Naiver Bayes-Klassifikator in Excel - Anleitung
Dieses Tutorium wird Ihnen helfen, eine Naive Bayes-Klassifikation in Excel mithilfe der Software XLSTAT einzurichten und zu interpretieren. Sie sind nicht sicher, ob es sich hierbei um die überwachte maschinelle Lernfunktion handelt, nach der Sie suchen? Weitere Hinweise finden Sie hier.
Datensatz für das Einrichten eines Naive Bayes-Klassifikators in Excel mit XLSTAT
Absicht dieses Tutoriums
Der Naive Bayes-Klassifikator ist ein überwachter maschineller Lernalgorithmus, der es Ihnen ermöglicht, eine Gruppe von Beobachtungen gemäß einer Gruppe von Regeln, die durch den eigentlichen Algorithmus bestimmt werden, zu klassifizieren. Dieser Klassifikator muss zuerst anhand eines Trainingsdatensatzes lernen, welche Klasse für eine Gruppe von Einträgen erwartet wird. Während der Trainingsphase erarbeitet der Algorithmus die Klassifikationsregeln für diesen Trainingsdatensatz und verwendet diese in der Vorhersagephase, um die Beobachtungen des Vorhersagedatensatzes zu klassifizieren.
In diesem Tutorium verwenden wir einen Datensatz mit dem Titel Zoo-Datenbank, die von Richard Forsyth im Jahr 1990 erstellt wurde, um sein PC-Beagle-Programm zu veranschaulichen. Er enthält eine Liste von 101 Tieren in Zeilen und ihre verbundenen Attribute, die in 17 ausgeprägten qualitativen Variablen beschrieben werden (Spalten): Haare, Federn, Eier, Milch, luftübertragen, aquatisch, Raubtier, gezahnt, Rückgrat, atmet, giftig, Kiemen, Beine, Schwanz, Haustier, katzengroß.
Alle außer einer dieser Variablen sind Boolesche Werte, die den Wert 1 annehmen, wenn das entsprechende Attribut für das betreffende Tier beobachtet wird, wie z.B. Schwanz oder Zähne, und andernfalls 0. Die restliche Variable, das Attribut Beine, nimmt einen Wert aus 0, 2, 4, 5, 6 und 8 ein.
Schließlich ist die 18. Spalte eine ganze Zahl zwischen 1 und 7, die die Art oder Untergruppe angibt, der das Tier angehört.
Dieser Typwert ist die Klasse, die unser Naive Bayes-Klassifikator vorhersagen soll. Der Datensatz wird dann in zwei Untergruppen unterteilt. Die erste enthält die ersten 94 Zeilen und wird zum Trainieren des Klassifikators verwendet. Die zweite sammelt nur 7 Beobachtungen, für die wir unsere Vorhersage machen.
Einrichten des Naive Bayes-Klassifikators in XLSTAT
Nach dem Öffnen von XLSTAT wählen Sie den Befehl XLSTAT/Maschinelles Lernen/Naive Bayes-Klassifikator.
Das Dialogfenster Naive Bayes-Klassifikator wird angezeigt.
Wählen Sie zuerst die Ausgabeklassen des Trainingsdatensatzes im Feld Y/Qualitative Variablen aus. In unserem Fall ist die Ausgabeklasse die Tierart, die in der 18. Spalte des Datensatzes aufgelistet ist.
Wie oben erwähnt werden nur die ersten 94 Zeilen als Trainingsdatensatz verwendet, dementsprechend muss die Auswahl erfolgen.
Als nächstes müssen die X/Erklärenden Variablen ausgewählt werden. In unserem Fall verwenden wir nur qualitative Variablen. Das Kontrollkästchen Qualitativ muss aktiviert sein und 17 Attribute unseres Trainingsdatensatzes ausgewählt werden.
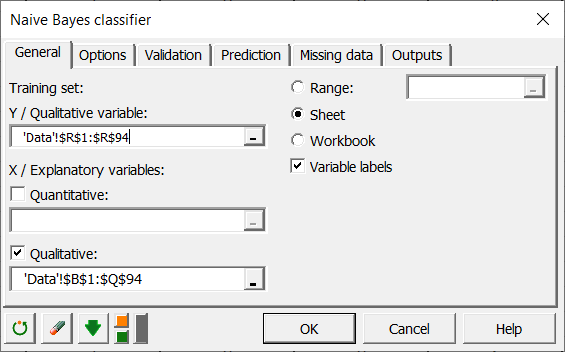
Dann müssen wir den Vorhersagedatensatz auswählen, der aus den 7 Tieren unten in der Liste besteht.

In der Registerkarte Option können Sie zwischen verschiedenen parametrischen Verteilungen auswählen, wenn Sie quantitative Daten verwenden, oder eine empirische Verteilung verwenden, um die konditionellen Wahrscheinlichkeiten zu schätzen. Für qualitative Daten jedoch macht nur die empirische Verteilung Sinn, und die Verteilungsauswahl wird daher wie in der nachstehenden Abbildung gezeigt deaktiviert.
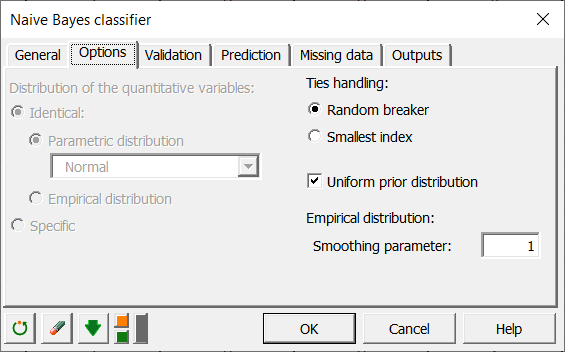
Um Ihren Klassifikator beim Klassifizieren neuer Beobachtungen durch qualitative Variablen robuster zu machen, können Sie eventuell eine Laplace-Glättung anwenden, indem Sie die Glättungsparameter auf eine ganze Zahl außer 0 festlegen. In unserem Fall setzen wir diesen Wert auf 1.
Schließlich aktivieren wir alle 7 Ausgabeoptionen in der Registerkarte Ausgabe wie nachstehend abgebildet.
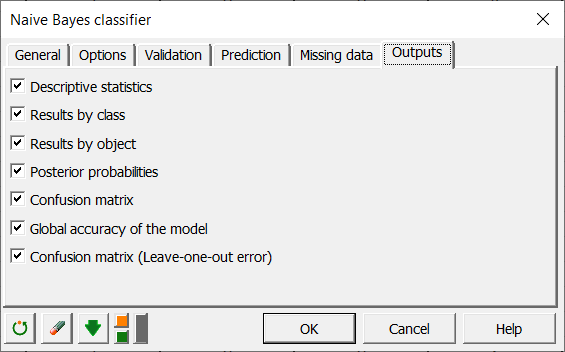
Die Berechnungen beginnen, sobald Sie auf OK geklickt haben.
Interpretieren der Ergebnisse einer Naive Bayes Klassifikation in XLSTAT
Die ersten beiden Tabellen zeigen die beobachtete Häufigkeit und die relativen Häufigkeitsverteilungen der Ausgabeklasse und der Attribute im Trainingsdatensatz an.
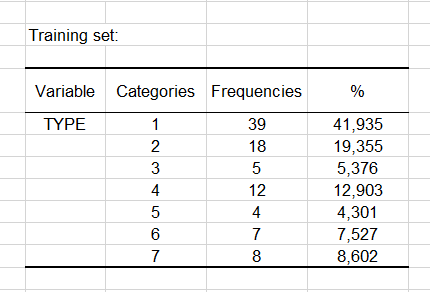
Wir können in der ersten Tabelle sehen, dass die Tierklasse des Typs 1 mit 41,935 % bei Weitem die häufigste im Trainingsdatensatz ist. In der nächsten Tabelle unten können wir sehen, dass keine Instanzen von Tieren mit 5 Beinen im Trainingsdatensatz vorkamen.
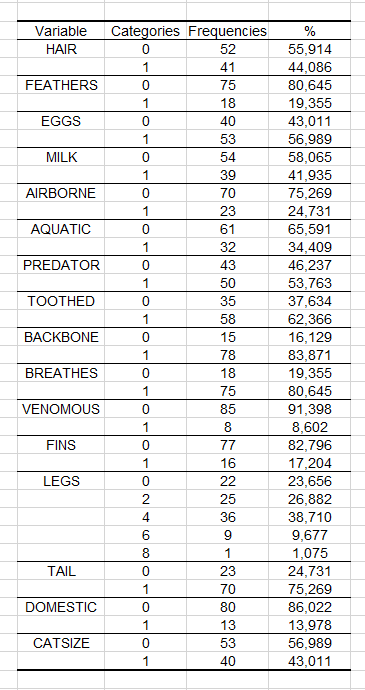
Wir können allerdings in der nächsten Tabelle, welche die beobachteten Häufigkeitsverteilungen im Vorhersagedatensatz zeigt, sehen, dass ein Tier mit 5 Beinen im Vorhersagedatensatz enthalten ist.
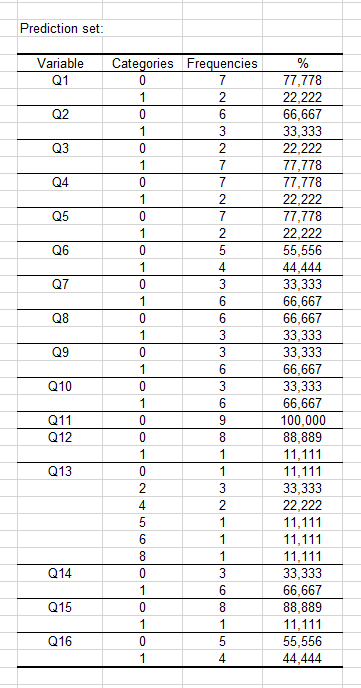
Es wird interessant sein, zu sehen, wie unser Klassifikator auf diese neue Modalität reagiert, die nicht im Trainingsdatensatz vorhanden war.
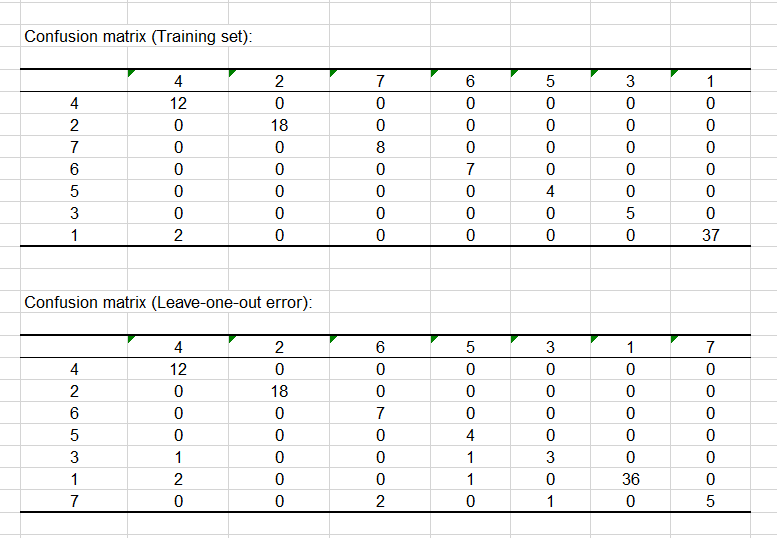
Aber sehen wir uns zunächst die Leistung unseres Klassifikators im Trainingsdatensatz mit den beiden Konfusionsmatrizen an, die als nächstes angezeigt werden. Wir können auf dem Bild unten sehen, dass der Klassifikator eine hohe Rate wahrer, positiver Ergebnisse auf beiden Matrizen darstellt, was sehr ermutigend ist.
Schließlich wird die Klassifikation für unseren Vorhersagedatensatz über zwei Tabellen wie unten gezeigt angezeigt:
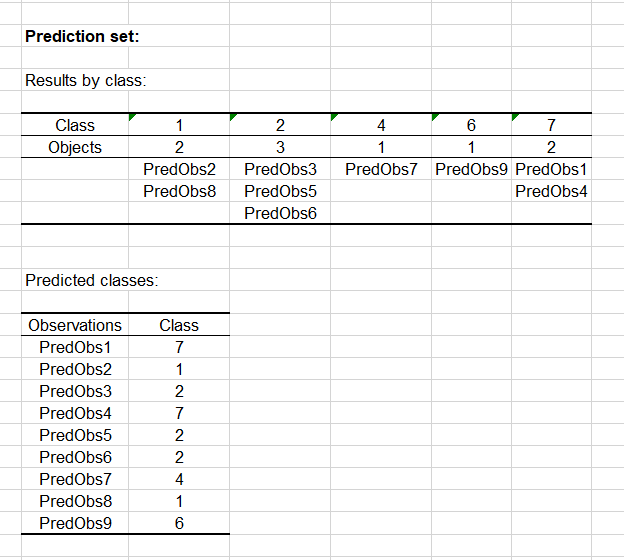 Die Ergebnisse werden nach Klasse in der ersten Tabelle und für jede Beobachtung in der zweiten Tabelle ausgegeben. Wir können sehen, dass die Beobachtung mit dem Namen PredObs4 einer Klasse vom Typ 7 zugeordnet wird.
Dies ist das Tier mit 5 Beinen, über das wir vor Kurzem gesprochen haben. Es handelt sich um einen Seestern, der in der Tat zum Typ 7 gehört, zusammen mit der Krabbe, der Venusmuschel und dem Krebs.
Folglich hat unser Klassifikator diese Beobachtung dank der Laplace-Glättung erfolgreich gekennzeichnet.
Die Ergebnisse werden nach Klasse in der ersten Tabelle und für jede Beobachtung in der zweiten Tabelle ausgegeben. Wir können sehen, dass die Beobachtung mit dem Namen PredObs4 einer Klasse vom Typ 7 zugeordnet wird.
Dies ist das Tier mit 5 Beinen, über das wir vor Kurzem gesprochen haben. Es handelt sich um einen Seestern, der in der Tat zum Typ 7 gehört, zusammen mit der Krabbe, der Venusmuschel und dem Krebs.
Folglich hat unser Klassifikator diese Beobachtung dank der Laplace-Glättung erfolgreich gekennzeichnet.
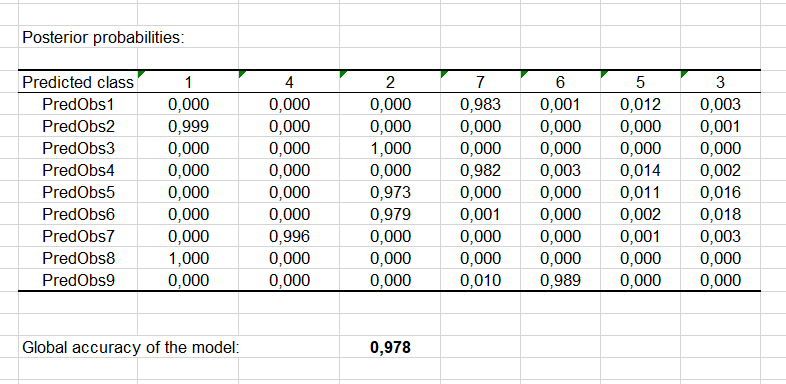
Schließlich wird die A posteriori Wahrscheinlichkeit für jede Klasse für jede Beobachtung des Vorhersagedatensatzes angegeben:
War dieser Artikel nützlich?
- Ja
- Nein