Extreme Gradient Boosting (XGBOOST) dans Excel
Ce tutoriel explique comment mettre en place et entraîner un modèle XGBOOST pour réaliser une classification dans Excel en utilisant le logiciel de statistiques XLSTAT.
Jeu de données pour la mise en place d'un modèle Gradient Boosting (XGBOOST)
Le jeu de données utilisé dans ce tutoriel provient de la plateforme de data science, Kaggle et est accessible à cette adresse.
Le jeu de données « Banknotes » est constitué d'une liste de 200 billets de banque contrefaits ou non. Le jeu de données est composé de 6 variables dont une informe sur l’authenticité du billet de banque tandis que les 6 autres sont des variables quantitatives donnant les caractéristiques d’un billet.
Counterfeit : si le billet de banque est authentique, on notera « 0 », dans le cas contraire où le billet est contrefait alors, on notera « 1 ». Dans ce jeu de données, 100 billets sont authentiques et 100 billets sont contrefaits.
Length, Left, Right, Bottom et Top sont les variables quantitatives précisant les mesures et dimensions des billets de banque.
Paramétrer un modèle XGBOOST avec XLSTAT
-
Ouvrir XLSTAT.
-
Sélectionner XLSTAT/ Machine learning / Extreme Gradient Boosting. La boîte de dialogue correspondant à la régression apparaît.
-
Dans le champ Variable réponse, sélectionner la variable "Counterfeit".
-
Régler le champ Type de réponse sur binaire puisque la variable réponse contient uniquement 2 valeurs uniques**.**
-
Dans le champ Variables explicatives quantitatives, sélectionner l’ensemble des variables quantitatives du jeu de données.

-
Dans l’onglet Options, plusieurs paramètres sont disponibles pour configurer le modèle, nous utilisons ici les paramètres par défaut.

-
Dans l’onglet Validation, sélectionner l’option échantillon de validation aléatoire et fixer le nombre d’observations à 30 pour pouvoir évaluer les performances du modèle sur de nouvelles données.
-
Dans l’onglet Sorties, activer les champs matrice de confusion, résultats par objet, importance des variables et sélectionner gain dans le champ Type d’importance.
-
Cliquer sur OK pour lancer les calculs et afficher les résultats sélectionnés.
Interpréter les résultats d’une analyse XGBOOST
La proportion de mal classés nous donne les performances du modèle sur les échantillons d’apprentissage et de validation. La proportion de mal classés est de 1,2% l’échantillon d’apprentissage et de 10% pour l’échantillon de validation.
![]()
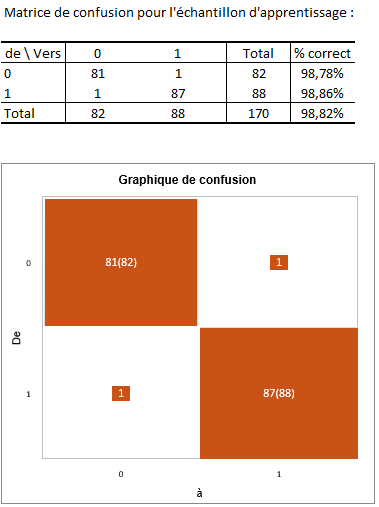
La matrice de confusion pour l'échantillon d'apprentissage est ensuite affichée dans le rapport. Ce tableau permet de visualiser le pourcentage d'observations bien classées pour chaque modalité (vrais positifs et vrais négatifs). Par exemple, nous pouvons voir que les observations de la modalité 0 (authentique) ont bien été classées à 98,78% alors que les observations de la modalité 1 (contrefait) ont bien été classées à 98,86%.
Le graphique de confusion permet de visualiser synthétiquement ce tableau. Les carrés en gris sur la diagonale représentent les effectifs observés pour chaque modalité. Les carrés orange représentent, quant à eux, les effectifs prédits pour chaque modalité. Ainsi, nous pouvons voir que les surfaces des carrés se superposent intégralement pour les deux modalités (84 observations bien prédites sur 82 observations observées pour la modalité 0 et 87 observations bien prédites sur 88 observations observées pour la modalité 1).
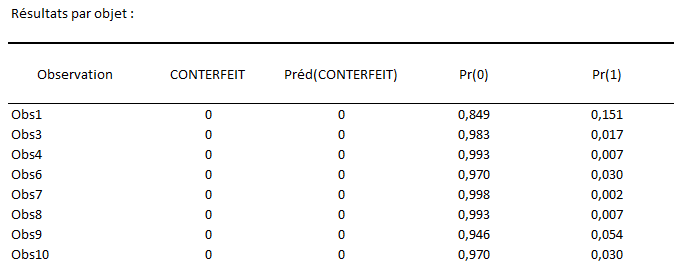
Ensuite, le tableau des résultats par objet affiche la réponse associée à chaque observation, la classe prédite pour cette dernière ainsi que les probabilités associées à chacune de ses modalités.
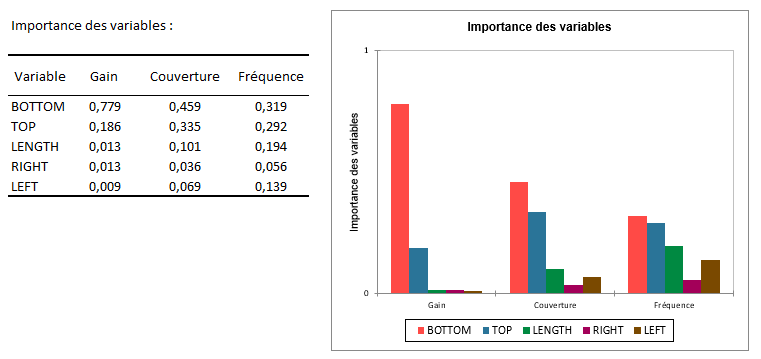
Intéressons-nous maintenant au tableau et au graphique d'importance des variables, ils nous permettent de savoir quelles variables sont les plus importantes pour prédire l'authenticité des billets de banque.
Le gain correspond à la contribution relative d'une variable au modèle. Plus sa valeur est élevée comparée aux autres variables dans le modèle, plus la variable est importante pour générer une prédiction. Par exemple, nous remarquons que la variable la plus importante pour prédire l'authenticité correspond à BOTTOM. On identifie donc un lien clair entre l'authenticité du billet et la largeur de sa marge inférieure.
Conclusion de la classification avec XGBOOST dans XLSTAT
En conclusion, nous obtenons un taux d’observations bien classées de 97,65% et identifions que la caractéristique la plus importante pour vérifier l’authenticité correspond la marge inférieure du billet. Aussi, la phase de validation avec un taux d’observations bien classées de 90% nous permet de vérifier que le modèle se généralise à de nouvelles données.
Cet article vous a t-il été utile ?
- Oui
- Non