Arbre de classification (C&RT) dans Excel
Ce tutoriel vous aide à construire un arbre de classification C&RT dans Excel en utilisant le logiciel de statistiques XLSTAT.
Si vous n'êtes pas sûr que ce soit la fonction d’apprentissage supervisée que vous recherchez, veuillez consulter ce guide.
Jeu de données pour créer un arbre de classification (C&RT) et but de ce tutoriel
Les données proviennent à l'origine de l'Institut national du diabète et des maladies digestives et rénales. L’objectif du tutoriel est de prédire si un patient est atteint ou non de diabète sur la base de certaines mesures diagnostiques incluses dans le jeu de données. Tous les patients de cette étude ont au moins 21 ans et sont issus du groupe des indiens Pimas (peuple de Nord-Amérindiens originaires du Mexique et du Sonora). Le jeu de données comprend plusieurs variables prédictives médicales (indépendantes) et une variable cible (dépendante) : Diabète. Les variables indépendantes incluent le nombre de grossesses du patient, son IMC, son niveau d'insuline, son âge, etc.
Paramétrer l'arbre de classification (C&RT)
Une fois XLSTAT lancé, cliquez sur le menu XLSTAT / Machine Learning / Arbres de classification et régression.
La boîte de dialogue apparaît, vous pouvez commencer la sélection des données sur la feuille Excel.
On sélectionne la variable dépendante, qui est dans ce cas précis la variable qualitative binaire "Diabète" qui vaut "Oui" si le patient est atteint de diabète et "Non" sinon.
Les variables explicatives sont les huit variables descriptives restantes.
L'option Libellés des variables est laissée activée car la première ligne des colonnes sélectionnées comprend le nom des variables. Nous choisissons la méthode C&RT pour créer l'arbre.
Ensuite, pour ne pas avoir un arbre trop complexe, nous précisons dans les options que nous ne voulons pas que la profondeur de l'arbre dépasse 3 et fixons la valeur du paramètre de complexité (CP) à 0,001. Cela signifie que la construction de l’arbre ne se poursuit pas à moins de réduire l'impureté globale de l’arbre d'au moins un facteur CP.
Les options permettent d'ajuster plusieurs paramètres ayant une incidence sur la construction des arbres.
En sortie graphique, nous choisissons d'afficher l'arbre en utilisant des diagrammes en bâtons pour représenter les fréquences des espèces au niveau de chaque nœud de l'arbre.
Une fois que vous avez cliqué sur le bouton OK, les calculs commencent et les résultats sont affichés.
Interpréter les résultats d'un arbre de classification (C&RT)
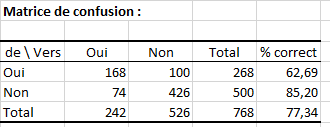
Les deux premiers tableaux regroupent les statistiques descriptives des différentes variables et le tableau des corrélations. En dessous est affichée la matrice de confusion qui résume l'information des reclassements d'observations, et qui permet de déduire les taux de bons et mauvais classements. Le "% correct" correspond au rapport du nombre d'observations bien classées sur le nombre total d'observations. Ici il est égal à 77,3%.
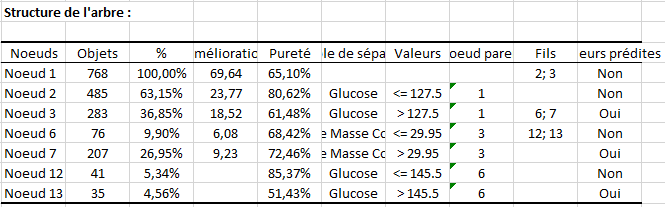
Vient ensuite la structure de l'arbre sous forme de tableau. Il décrit pour les différents nœuds, le nombre d'objets au niveau de chaque nœud, le % correspondant, l’amélioration qui correspond au nombre d’observations dans le nœud multiplié par la réduction d’impureté engendrée par la scission de ce nœud, la pureté qui mesure le % d'observations se trouvant dans la classe (ou modalité) dominante au niveau du nœud, les nœuds parents et fils, la variable de séparation, la ou les valeurs correspondantes (des intervalles pour les variables quantitatives explicatives), et la classe prédite par le nœud.
Le tableau suivant présente une lecture de l'arbre sous forme de règles en langage naturel. Pour chaque nœud, la règle correspondant à la classe prédite est affichée. Le % correspondant à la classe au niveau du nœud étant lui donné par le % d’observations dans le nœud.
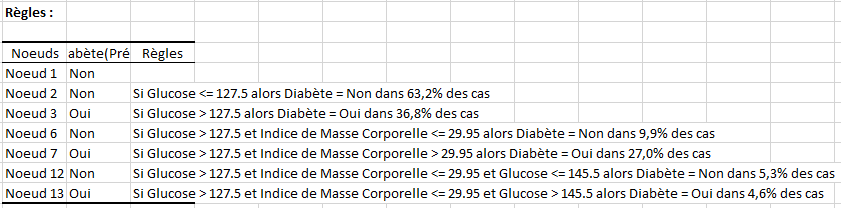
Ainsi on voit que : "Si Glucose <= 127.5 alors Diabète = No dans 63,2% des cas", cette règle est vérifiée pour 485 individus (63% des données) avec une pureté au niveau du nœud de 80,6% comme indiqué dans le tableau structure de l’arbre.
Une partie de l'arbre de classification généré est affichée ci-dessous.
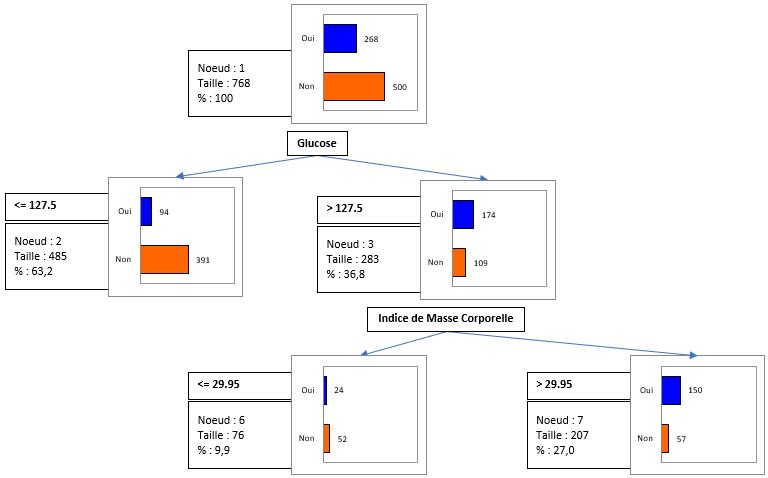
Ce diagramme permet de visualiser les étapes successives au cours desquelles l'algorithme C&RT identifie les variables qui permettent de séparer au mieux les différentes catégories de la variable dépendante.
L'algorithme s'arrête lorsque plus aucune règle ne peut être trouvée, ou lorsque l'une des limites fixées par l'utilisateur est atteinte (nombre d'objets au niveau du nœud parent ou fils, profondeur de l'arbre, le seuil CP <= limite fixée par l’utilisateur).
Une visualisation alternative est proposée par XLSTAT. Au lieu de représenter les distributions au niveau de chaque nœud avec des diagrammes en bâtons, XLSTAT permet aussi de les représenter avec des diagrammes circulaires, qui s'avèrent plus lisibles lorsqu'il y a de nombreux nœuds et plus de 4 ou 5 modalités pour la variable dépendante.
Cet article vous a t-il été utile ?
- Oui
- Non