Clasificación Ascendente Jerárquica (AHC) en Excel
Este tutorial muestra cómo configurar e interpretar una Clasificación ascendente jerárquica (AHC) en Excel usando el software XLSTAT.
Datos para ejecutar una clasificación ascendente jerárquica (AHC) en XLSTAT
Los datos proceden del US Census Bureau. Corresponden a la medición de parámetros demográficos en 51 Estados de los Estados-Unidos en 2000 y 2001. En el marco de este tutorial, solo los datos del año 2001 fueron conservados, y con el fin de suprimir los efectos de escala, las variables iniciales fueron convertidas en àndices por 1000 habitantes.
Objetivo de este tutorial
El objetivo aquà es de crear grupos homogéneos de estados. Estos datos son también utilizados por el tutorial del análisis de Componentes Principales (ACP).
Configuración de una clasificación ascendente jerárquica
-
Una vez que XLSTAT éste activado, haga clic en el menú XLSTAT/ Análisis de datos/ Clasificación Ascendente Jerárquica (AHC).
-
Una vez el botón pulsado, el cuadro de diálogo correspondiente a la AHC aparece. Puede entonces seleccionar los datos en la hoja Excel.
Hay varias manera de seleccionar los datos en el cuadro de diálogo de XLSTAT (ver el tutorial relacionado).
-
En el ejemplo estudiado acà los datos empiezan desde la primera linea; Es entonces más rápido elegir el modo de selección por columnas. Por esta razón, en el cuadro de diálogo a continuación las selecciones aparecen en forma de columnas.
-
La variable "Población total" no fue seleccionada ya que solos los aspectos dinámicos de la población nos interesa aquà. La última columna no fue seleccionada tampoco, ya que hemos visto con el análisis de componentes principales que las dos últimas columnas están perfectamente correlacionadas.
-
La opción "Etiquetas de las columnas" es activada, ya que la primera linea de datos incluye el nombre de las variables.
-
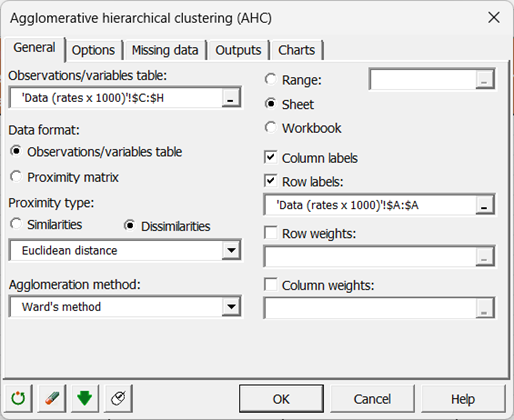
Usamos la distancia euclídea y el método de Ward como metodo de aglomeración.
-
La opción Centrar/Reducir es activada de manera a evitar que algunas variables no influyen demasiado sobre el resultado con problemas de escala.
-
La opción "Truncamiento" es activada para obtener el dendrograma (o árbol de clasificación) truncado con un numero de grupos definido por el indice de Hartigan. Este indice le permite comparar la cualidad de varios grupos dependiendo de un número definido de grupos.
-
Los cálculos empiezan cuando haga clic en el botón OK.
Interpretación de los resultados de una clasificación ascendente jerárquica
El primer resultado es el gráfico de barras de los niveles. Su forma proporciona informaciones sobre la estructura de los datos. Cuando son observadas unas variaciones importantes, tenemos una agregación de estructuras homogéneas.
El gráfico a continuación es el dendrograma. Representa cómo funciona el algoritmo para agrupar las observaciones, y luego los subgrupos de observaciones. Como puedes ver, el algoritmo ha agrupado con éxito todas las observaciones.
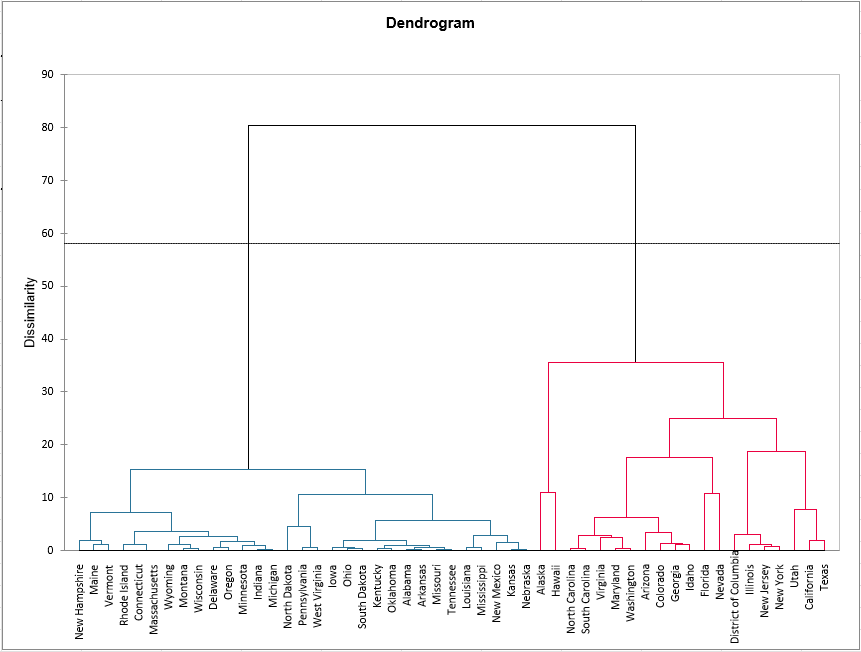
La línea de puntos representa el truncamiento y permite visualizar que dos grupos homogéneos fueron identificados. El primer grupo (mostrado en color azul) es más homogéneo que el segundo (es más plano en el dendrograma). Esto se confirma cuando se observa la varianza dentro de la clase. Es mucho más alta para el segundo grupo que para el primero. La tabla siguiente nos explica porqué hemos obtenido 2 grupos.
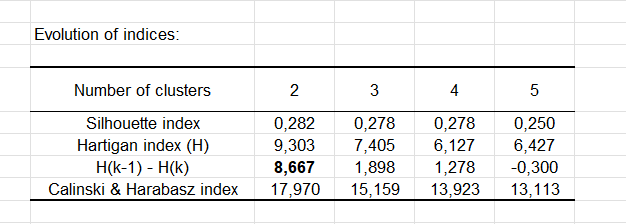
De hecho, la tabla nos muestra la evolución del indice de Silueta, del indice de Hartigan y del indice de Calinski & Harabasz, en cada grupo.
En este caso, observamos las segunda y tercera líneas. La segunda línea nos muestra la evolucion del indice de Hartigan y la tercera muestra la evolución de la diferencia entre el indice de una clusterización con k grupos (o clusters) y otra con k-1 grupos. El número con la mayor diferencia (en negrita) indica cuantos grupos tenemos que guardar (aqui, 2).
La siguiente tabla muestra los estados clasificados en cada grupo. La Varianza dentro de los grupos nos indica que el primer grupo (a la izquierda del dendrograma) es mas homogéneo que el segundo porqué la varianza es mayor en el segundo ( a la derecha).
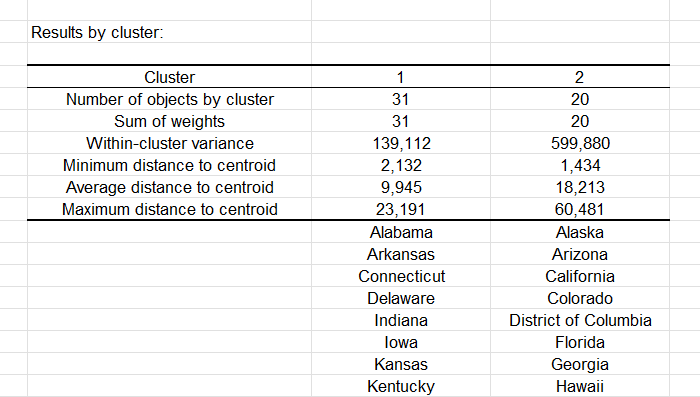
En la hoja de resultados se muestra una tabla con la identificación de la clase para cada Estado. A continuación se muestra una muestra. Esta tabla es útil, ya que puede fusionarse con la tabla inicial para análisis posteriores, por ejemplo, el análisis discriminante o el trazado de coordenadas paralelas.
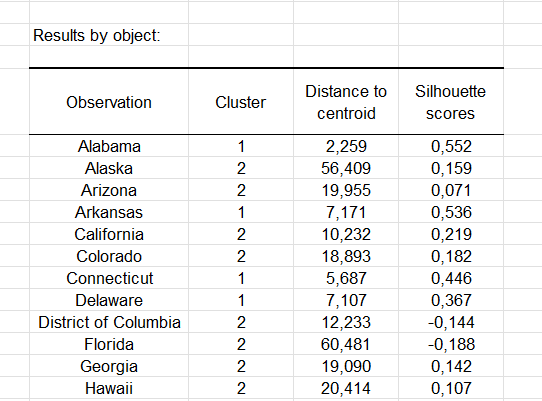
Las Puntuaciones de silueta de cada observación también pueden representarse. Si la puntuacion se acerca de 1, la observación se situa el el grupo correcto.
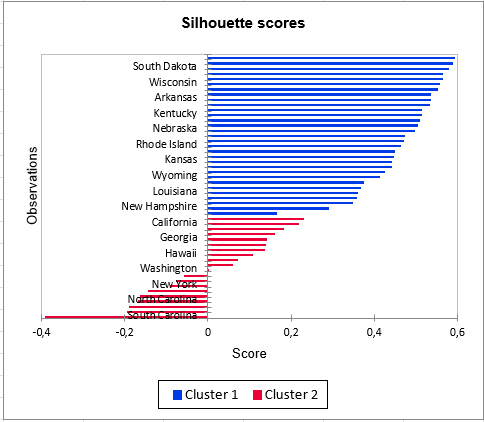
Para terminar, las puntuaciones pueden representarse ordenadas en un gráfico para cada grupo, para evaluar la cualidad de la clusterización obtenida. Los indices negativos de la clase 2 muestran una vez mas que esta clase es menos homogénea que la clase 1.
Conclusión sobre la Clasificación Ascendente Jerárquica
Hemos realizado una Clasificación Ascendente Jerárquica y gracias al indice de Hartigan hemos separado los estados en dos grupos. Sin embargo, uno de los grupos es mas homogéneo que el otro. Es posible obtener una mejor clusterización con dos grupos homogéneos usando la consolidación del algoritmo k-means. Para hacerlo, puede activar la consolidación el la pestaña Opciones.
Nota: si no se usa la distancia euclídea y el metodo de agrupamiento no es el de Ward, adaptaciones del indice de Hartigan o de Calinski & Harabasz se proponen por nuestros equipos para ayudarle a elegir el mejor numero de grupos.
Este video muestra cómo hacer este tutorial.

¿Ha sido útil este artículo?
- Sí
- No