Classification k-means floue dans Excel
Ce tutoriel explique comment mettre en place une classification avec la méthode k-means floue dans Excel avec le logiciel XLSTAT.
Jeu de données pour réaliser une classification avec la méthode k-means floue (fuzzy k-means clustering)
Dans ce tutoriel, nous utiliserons une matrice documents-termes générée via la fonctionnalité XLSTAT Extraction de caractéristique dont les données textuelles initiales sont une compilation de commentaires laissés sur plusieurs plateformes de vente de vêtements en ligne. L’analyse est volontairement restreinte aux 5000 premières lignes du jeu de données.
But de ce tutoriel
Le but est ici de construire des groupes homogènes de termes afin d’identifier les sujets ou thèmes abstraits contenus dans les différents documents.
Le résultat de cette classification peut être mis à profit dans la réduction de dimensionnalité de la matrice documents-termes d’origine (« Feature selection ») en ne sélectionnant que les termes les plus importants dans chaque groupe généré (proportionnellement au nombre total d’occurrences par exemple).
Remarque : si vous essayez de faire l'analyse proposée ci-dessous sur les mêmes données, il est fort probable que vous n'obteniez pas les mêmes résultats. En effet, la méthode des k-means floue implique un tirage aléatoire. Pour obtenir les mêmes résultats, vous devrez fixer la graine des nombres aléatoires à 123456789 dans les Options/Avancées de XLSTAT.
Paramétrer une Classification k-means floue
Une fois que XLSTAT est ouvert, choisissez XLSTAT / Fonctions avancées / Classification k-means floue (voir ci-dessous) :
Une fois le bouton cliqué, la boîte de dialogue correspondant à la Classification k-means floue apparaît.
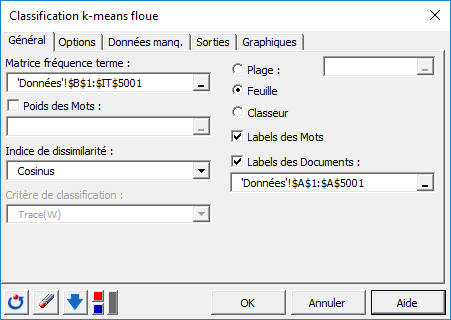
Vous pouvez alors sélectionner les données via le champ Matrice fréquence-terme (sélection de cellules dans Excel). L'option Labels des Documents est activée, car la première colonne de données contient le nom des documents. L'option Labels des Mots est également activée, car la première ligne de données contient le nom des termes. L’Indice de dissimilarité ici sélectionné est la distance basée sur le cosinus entre deux vecteurs termes (1 – Cosine similarity), lequel permet de normaliser les vecteurs à classer et évite de dissocier des documents de tailles différentes mais dont les proportions de termes demeurent identiques.
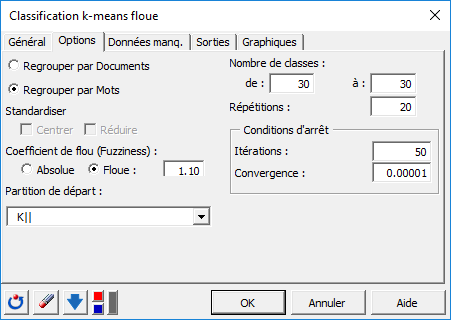
Dans l'onglet Options, nous fixons le nombre de répétitions à 20 dans le but d’augmenter la qualité et la stabilité des résultats. L'algorithme sera alors lancé 20 fois, avec à chaque fois un nouveau point de départ aléatoire.
La partition de départ sera définie par l’algorithme K|| [Bahmani2012] , lequel est une implémentation plus rapide des k-means++. Cette initialisation éloigne le prochain centre le plus possible des centres déjà choisis permettant ainsi de limiter les effets néfastes des points aberrants lors de l’initialisation.
Un nombre de classes de 30 a été retenu pour l’exemple. Ce dernier peut toutefois être ajusté après observation de la courbe d’évolution du critère selon différents nombres de centres (k) afin de déterminer le point d’inflexion correspondant au moment où le gain en variance expliquée (ratio entre variance interclasse et variance totale) commence à diminuer (méthode Elbow).
Un coefficient de flou (Fuzziness) d’une valeur de 1.10 sera ici appliqué afin de permettre à certaines observations situées à la périphérie d’un groupe d’appartenir en même temps à plusieurs autres groupes (soft clustering). Ce coefficient permet en outre de réduire l’effet des observations aberrantes.
Les calculs commencent lorsque vous cliquez sur le bouton OK.
Interpréter les résultats d'une classification avec la méthode des k-means floues (fuzzy k-means clustering)
Après les statistiques descriptives des variables sélectionnées, XLSTAT indique comment se décompose la variance pour le critère de classification optimale.

Le tableau ci-dessous indique pour chaque groupe les termes qui lui ont été affectés.
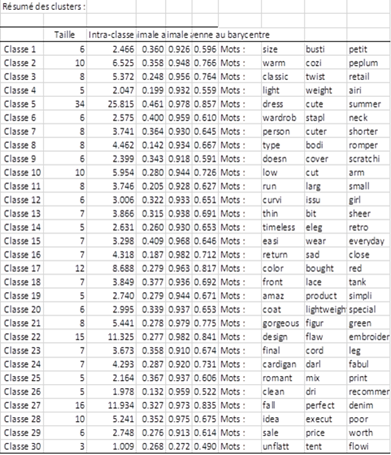
Les classes générées sont associées à des termes apparaissant fréquemment dans les mêmes documents. Par exemple, le cluster 11 contient les termes « run » « large » et « small » ce qui relie très certainement ces mots à un sentiment négatif et les remplacer par la suite dans l’ensemble des revues par la thématique « Size issues » (problèmes de taille).
Un tableau présente ensuite pour chaque mot, l'identifiant du groupe auquel il a été affecté. Ce dernier est calculé en choisissant le groupe pour lequel la probabilité d’appartenance du terme est maximale (Cf. Table Probabilités d’appartenance dans le rapport du fichier démo). Une partie du tableau est présentée ci-dessous. On pourra ensuite utiliser ces groupes générés ou « topics » pour d'éventuelles analyses supplémentaires en les associant à une variable dépendante que l’on doit prédire (par exemple une classification supervisée type Machine à Vecteurs de Support sur les sentiments associés aux avis).
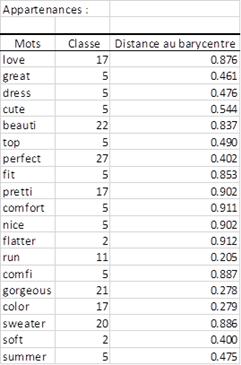
Le cluster 17 contient plusieurs sentiments positifs.
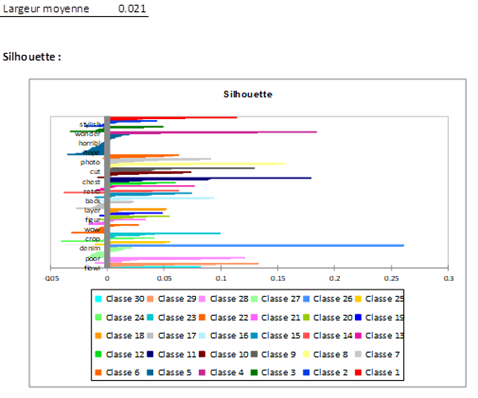
La figure suivante présente la silhouette qui est un graphique affichant le degré de similitude de chaque observation vis-à-vis de sa classe.
Plus ces valeurs sont proches de 1 et meilleure est la classification. La moyenne de toutes ces valeurs est un autre indicateur global de qualité.
Cette dernière met en évidence un certain nombre d’observations dans chaque groupe ayant une forte similarité moyenne indiquant ainsi la présence de termes fortement corrélés au sein de chacun de ces groupes.
Cet article vous a t-il été utile ?
- Oui
- Non