ist hier das "Gewicht". Die quantitativen erklärenden Variablen sind die "Größe" und das "Alter".
-
Da die Spaltenüberschrift für die Variablen bereits ausgewählt ist, lassen Sie die Option Variablenbezeichnungen aktiviert.
-
Gehen Sie zur Registerkarte Ausgaben und aktivieren Sie die Option Typ I/III SS, um die entsprechenden Ergebnisse anzuzeigen.
-
Klicken Sie auf OK, um die Berechnungen zu starten.
Interpretieren der Ergebnisse einer multiplen linearen Regression
Zur Erinnerung: Die multiple lineare Regression ermöglicht es Ihnen, eine Variable in Abhängigkeit von mehreren anderen vorherzusagen, basierend auf einer linearen Beziehung, die durch einen überwachten Lernalgorithmus abgeleitet wird. Wenn Sie eine lineare Beziehung nur zwischen zwei Variablen herstellen möchten, zögern Sie nicht, unser Tutorial zu konsultieren einfachen linearen Regression zur.
Falls Sie in den Optionen von XLSTAT die Option „Auswahl bestätigen lassen“ aktiviert haben, so bittet Sie XLSTAT die Anzahl der Zeilen und der Spalten der Auswahlen zu bestätigen. Die erste Tabelle zeigt die Koeffizienten der Anpassungsgüte des Modells an. Das R² (Determinationskoeffizient) gibt den Prozentsatz der Variabilität der abhängigen Variablen an, die durch die erklärende Variable beschrieben wird. Je näher R² bei 1 liegt, desto besser ist die Anpassung.
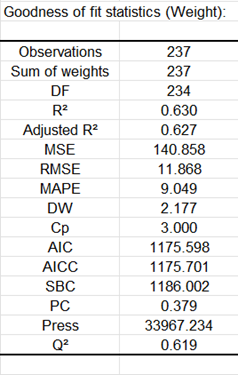
In diesem speziellen Fall werden 63 % der Variabilität des Gewichts durch die Größe und das Alter erklärt. Der Rest der Variabilität ist auf Effekte zurückzuführen (andere erklärende Variablen), die nicht in die Analyse eingeschlossen wurden.
Es ist wichtig die Ergebnisse der Varianzanalyse-Tabelle zu untersuchen (siehe unten). Diese Ergebnisse lassen uns entscheiden, ob die erklärenden Variablen eine signifikante Information (Nullhypothese H0) in das Modell einbringen oder nicht. Mit anderen Worten ausgedrückt, ist dies eine Art zu überprüfen, ob es Sinn macht den Mittelwert zu benutzen, um die gesamte Population zu beschreiben, oder ob die Information, die von der/den erklärenden Variable(n) eingebracht wurde, wertvoll ist.
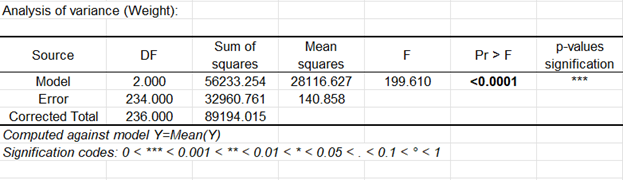
Fisher's F Test wird eingesetzt. Anhand der Tatsache, dass die Wahrscheinlichkeit die dem F value entspricht kleiner als 0.0001 ist, ist das Risiko kleiner als 0.01%, dass die Annahme der Nullhypothese (kein Einfluss der erklärenden Variablen) falsch ist. Daher kann man sicher schließen, dass die drei Variablen eine signifikante Information einbringen.
Die nächste Tabelle zeigt die Typ III SS an. Diese Ergebnisse bestimmen, ob eine Variable signifikante Information in das Modell einbringt oder nicht, wenn alle anderen Variablen schon im Modell vorhanden sind.
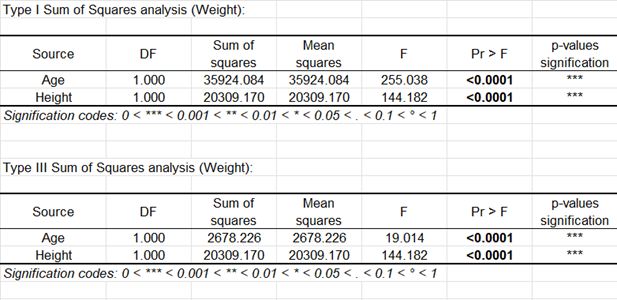
Die folgende Tabelle zeigt Modelldetails an. Diese Tabelle ist hilfreich, wenn Vorhersagen benötigt werden oder wenn Sie die Koeffizienten des Modells für eine vorgegebene Population mit denen für eine andere Population vergleichen möchten(Es kann zum Vergleich der Modelle für Mädchen und Jungen eingesetzt werden). Man kann sehen, dass das 95% Konfidenzintervall des Parameters der Variable Größe sehr eng ist, wobei der p-value für den Parameter Alter fast 0 ist. Dies zeigt an, dass der Effekt der Variable Alter kleiner als der Effekt der Variable Größe ist. Die Modellgleichung ist unter der Tabelle aufgeschrieben. Man stellt fest, dass für eine gegebene Größe, das Alter einen positiven Effekt auf das Gewicht hat. Wenn das Alter um einen Monat zunimmt, so steigt dass Gewicht um 0,2 Pfund.
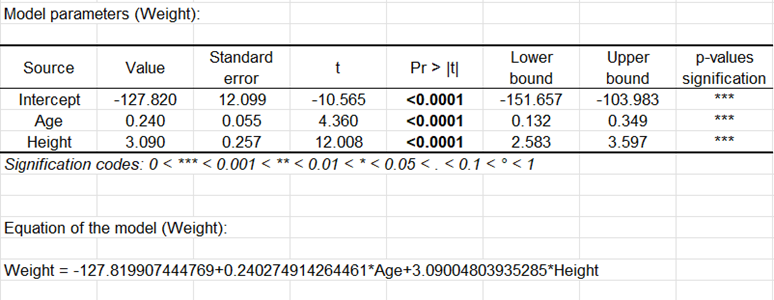
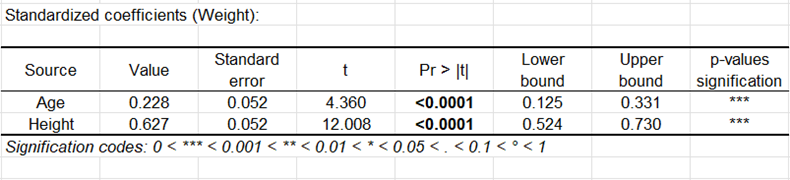
Die sich anschließende Tabelle und Diagramm entsprechen den standardisierten Regressionskoeffizienten (manchmal auch als Beta-Koeffizienten bezeichnet). Diese erlauben es den Einfluss und die Signifikanz der verschiedenen Variablen auf die abhängige Variable zu vergleichen.
Die nächste Tabelle zeigt die Residuen an. Dies ermöglicht es, jedes standardisiertes Residuum genauer zu betrachten. Diese Residuen gemäß der Annahme des linearen Regressionsmodells sollten normalverteilt sein. Dies bedeutet, dass 95% der Residuen im Intervall [-1.96, 1.96] liegen sollten. Alle Werte außerhalb des Intervalls sind potentielle Ausreißer oder lassen unterstellen, dass die Annahme der Normalität falsch ist. Wir benutzten XLSTATs DataFlagger um die Residuen außerhalb des Intervalls [-1.96, 1.96] hervorzuheben.
So kann man von den 237 15 Residuen finden, die außerhalb des Bereiches [-1.96, 1.96] liegen, was 6.3% anstatt 5% darstellt. Eine genauere Analyse der Residuen kann im Tutorial zur ANCOVA gefunden werden.
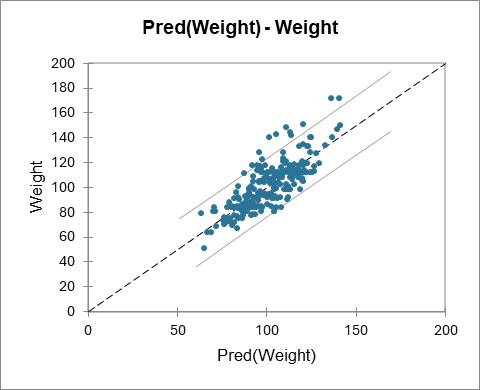
Das unten angezeigte Diagramm erlaubt es, die Vorhersagen und beobachteten Werte zu vergleichen.
Das Histogramm der Residuen erlaubt es rasch die Residuen zu sehen, die außerhalb des Bereichs [-2, 2] liegen.
Schlussfolgerung für diese multiple lineare Regression
Das Fazit ist, dass die Größe und Alter es erlauben 63 % der Variabilität des Gewichts zu erklären. Ein signifikanter Anteil an Information wird nicht durch das benutzte Regressionsmodell erklärt. Im Tutorial zur ANCOVA wird die Variable Geschlecht dem Modell hinzugefügt, um die Anpassungsgüte des Modells zu erhöhen.
War dieser Artikel nützlich?
- Ja
- Nein