Modèle Additif Généralisé (GAM) dans Excel
Ce tutoriel vous guidera dans l’implémentation et l’interprétation d’un Modèle Additif Généralisé (MAG ou GAM) dans Excel avec XLSTAT-R.
Qu’est-ce qu’un Modèle Additif Généralisé ?
Les Modèles Additifs Généralisés (ou GAM) permettent de modéliser une variable à expliquer avec des fonctions de lissage non-linéaires des prédicteurs. Les splines cubiques font partie des fonctions non-linéaires souvent utilisées dans ce contexte. La fonction GAM développée dans XLSTAT-R appelle la fonction gam de la librairie mgcv dans R (Simon Wood).
Jeu de données pour exécuter un Modèle Additif Généralisé dans XLSTAT-R
Un classeur Excel avec les données et les résultats peut être téléchargé en cliquant sur le lien au-dessus.
Les données sont un extrait du jeu de données Wine Quality dataset (P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 200). Le jeu de données comprend les propriétés physicochimiques d’échantillons de vin ainsi que des scores de qualité associés. Les scores varient de 0 (très mauvais) à 10 (très bon). Seuls les échantillons de vin rouge, et les variables Densite, pH, Sulfates, Alcool et Score ont été retenus pour ce tutoriel.
L’objectif est d’étudier les effets non-linéaires des quatre variables physicochimiques sur les scores de qualité grâce à un Modèle Additif Généralisé.
Paramétrer un Modèle Additif Généralisé avec XLSTAT-R
Ouvrez XLSTAT-R / gam / Generalized additive models(gam)
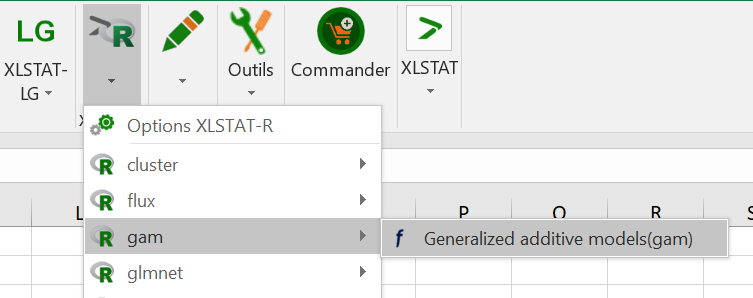 Dans l’onglet Général, sélectionnez les scores de qualité en tant que variable dépendante. La variable score est numérique, donc sélectionnez Gaussian dans la liste family.
Sélectionnez toutes les variables physicochimiques dans le champ variables explicatives quantitatives.
Dans l’onglet Général, sélectionnez les scores de qualité en tant que variable dépendante. La variable score est numérique, donc sélectionnez Gaussian dans la liste family.
Sélectionnez toutes les variables physicochimiques dans le champ variables explicatives quantitatives.
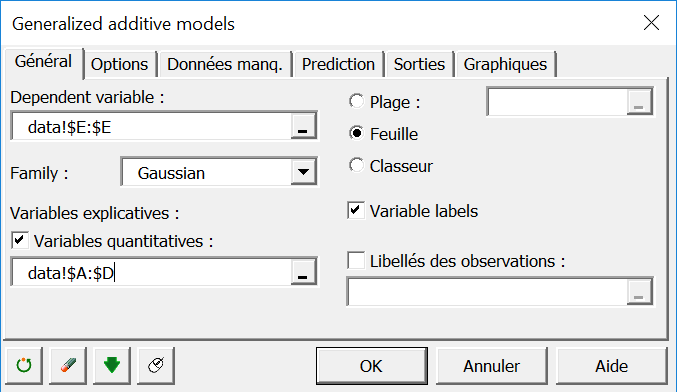 Dans l’onglet Options, sélectionnez le lisseur Cubic Spline (Choose smoother). XLSTAT-R génèrera automatiquement un modèle GAM en utilisant des paramètres par défaut. Comme la spécification de modèles GAM peut s’avérer assez complexe, XLSTAT-R offre à l’utilisateur l’option d’entrer son propre modèle GAM écrit en syntaxe R et respectant les spécifications de la fonction gam (option Self-defined function). Si vous optez pour cette option, assurez-vous d’appeler les variables par leurs noms et de respecter la casse (majuscule / minuscule). Voici un exemple pouvant fonctionner sur les données du tutoriel : score~s(pH,alcool,k=3)+s(densite)+s(sulfates)
Dans l’onglet Options, sélectionnez le lisseur Cubic Spline (Choose smoother). XLSTAT-R génèrera automatiquement un modèle GAM en utilisant des paramètres par défaut. Comme la spécification de modèles GAM peut s’avérer assez complexe, XLSTAT-R offre à l’utilisateur l’option d’entrer son propre modèle GAM écrit en syntaxe R et respectant les spécifications de la fonction gam (option Self-defined function). Si vous optez pour cette option, assurez-vous d’appeler les variables par leurs noms et de respecter la casse (majuscule / minuscule). Voici un exemple pouvant fonctionner sur les données du tutoriel : score~s(pH,alcool,k=3)+s(densite)+s(sulfates)
Si vous entrez une fonction personnalisée, le choix fait dans Choose smoother est ignoré.
Il est possible de pénaliser les estimations de paramètres (Add extra penalty) pour faire en sorte que certains paramètres s’annulent.
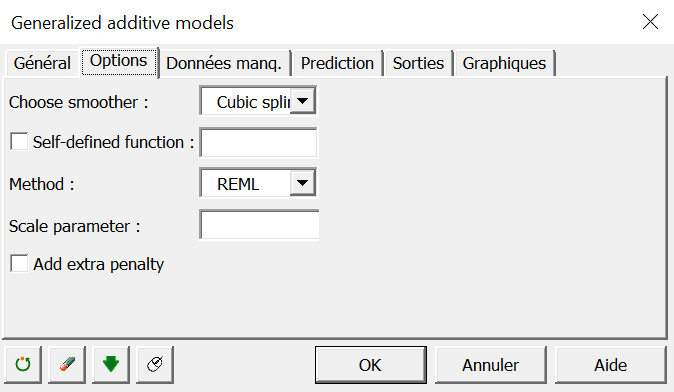 Sélectionnez toutes les sorties à l’exception des prédictions, vu qu’aucune prédiction n’a été paramétrée dans l’onglet Prédictions.
Sélectionnez toutes les sorties à l’exception des prédictions, vu qu’aucune prédiction n’a été paramétrée dans l’onglet Prédictions.
Cliquez OK pour lancer les calculs.
Interprétation des résultats d’un Modèle Additif Généralisé
L’AIC et le R² du modèle sont affichés en premier :
 Les termes paramétriques (parametric coefficients) et de lissage (smoothed terms), ainsi que les p-values associées peuvent par la suite être étudiés :
Les termes paramétriques (parametric coefficients) et de lissage (smoothed terms), ainsi que les p-values associées peuvent par la suite être étudiés :
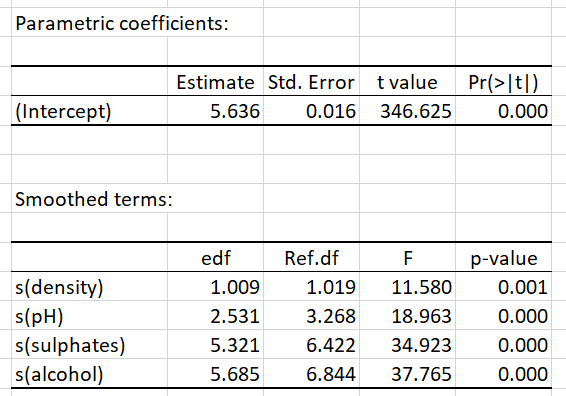 Il semble que toutes les variables physicochimiques ont un effet non-linéaire significatif sur le score.
Ceci peut être exploré grâce aux graphiques Components charts en bas du rapport :
Il semble que toutes les variables physicochimiques ont un effet non-linéaire significatif sur le score.
Ceci peut être exploré grâce aux graphiques Components charts en bas du rapport :
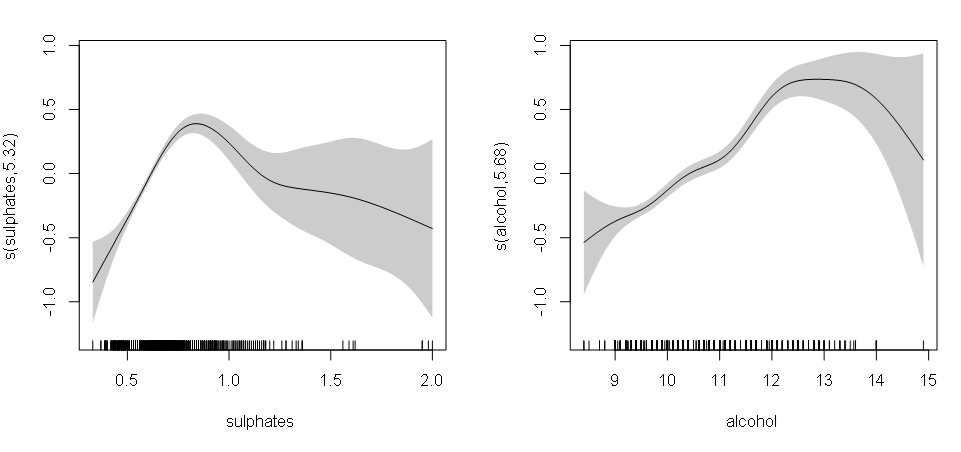 Dans chaque graphique, la ligne noire est la fonction non-linéaire de la variable explicative correspondante et la bande grise est l’enveloppe de confiance. Il semblerait que le score de qualité augmente de manière abrupte entre des valeurs faibles et des valeurs intermédiaires de concentration en sulfates, puis diminue à des niveaux élevés de sulfates.
Dans chaque graphique, la ligne noire est la fonction non-linéaire de la variable explicative correspondante et la bande grise est l’enveloppe de confiance. Il semblerait que le score de qualité augmente de manière abrupte entre des valeurs faibles et des valeurs intermédiaires de concentration en sulfates, puis diminue à des niveaux élevés de sulfates.
Il peut être intéressant d’éliminer certaines données extrêmes (alcool > 14 ou sulfates > 1,5) avant de relancer l’analyse. Cela permettrait de mieux se focaliser sur l’essentiel des données.
Cet article vous a t-il été utile ?
- Oui
- Non