Diagnostics d’influence pour la régression linéaire dans Excel
Ce tutoriel explique comment calculer et interpréter des diagnostics d’influence pour une régression linéaire multiple dans Excel avec le logiciel XLSTAT.
Jeu de données pour réaliser un diagnostic d’influence d’une régression linéaire multiple
Les données proviennent de Lewis T. and Taylor L.R. (1967). Introduction to Experimental Ecology, New York: Academic Press, Inc.. Elles concernent 237 enfants, décrits par leur sexe, leur âge en mois, leur taille en inch (1 inch = 2.54 cm), et leur poids en livres (1 livre = 0.45 kg).
But de ce tutoriel
Avant de procéder à une modélisation statistique de ses données, on cherche en général à identifier les observations correspondantes à des valeurs extrêmes sur les variables (outliers) afin d’écarter ces observations des analyses. Cependant, ces procédures ne donnent pas d’indication sur l’influence qu’exercent ces observations sur l’estimation des paramètres. En effet, il peut être intéressant d’identifier les observations qui influencent le plus fortement l’estimation des paramètres du modèle pour juger de la pertinence d’un tel modèle sur l’ensemble du jeu de données. Nous allons calculer des diagnostics d’influence comme DFFits et DFBetas.
Paramétrer une régression linéaire multiple avec des diagnostics d’influence
Une fois XLSTAT lancé, sélectionnez le menu Modélisation des données / Régression linéaire.
Une fois le bouton cliqué, la boîte de dialogue correspondant à la régression apparaît.
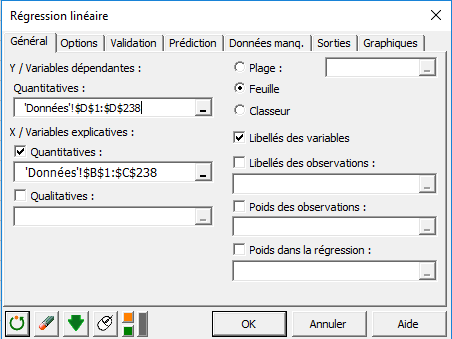
Dans l'onglet Général, vous pouvez alors sélectionner les données sur la feuille Excel.
La Variable dépendante correspond à la variable expliquée (ou variable à modéliser), qui est dans ce cas précis le "poids".
Les variables quantitatives explicatives sont ici la "taille" et l'"âge". On veut ici expliquer la variabilité du poids par celle de la taille et de l'âge.
L'option Libellés des variables est laissée activée car la première ligne des colonnes comprend le nom des variables.
Pour voir le tutoriel expliquant en détail comment paramétrer une régression linéaire multiple dans Excel grâce à XLSTAT, cliquez-ici.
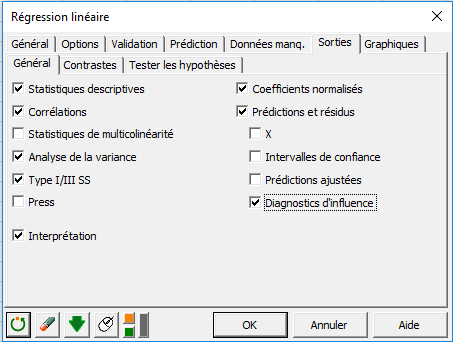
Dans l'onglet Sorties, sélectionnez l’option Prédictions et résidus ainsi que Diagnostics d’influence afin de générer l’affichage de plusieurs indicateurs.
Interpréter les résultats du diagnostic d’influence.
Plusieurs indicateurs sont calculés. Parmi ceux qui nous intéressent, on trouve Leverage, la distance de Mahalanobis, le CovRatio, le DFFits et les DFBeta. La plupart de ces indicateurs mesurent des différences entre les modèles incluant ou non la ième observation (écarts de prédictions, d’estimation des paramètres, de matrices de variances-covariances…)
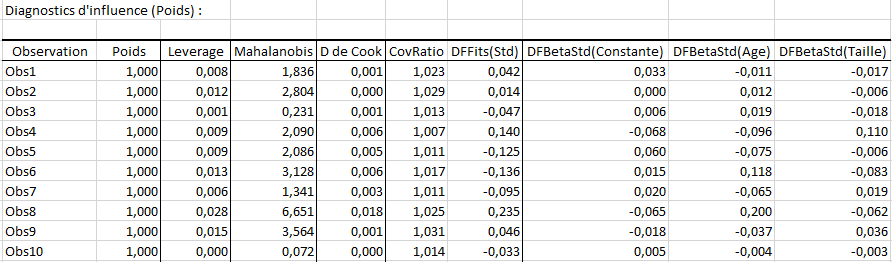
Nous allons axer notre analyse sur l’interprétation des DFFits et DFBetas standardisés.
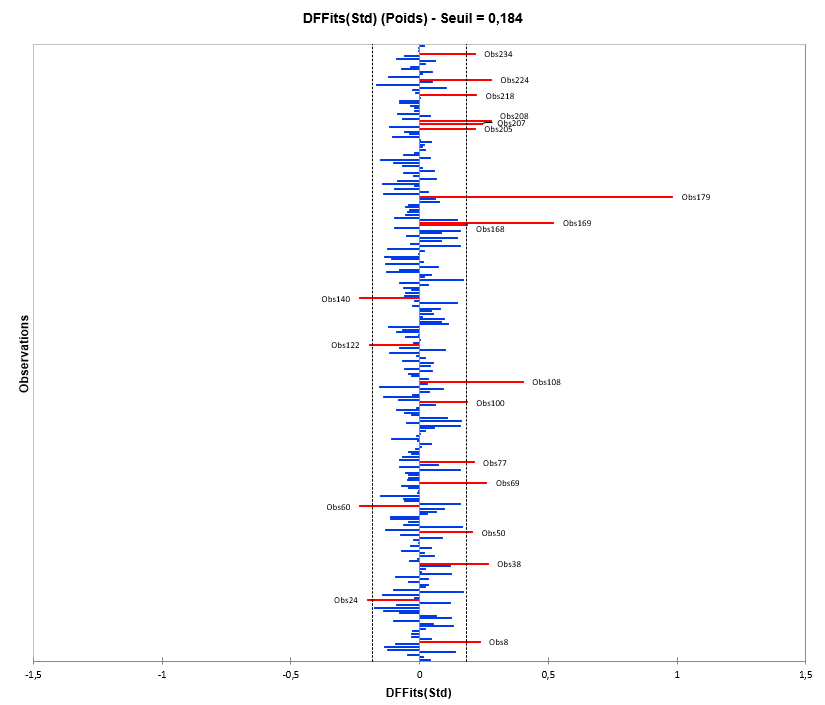
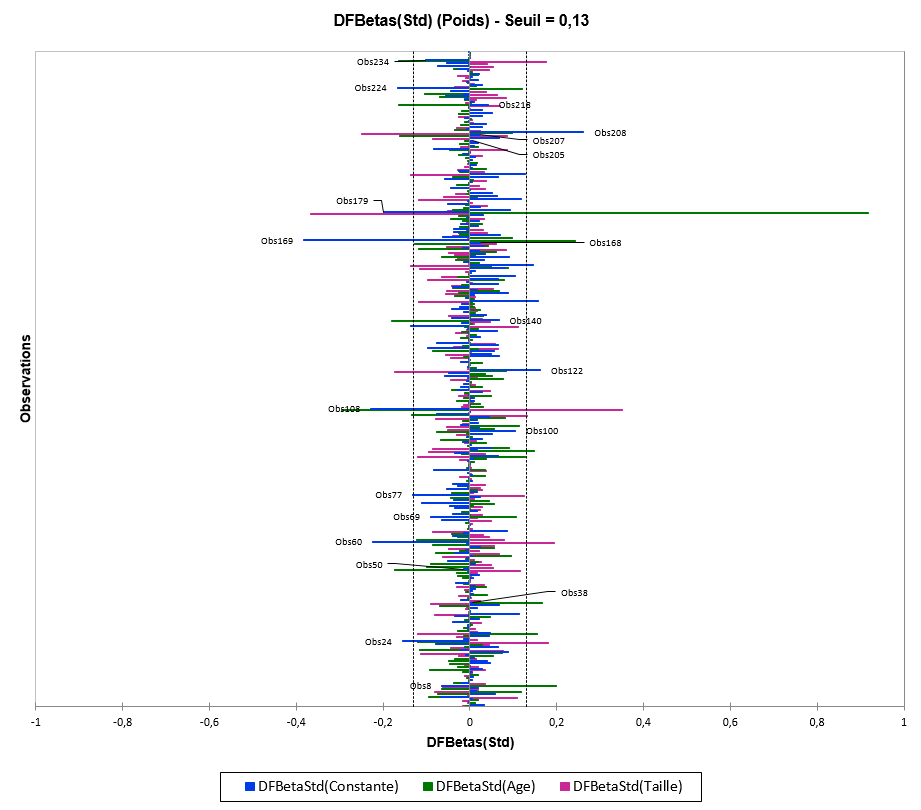
Ici, on observe une grande influence de l’observation 179 sur l’estimation des paramètres et sur les prédictions, et, dans une moindre mesure, des observations 8, 24, 38, 50, 60, 69, 77, 100, 108, 122, 010, 168, 169, 205, 207, 208, 218, 224 et 234. L’individu 179 mesure 67.5 pouces (170 cm) pour 171.5 livres (77kg). En y regardant de plus près, cet individu a 20 ans, contrairement aux autres enfant qui ont en moyenne entre 13 et 14 ans. Le rapport poids/taille de cet individu est de 2.5 contre 1.65 en moyenne pour cet échantillon. Cet individu influence donc énormément cette modélisation, on peut maintenant décider de le retirer ou non de l’étude.
On peut noter que cet individu influence tout particulièrement l’estimation du paramètre « Age ». En effet, son âge est bien plus écarté des autres enfants interrogés que sa taille.
Cet article vous a t-il été utile ?
- Oui
- Non