R-Index dans Excel
Ce tutoriel explique comment mettre en place et interpréter une analyse R-Index dans Excel en utilisant le logiciel XLSTAT.
Jeu de données pour réaliser une analyse R-Index
Le jeu de données se compose de 5 échantillons de chocolats, Chocolat0 étant le produit de référence. Chaque échantillon a été testé 4 fois et à chaque fois le juge a donné son avis sur la similitude ou non de l'échantillon testé avec le produit de référence et sur la certitude de son choix. Les réponses se présentent sous le format 1, 2, 3 et 4 symbolisant respectivement un échantillon jugé similaire au produit de référence avec certitude, un échantillon jugé similaire sans certitude, un échantillon jugé différent sans certitude, et un échantillon jugé différent avec certitude.
Comment paramétrer l'analyse R-Index ?
-
Ouvrir XLSTAT.
-
Sélectionner Sensory / Tests de discrimination / R-Index. La boîte de dialogue de la fonctionnalité apparaît.
-
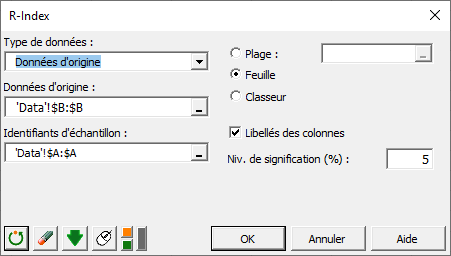
Dans l'interface, sélectionner Données d'origine en Type de données. Sélectionner les Données d'origine.
-
Sélectionner les Identifiants d'échantillon.
-
Cliquer sur OK. Les résultats sont ensuite affichés.
Comment interpréter les résultats d’une analyse R-Index ?
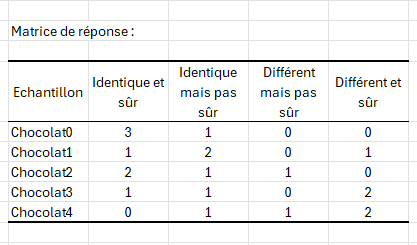
Le premier résultat important de la fonctionnalité R-Index est la matrice de réponse, qui résume l'information contenue dans le jeu de données. Dans ce tableau, nous pouvons déjà constater de fortes différences de jugement entre le Chocolat4 et Chocolat0, qui correspond au produit de référence : Chocolat0 a été jugé similaire au produit de référence avec certitude à 3 reprises et similaire mais sans certitude à 1 reprise, tandis que Chocolat4 a été jugé similaire au produit de référence sans certitude à 1 reprise, différent sans certitude à 1 reprise et différent avec certitude à 2 reprises.
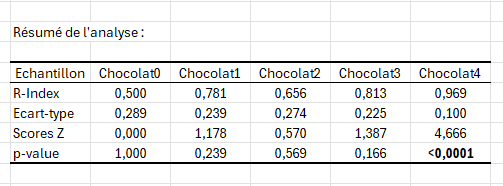
Nous analysons ensuite les différents R-Index calculés à partir de cette matrice de réponse. Tout d'abord, nous constatons que le R-Index du Chocolat4 est de 0.969, soit une valeur très proche de la valeur maximale de 1 qui symbolise un échantillon totalement différent du produit de référence. La p-value associée à cet échantillon confirme, qu'au seuil de 5%, Chocolat4 est différent du produit de référence. C'est le seul échantillon du jeu de données qui conduit à cette conclusion. Parmi les autres échantillons testés, Chocolat2 est le plus similaire au produit de référence.
En conclusion, l'utilisation de l'analyse R-Index sur cet exemple a permis d'identifier non seulement un produit significativement différent du produit de référence, mais a aussi permis d'établir un classement des produits les plus similaires au produit de référence.
Cet article vous a t-il été utile ?
- Oui
- Non