Classification KNN ou K plus proches voisins dans Excel
Ce tutoriel explique comment calculer et interpréter une classification par les k plus proches voisins avec Excel en utilisant XLSTAT.
Jeu de données pour la classification par les K plus proches voisins avec XLSTAT
Ces données constituent un sous-ensemble du jeu de données proposées par Dr. William H. Wolberg (University of Wisconsin Hospitals, Madison). Chaque observation correspond à des caractéristiques de cellules issues d’une biopsie mammaire (colonnes C-K) mesurées sur des patientes souffrant de cancer du sein classé bénin ou malin. Le jeu de données complet peut être téléchargé ici :
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Original%29
But de ce tutoriel sur la classification par les K plus proches voisins avec XLSTAT
Le but de ce tutoriel est d’utiliser la classification par les K plus proches voisins (KNN) pour classer des cancers en bénin ou malin. Nous utiliserons les 100 premières observations en tant qu’échantillon d’apprentissage et les 20 dernières en tant qu’échantillon de prédiction. Ainsi, la classe de cancer a été supprimée pour les 20 dernières observations.
La classification par les K plus proches voisins sera faite en se basant les variables explicatives d’apprentissage suivantes :
- Épaisseur de la masse prélevée
- Uniformité de la taille des cellules
- Uniformité de la forme des cellules
- Adhésion Marginale (cohésion des cellules au sein du tissu)
- Taille d’une cellule épithéliale
- Nucléole nu (Nucléole dépourvu de cytoplasme)
- Uniformité de la chromatine
- Nucléole normale
- Mitoses
Ces variables ont des notes comprises entre 1 et 10.
Paramétrer une classification par les K plus proches voisins avec XLSTAT
Une fois XLSTAT lancé, choisissez la commande XLSTAT / Machine Learning / K plus proches voisins.
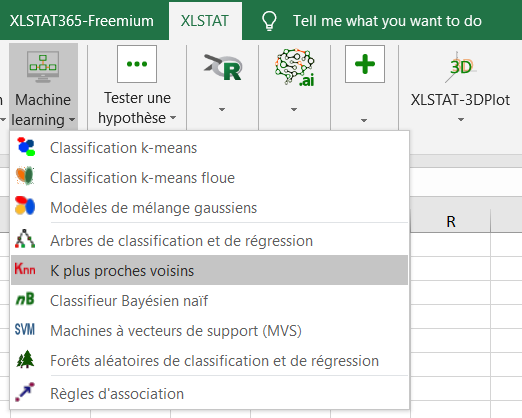
La boîte de dialogue sur la classification par les K plus proches voisins apparaît.
Dans l'onglet Général, sélectionnez les classes de l’échantillon d’apprentissage dans le champ Y / Variable qualitative. Sélectionnez les variables explicatives associées à l’échantillon d’apprentissage au sein du champ X / Variables explicatives / Quantitatives.
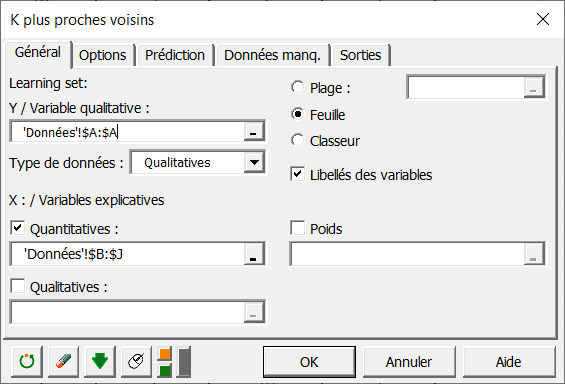
Dans l'onglet Prédiction, sélectionnez les données relatives aux 20 observations à droite du jeu de données.
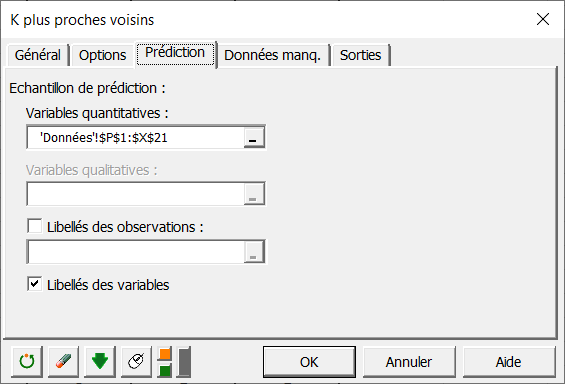
Dans l’onglet Options, il est possible de paramétrer l’algorithme. Par exemple, il est possible de choisir le type de fonction (Métrique ou Noyaux) à utiliser pour calculer les distances (sous onglet Général).
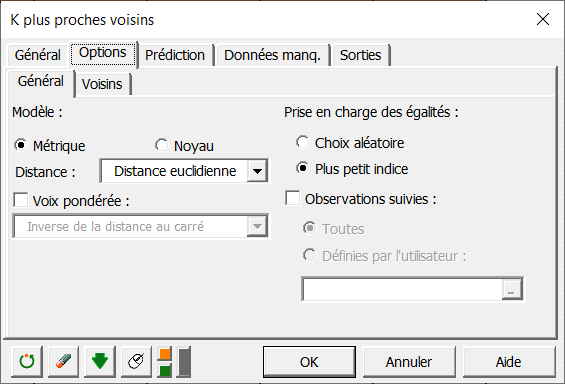
Dans le sous onglet Voisins, il est possible de choisir le nombre de voisins manuellement (Définies par l’utilisateur) ou de manière automatique (Automatique), cette dernière permet de déterminer le nombre optimal dans une plage de valeur.
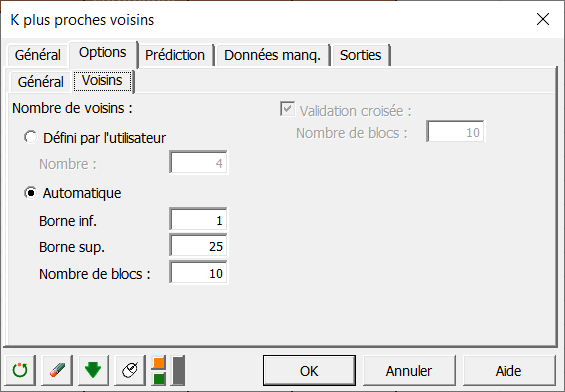
Une fois que vous avez cliqué sur le bouton OK, les calculs commencent puis les résultats sont affichés.
Interpréter les résultats de la classification par les K plus proches voisins avec XLSTAT
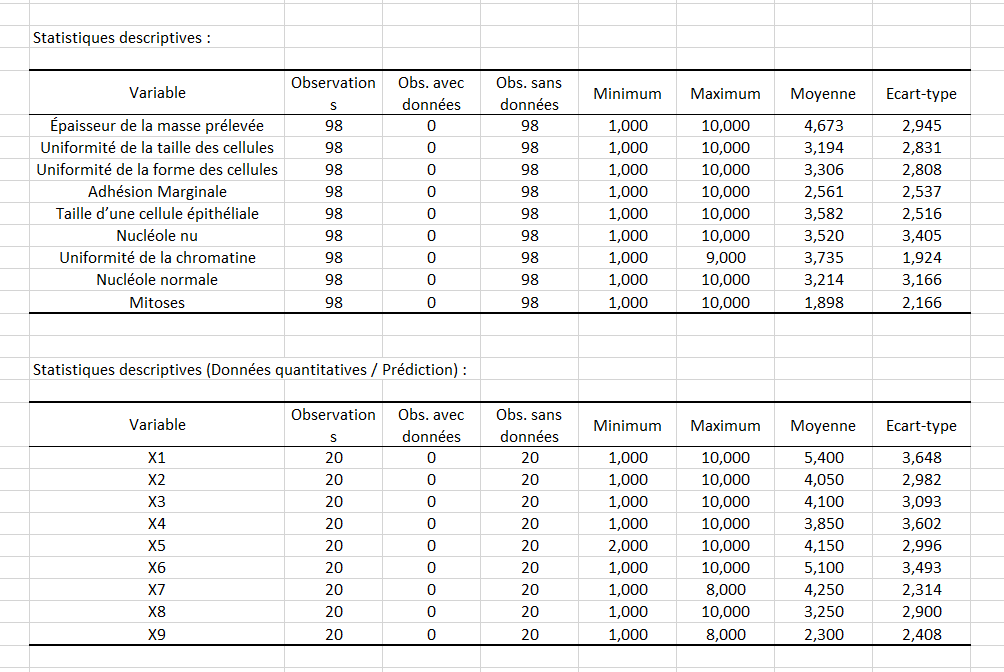
Le premier tableau affiche les statistiques relatives aux variables explicatives de l'échantillon d'apprentissage, et le deuxième à l'échantillon de prédiction.
Le tableau suivant nous donne les erreurs de prédiction estimées par validation croisée pour chaque nombre de voisins dans la liste et le graphique associé.
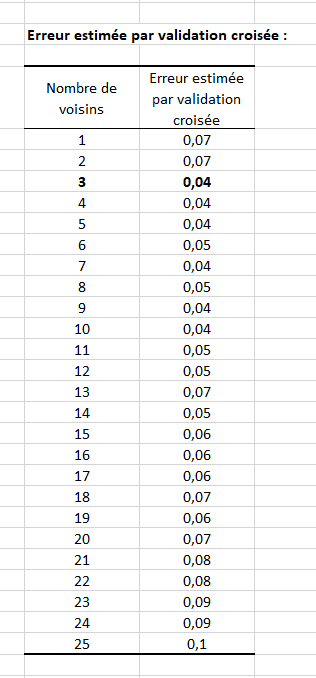
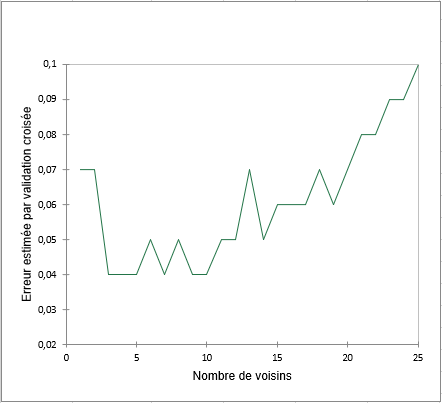 La Prédiction est réalisée en utilisant le nombre de voisins optimal, c’est-à-dire celui donnant l’erreur de validation croisée minimale. Dans notre cas le nombre de voisins utilisé est 3.
La Prédiction est réalisée en utilisant le nombre de voisins optimal, c’est-à-dire celui donnant l’erreur de validation croisée minimale. Dans notre cas le nombre de voisins utilisé est 3.
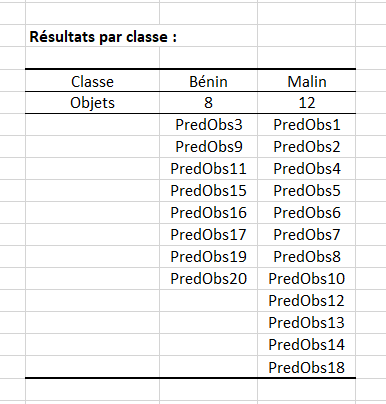
Les classes prédites pour l’échantillon de prédiction sont affichées d’abord par classe.
Puis par observation :
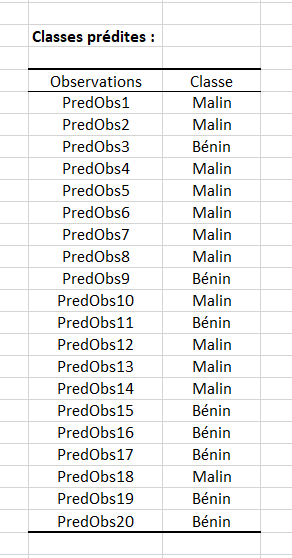
Notre modèle, au regard des données, nous prédit que :
- Les observations 3, 9, 11, 15, 16, 17, 19, 20 ont un cancer bénin.
- Les 12 autres observations ont un cancer malin.
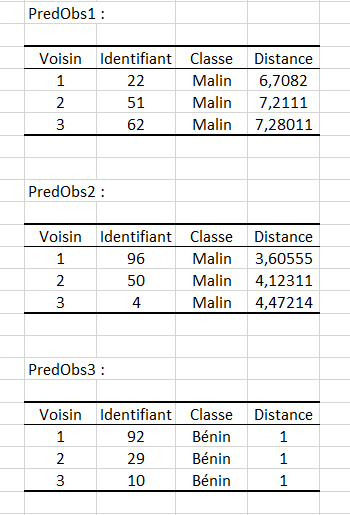
Enfin, pour chaque observation suivie, la classe des voisins participant au vote ainsi que les distances séparant les voisins de l’observation suivie sont résumées dans un tableau. Ci-dessous les tableaux contenant les informations de suivi pour les trois premières observations :
Cet article vous a t-il été utile ?
- Oui
- Non