Fuzzy k-mean Clustering in Excel
Diese Anleitung hilft Ihnen beim Erstellen und Interpretieren eines Fuzzy-K-Means-Clusters in Excel mithilfe der XLSTAT-Software.
Datensatz für Fuzzy k-means Clustering
In dieser Anleitung verwenden wir eine Term-Dokumenten-Matrix, die durch die Feature-Extraktionsfunktion von XLSTAT generiert wird. Dabei stellen die ursprünglichen Textdaten eine Zusammenstellung von weiblichen Kommentaren dar, die auf mehreren E-Commerce-Plattformen hinterlassen wurden. Die Analyse wurde bewusst auf die ersten 5000 Zeilen des Datensatzes beschränkt.
Hinweis: Wenn Sie versuchen, die gleiche Analyse wie unten beschrieben mit denselben Daten erneut auszuführen, da die k-Means-Methode von zufällig ausgewählten Clustern ausgeht, werden Sie höchstwahrscheinlich andere Ergebnisse erhalten als die unten aufgeführten, es sei denn, Sie legen den Seed-Wert(123456789) fest, sodas Sie die gleichen Zufallszahlen wie der hier verwendeten haben. Um den Startwert zu korrigieren, gehen Sie zu den XLSTAT-Optionen, Registerkarte "Erweitert", und aktivieren Sie die Option "Startpunkt fixieren".
Einrichten eines Fuzzy-K-Means-Clusters
Wenn XLSTAT aktiviert ist, wählen Sie den Menüpunkt XLSTAT / Erweiterte Funktionen / Text-Mining / Fuzzy-K-Means-Clustering (siehe unten) aus.

Nach dem Klicken auf die Schaltfläche wird das Dialogfeld für das Fuzzy-K-Means-Clustering angezeigt. Sie können die Daten dann über das Feld "Term-Frequenz-Matrix" (Zellenbereichsauswahl) auswählen. Die Option Dokumentbeschriftung ist aktiviert, da die erste Datenspalte die Dokumentnamen enthält. Die Option "Beschriftungen" ist ebenfalls aktiviert, da die erste Datenzeile Termnamen enthält.
Der hier gewählte Unähnlichkeitsindex ist der Abstand, der auf dem Cosinus zwischen zwei Termvektoren basiert («1 - Cosinusähnlichkeit»), wodurch die Standardisierung von Vektoren klassifiziert werden kann und das Auflösen von Dokumenten unterschiedlicher Größe, deren Proportionen jedoch gleich bleiben, vermieden wird.
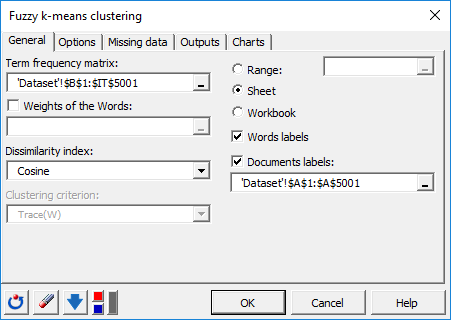
In der Registerkarte Optionen haben wir die Anzahl der Iterationen auf 50 erhöht, um die Qualität und Stabilität der Ergebnisse zu erhöhen. Der Algorithmus wird 20 Mal gestartet, wobei jedes Mal ein neuer zufälliger Startpunkt gewählt wird.
Die anfängliche Partition wird durch den Algorithmus K || definiert [Bahmani2012], eine schnellere Implementierung von kmeans ++. Diese Initialisierung wählt das nächste Gruppenzentrum so weit wie möglich von den bereits ausgewählten Zentren aus, wodurch es möglich ist, die unerwünschten Wirkungen, die durch abweichende Punkte verursacht werden, während der Initialisierung zu begrenzen.
Hier wurde eine Anzahl von 30 Klassen ausgewählt. Dies kann jedoch eingestellt werden, nachdem der Verlauf der Entwicklung des Kriteriums (gemäß verschiedenen Anzahlen von Zentren (k)) beobachtet wurde, um den Wendepunkt zu bestimmen, der dem Moment entspricht, an dem die erklärte Varianzverstärkung (Verhältnis zwischen Interklassenvarianz und Gesamtvarianz) beginnt, sich verringert (Elbow-Methode).
Hier wird ein Unschärfekoeffizient von 1,10 angewendet, um zu ermöglichen, dass bestimmte Beobachtungen, die sich am Rand einer Gruppe befinden, gleichzeitig mehreren verschiedenen Gruppen angehören (weiches Clustering). Dieser Koeffizient ermöglicht es auch, die Wirkung von Ausreißern zu reduzieren.
Die Berechnung beginnt, sobald Sie auf OK geklickt haben.
Interpretation eines Fuzzy-K-Means-Clusters
Nach der deskriptiven Statistik der ausgewählten Variablen gibt XLSTAT an, wie sich die Varianz für das optimale Klassifizierungskriterium zusammensetzt.
 Die folgende Tabelle zeigt die jeder Gruppe zugewiesenen Begriffe.
Die folgende Tabelle zeigt die jeder Gruppe zugewiesenen Begriffe.
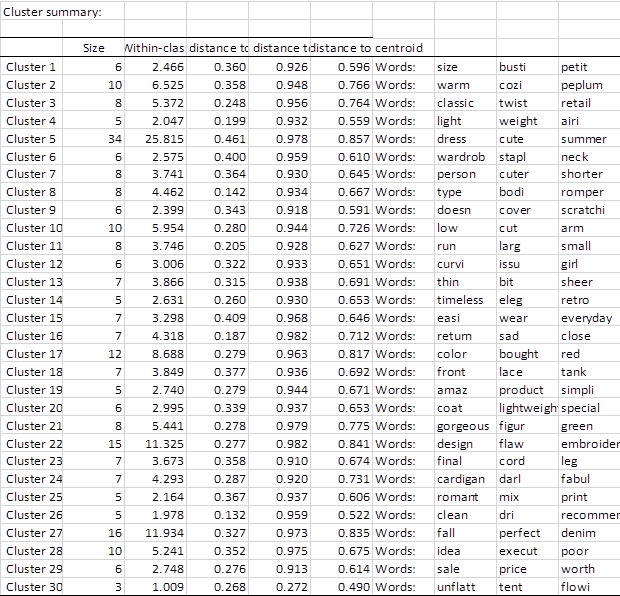
Generierte Klassen sind mit Begriffen verknüpft, die häufig in denselben Dokumenten vorkommen. Beispielsweise enthält Cluster 11 die Begriffe "run", "large" und "small", die diese Wörter höchstwahrscheinlich mit einem negativen Gefühl verknüpfen und sie dann in allen Rezensionen durch das Thema "Größenprobleme" ersetzen.
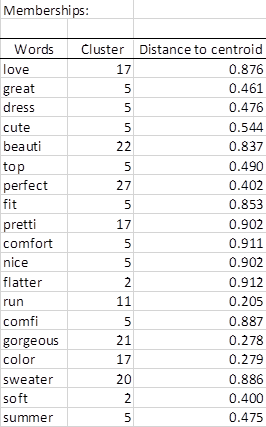
In der Zugehörigkeitstabelle wird für jedes Wort die Kennung der Gruppe angezeigt, der sie zugewiesen wurde. Letzteres wird berechnet, indem die Gruppe ausgewählt wird, für die die Wahrscheinlichkeit der Mitgliedschaft des Begriffs maximal ist (siehe Tabelle "Mitgliedschaftswahrscheinlichkeiten" im Bericht der Demo-Datei). Ein Teil dieser Tabelle ist unten dargestellt.
Cluster 17 enthält mehrere positive Einschätzungen.
Wir können diese generierten Gruppen oder "Themen" dann für mögliche zusätzliche Analysen verwenden, indem wir sie mit einer abhängigen Variablen verknüpfen, die vorhergesagt werden muss (z. B. eine überwachte Klassifizierung mithilfe von Support Vector Machine bezüglich der mit den Kommentaren verbundenen Gefühle).
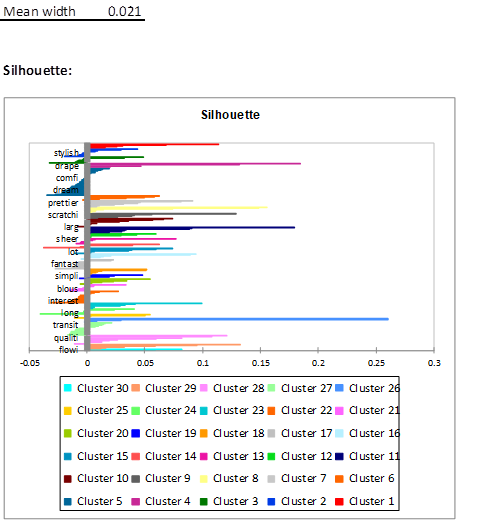
Die folgende Abbildung zeigt das Silhouette-Diagramm, das den Grad der Ähnlichkeit jeder Beobachtung in Bezug auf ihre Klasse angibt. Je näher diese Werte an 1 liegen, desto besser ist die Klassifizierung. Der Durchschnitt all dieser Werte ist ein weiterer Gesamtindikator für die Qualität. Letztere hebt eine Reihe von Beobachtungen innerhalb jedes Clusters hervor, wobei eine hohe durchschnittliche Ähnlichkeit auf das Vorhandensein stark korrelierter Terme in jeder dieser Gruppen hindeutet.
War dieser Artikel nützlich?
- Ja
- Nein