Qu’est-ce que le Machine Learning Supervisé ?
Cet article est une introduction au Machine Learning Supervisé, qui permet d’optimiser des algorithmes dans un but prédictif.
Qu’est-ce que le Machine Learning ou Apprentissage Automatique ?
Le Machine Learning est un ensemble de techniques de calcul ou algorithmes qui permettent à l’ordinateur d’apprendre des tâches à partir de patterns trouvés dans les données. Exemple, recommander des articles en ligne sur la base des données de comportement d'achat passées. Le Machine Learning fait partie de l'intelligence artificielle, en ce sens qu'il imite la faculté cognitive d’apprentissage des humains.
En français : Apprentissage Automatique.
Quelle est la différence entre Machine Learning Supervisé et non supervisé ?
Le Machine Learning non supervisé et supervisé sont les deux branches du Machine Learning les plus utilisées.
Machine Learning non supervisé
Le Machine Learning non supervisé comprend des méthodes permettant de cartographier des consommateurs, des clients, des patients, des échantillons environnementaux ou tout autre ensemble d'objets, ou de les classer en groupes d'objets similaires (clustering). Il n’y a pas de variable à prédire. Les outils courants de Machine Learning non supervisé comprennent notamment la classification k-means, la Classification Ascendante Hiérarchique, l’Analyse en Composantes Principales et plus encore. Ce guide vous aidera à choisir une méthode appropriée.
Machine Learning supervisé
Le Machine Learning supervisé est un ensemble d'algorithmes qui permettent à l'ordinateur d'apprendre à prédire un résultat à partir d'un ensemble de prédicteurs. Le jeu de données doit inclure une variable dépendante aussi appelée variable Y. Il s’agit de la variable que l’ordinateur devra apprendre à prédire. Les autres variables sont les Prédicteurs, également appelés variables X et utilisées par l'ordinateur pour construire des modèles permettant de prédire Y.
Quand Y est une variable qualitative ( = catégorielle), nous travaillons sur une problématique de classification. Quand Y est quantitative, il s’agit d’une problématique de régression.
Machine Learning supervisé : exemples de problématiques de classification
E-Commerce
L'ordinateur apprend à recommander des articles aux clients sur la base de données antérieures, notamment l'historique des achats et les profils d'autres clients.
Détection de fraude (assurance)
L'ordinateur apprend à détecter des fraudes à partir d’une base de données de comportement passées, liées à des cas confirmés frauduleux ou non-frauduleux.
Médecine
L'ordinateur apprend à prédire la prédisposition de patients à une maladie sur la base de données génétiques associées à des cas de patients confirmés malades ou sains.
Web Marketing
L'ordinateur apprend à prédire le risque de désinscription de clients (churn) en fonction des données de comportement passées.
Industrie
L'ordinateur apprend à prédire une défaillance future sur une chaîne de production en fonction des données de défaillance passées associées à différents signaux. Cela permet aux ingénieurs et techniciens d'intervenir suffisamment tôt sur la chaîne pour éviter la panne. C'est ce qu'on appelle la maintenance prédictive, composante majeure de l'industrie 4.0.
Machine Learning supervisé : exemples de problématiques de régression
Finance
L'ordinateur apprend à prédire le prix de propriétés immobilières en fonction des caractéristiques et du prix de vente d’autres propriétés vendues récemment dans la région.
Quel algorithme de Machine Learning supervisé choisir ?
Comme le montre la grille d'algorithmes de cet article, il existe de nombreuses options dans chaque situation. Quel algorithme choisir ?
De plus, chaque algorithme peut lui-même être calibré de différentes manières via des hyperparamètres. Quelle calibration choisir ?
La réponse est qu'il n'y a pas de combinaison unique parfaite algorithme / calibration qui surpasse systématiquement toutes les autres combinaisons. Aujourd'hui, le data scientist teste les performances de différentes calibrations de différents algorithmes sur les données. Au bout du compte, l'algorithme avec la calibration qui affiche les meilleures performances est conservé pour prédire.
Comment mesurer la performance d’un algorithme de Machine Learning supervisé ?
Validation croisée
La performance d'un algorithme de Machine Learning Supervisé est mesurée par validation croisée. Le principe est de construire un modèle prédictif et de le tester sur des données qu'il n'a jamais vues. Ceci imite le monde réel où le modèle sera déployé et utilisé comme outil prédictif.
Les données sont divisées en deux ensembles d'observations : l’échantillon d’apprentissage ( = entraînement), de taille généralement plus importante, et l’échantillon test. L'ordinateur utilise l'échantillon d'apprentissage pour construire un modèle prédictif. Les performances prédictives du modèle sont mises à l'épreuve avec l'échantillon test. Le modèle prédit les résultats Y sur la base des données X de l'échantillon test. Si les prédictions et les données Y réelles ( = observées) sont proches, alors l'algorithme a une bonne performance. Il existe des indices qui mesurent cette performance.
La performance prédictive est également mesurée sur l’échantillon d’apprentissage. Ceci est utile pour évaluer la variance du modèle (voir plus loin).
Indices de performance pour les problématiques de classification
Dans les problématiques de classification, la plupart des indices de performance sont calculés à partir d'une matrice de confusion. Cette matrice affiche le nombre de succès et d'échecs de prédiction pour chaque catégorie de la variable Y. Pour une variable Y binaire (survie / mort, fraude oui / non…), la matrice de confusion comporte quatre cellules. Dans la matrice suivante, les deux catégories sont désignées par 1 et 0.
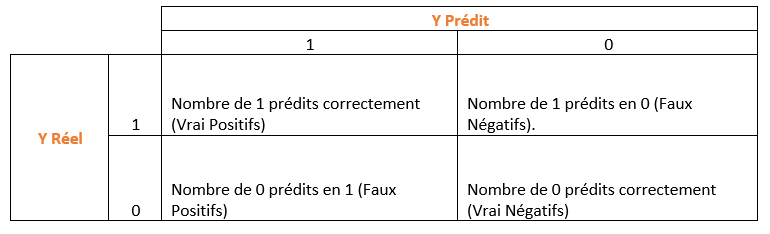 L’indice le plus intuitif que nous pouvons calculer à partir de cette matrice est la proportion de prédictions correctes (Accuracy en anglais) :
L’indice le plus intuitif que nous pouvons calculer à partir de cette matrice est la proportion de prédictions correctes (Accuracy en anglais) : 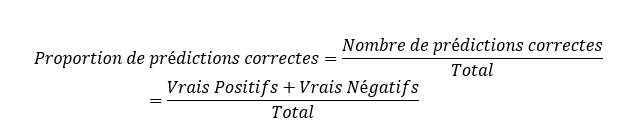
Cet indice n'est pas fiable en cas de déséquilibre important entre les catégories de Y dans les données. Par exemple, lorsque l'algorithme apprend à détecter une fraude, les données d'entrée contiennent souvent beaucoup plus de cas historiques non frauduleux que de cas frauduleux. D'autres indices peuvent être utilisés en cas de déséquilibre de classe. Par exemple, l'indice d’Aire Sous la Courbe (AUC) calculé à partir d’une courbe ROC.
D'autres indices tels que le recall, la sensibilité ou la spécificité peuvent être plus appropriés dans des situations spécifiques.
Indices de performance pour les problématiques de régression
Dans les problématiques de régression, la racine de l'erreur quadratique moyenne (RMCE) est couramment utilisée. Elle mesure racine carrée des différences quadratiques moyennes entre les Y observés et prédits. Cet indice est à minimiser.
Performance des modèles : évaluer le biais et la variance
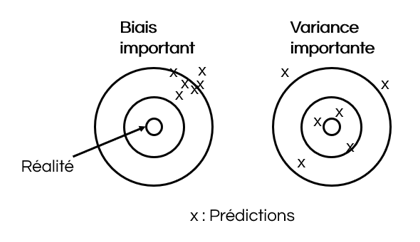
Un modèle performant a un biais faible et une variance faible.
Le biais mesure le décalage entre les Y réels et les prédictions d'un modèle de Machine Learning. Un modèle avec un biais élevé est peut-être trop simple ou n'est pas suffisamment entraîné. Le biais se traduit par une mauvaise performance prédictive à la fois sur les échantillons d'apprentissage et de test.
La variance mesure le bruit des prédictions. Un modèle avec une variance élevée est trop ajusté aux données d’entraînement et se généralise mal sur de nouvelles données. La variance se traduit par une performance bien meilleure de l’algorithme sur l’échantillon d’apprentissage par rapport à sa performance sur l’échantillon test.
Quelles sont les étapes principales d’un processus de Machine Learning supervisé ?
Poser la question et fixer des objectifs de performance
Il est important de définir précisément la question. Ensuite, il est utile de fixer des objectifs de performance qu’il faut essayer d’atteindre. Par exemple, atteindre une proportion de prédictions correctes de 0.95 dans une tâche de classification.
Un ensemble d'algorithmes candidats est ensuite sélectionné. Ce guide compare plusieurs algorithmes disponibles dans XLSTAT.
Prétraiter les données
Le prétraitement des données est une étape critique du processus de Machine Learning supervisé. Il inclut le nettoyage des données, le traitement des données manquantes, la création de prédicteurs informatifs (Feature Engineering, exemple), le traitement du déséquilibre de classes dans les problématiques de classification, le traitement la multicolinéarité entre les prédicteurs…
Sélectionner l’algorithme calibré le plus performant
Utiliser la validation croisée pour comparer les performances de différents algorithmes avec des hyperparamètres calibrés de différentes manières. Conserver le cas le plus performant en termes de biais et de variance.
Utiliser le modèle pour prédire
Le modèle optimal peut ensuite être utilisé pour prédire des résultats Y dans le monde réel : articles à recommander, risque de fraude, risque de maladie…
Réévaluer les performances du modèle avec des cas récents
Il est recommandé d'évaluer régulièrement la qualité prédictive du modèle en le testant sur des cas récents liées à des valeurs Y connues. Si une diminution de la qualité du modèle est avérée, il est conseillé d'envisager une nouvelle recherche de modèle optimal en utilisant la validation croisée.
Cet article vous a t-il été utile ?
- Oui
- Non