Classification de tableaux avec CLUSTATIS dans Excel
Ce tutoriel explique comment réaliser et interpréter une classification de tableaux de données grâce à la méthode CLUSTATIS avec Excel en utilisant XLSTAT.
Jeu de données à analyser avec CLUSTATIS
Les données proviennent d’une épreuve projective mapping/Napping réalisé à Rennes par AGROCAMPUS OUEST. 24 sujets ont placé 8 smoothies sur une nappe. Ainsi, une personne trouvant deux produits similaires les placera proches sur la nappe, et les produits perçus différemment seront éloignés. L’épreuve projective mapping (ou Napping) donne ainsi une notion de distance entre les produits. Pour l'analyse des données, les coordonnées de chaque nappe sont récupérées. Le fichier original peut être obtenu avec le package R SensoMineR. Ce jeu de données est également utilisé dans notre tutoriel sur STATIS, afin d’analyser directement les smoothies sans classification des sujets.
But de ce tutoriel
Le but ici est de réaliser une analyse des données en trois temps : 1. Segmenter les tableaux (nommés ici configurations) de données, c’est-à-dire ici les sujets, en fonction de leurs perceptions des produits. Des classes les plus homogènes possibles vont être constituées grâce à la méthode CLUSTATIS. 2. Analyser chaque classe de sujets par la méthode STATIS afin de déterminer les différences de perceptions des smoothies entre les classes. 3. Déterminer des indices de qualité de la classification.
Nous utiliserons la fonction CLUSTATIS de XLSTAT pour faire cette analyse. Cet outil nous permettra de réaliser les trois objectifs définis ci-dessus.
Paramétrer la boîte de dialogue de CLUSTATIS
Une fois XLSTAT lancé, sélectionnez le menu XLSTAT / Fonctions avancées / Analyse de données sensorielles/ CLUSTATIS.

La boîte de dialogue CLUSTATIS apparaît.
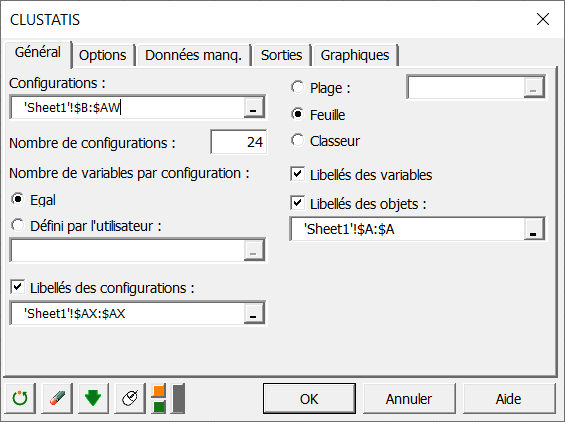
Nous pouvons alors sélectionner les configurations (une configuration correspond ici à l'ensemble des coordonnées des produits données par un sujet). Le nombre de configurations doit ensuite être saisi. Il y a ici 24 tableaux contigus correspondant aux 24 sujets.
Comme les 24 configurations ont chacune deux variables, l'option Egal est choisie pour le nombre de variables. Lorsque le nombre de variables varie pour les différentes configurations, il faut sélectionner une colonne contenant le nombre de variables des différentes configurations.
Les étiquettes des configurations et des produits sont aussi sélectionnées donc il faut sélectionner les options Libellés des configurations et Libellés des objets (dans notre cas les smoothies).
Dans l’onglet Options, nous avons choisi de ne pas réduire les variables, puisqu’à l’intérieur de chaque configuration, toutes les variables sont sur la même échelle. Nous avons décidé de laisser le choix du nombre de classes automatique, et d’appliquer une consolidation des classes obtenues par l’algorithme hiérarchique afin obtenir une classification plus précise.
Dans l’onglet Graphiques, si vous sélectionnez la case Graphiques sur deux axes, vous aurez automatiquement la représentation des différentes cartes sur les 2 premiers axes factoriels. Si vous le décochez, une fenêtre s’ouvrira alors et vous pourrez choisir vos axes pour chaque classe.
Interpréter les résultats d’une analyse CLUSTATIS
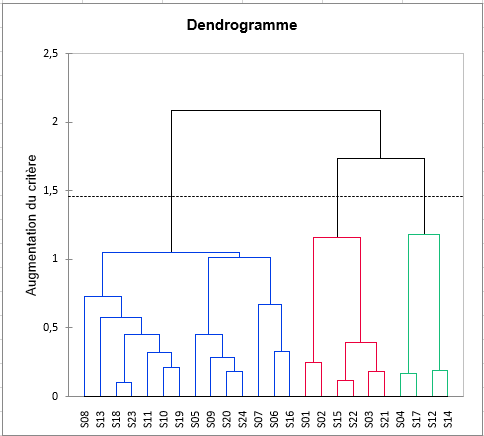
Le graphique ci-dessous est le dendrogramme. Il représente de manière claire la façon dont l'algorithme procède pour regrouper les configurations puis les groupes de configurations. L'algorithme a progressivement regroupé toutes les configurations (sujets). La ligne en pointillé représente la troncature et permet de visualiser que trois classes ont été identifiées.
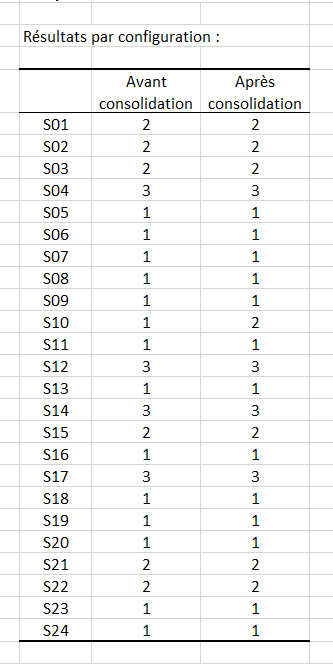
Le tableau suivant indique les classes des différentes configurations avant et après consolidation. Il apparaît que seul le sujet 10 a changé de classe avec la consolidation.
Viens ensuite l’analyse de chacune des classes construites. La représentation des objets (smoothies ici) dans chaque classe montre des différences de perception entre les classes de sujets, notamment concernant le smoothie Carrefour_SB. En effet, ce dernier est placé avec le smoothie Innocent_SB par les sujets dans la classe 1, avec Innocent_PBC et Casino_PBC par les sujets dans la classe 2, et avec Carrefour_MP par ceux de la classe 3.
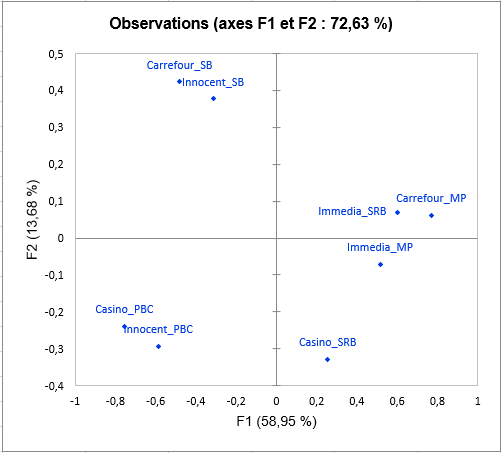
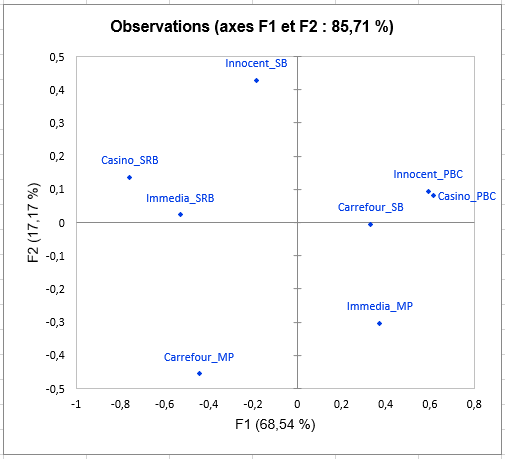
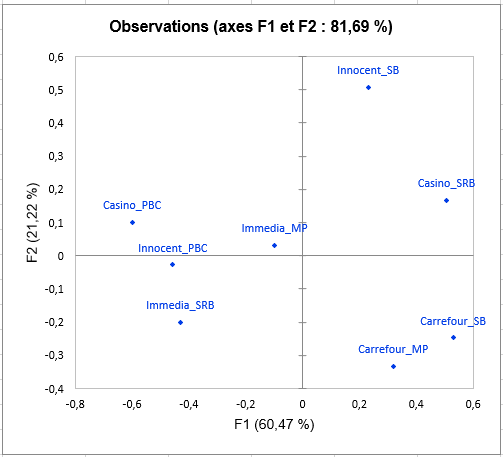
Le graphique suivant donne des indications sur la proximité des configurations et du consensus de la classe dans laquelle elles sont placées. Ces proximités sont représentées par le coefficient RV, qui est un indice de similarité entre 0 et 1. Dans la classe 2, nous pouvons observer que le sujet 2 est bien plus éloigné du consensus que les autres, ce qui signifie qu’il ne se conforme pas bien à la classe. Sa perception est différente de toutes les classes (puisqu’il a été placé dans la classe qui lui correspond le mieux par l’algorithme). Ce genre de problématique peuvent être résolues par l’ajout de la classe « K+1 » dans l’onglet Options, qui est une classe supplémentaire prévue pour mettre de côté les configurations atypiques.
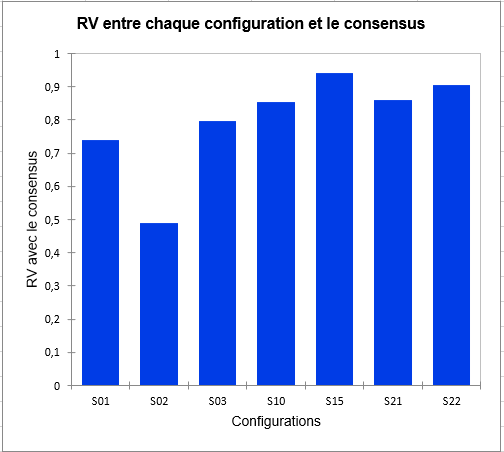
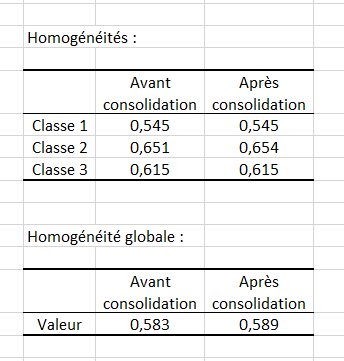
Enfin, les indices d’homogénéité de chaque classe permettent d’évaluer la qualité de la classification. Plus ces indices sont proches de 1, plus les classes sont homogènes. Ici, nous voyons que la classe 1 est un peu moins homogène que les autres. L’homogénéité globale, qui est une moyenne pondérée des homogénéités de chaque classe, est plutôt correcte. Cependant, cette dernière pourrait être améliorée avec l’ajout d’une classe « K+1 ».
Cet article vous a t-il été utile ?
- Oui
- Non