Clasificación Naive Bayes: tutorial en Excel
Este tutorial le mostrará cómo crear e interpretar una clasificación de Naive Bayes en Excel usando el software XLSTAT.
¿No está seguro si esta función de aprendizaje automático supervisado es la que busca? Por favor, consulte esta guía.
Datos para configurar un Clasificador Naive Bayes en Excel con XLSTAT
Este tutorial utiliza un conjunto de datos puestos a disposición por el Center for Machine Learning and Intelligent Systems. Es posible acceder a su repositorio de aprendizaje automático en esta dirección , en la que se encuentran muchos conjuntos de datos interesantes relacionados con el aprendizaje automático (Machine Learning).
Objetivo de este tutorial
El clasificador de Naive Bayes es un algoritmo de aprendizaje automático supervisado que permite clasificar un conjunto de observaciones según un conjunto de reglas determinadas por el propio algoritmo. Este clasificador tiene primero que ser entrenado con un conjunto de datos de entrenamiento que muestra qué clase se espera para un conjunto de entradas. Durante la fase de entrenamiento, el algoritmo elabora las reglas de clasificación sobre este conjunto de datos de entrenamiento que se utilizará en la fase de predicción para clasificar las observaciones del conjunto de datos de predicción. En este tutorial, vamos a utilizar una base de datos denominado Zoo, que ha sido creado por Richard Forsyth en 1990 para ilustrar su programa PC-Beagle. Contiene una lista de 101 animales en filas y sus atributos asociados descritos en 17 variables cualitativas distintas (columnas): pelo, plumas, huevos, leche, aire, acuático, depredador, dientes, columna vertebral, respira, venenoso, aletas, patas, cola , doméstico, felino, tamaño. Todas menos una de estas variables son valores booleanos que tienen un valor de 1 cuando se observa el atributo correspondiente para el animal en cuestión, tales como la cola o los dientes, y 0 en caso contrario. La variable restante, el atributo patas, toma un valor entre 0, 2, 4, 5, 6 y 8. Por último, la columna 18 es un valor entero que va de 1 a 7 y proporciona el tipo o el subgrupo al que pertenece el animal. Este valor es la clase de tipo que queremos que prediga nuestro clasificador Naive Bayes. El conjunto de datos se divide a continuación en 2 subgrupos. El primero contendrá las 94 primeras filas y será utilizado para entrenar al clasificador. El segundo agrupará sólo 7 observaciones sobre las que vamos a hacer nuestra predicción.
Configuración del Clasificador Naive Bayes en XLSTAT
Una vez abierto XLSTAT, seleccionar el comando XLSTAT / Aprendizaje Automático / Clasificador Naive Bayes.

Aparece el cuadro de diálogo del clasificador Naive Bayes.
En primer lugar, seleccione la clase de salida de la muestra de aprendizaje en el campo Y / Variables cualitativas. En nuestro caso, la clase de salida es el tipo de animal que se enumeran en la columna 18 del conjunto de datos. Como se mencionó anteriormente, sólo las primeras 94 filas se utilizan como un conjunto de datos de entrenamiento, la selección tiene que hacerse en consecuencia. A continuación, se deben seleccionar las X / Variables explicativas. En nuestro caso, estamos utilizando sólo variables cualitativas. Debemos activar la casilla de verificación Cualitativas, y seleccionar los 17 atributos de nuestra muestra de entrenamiento.
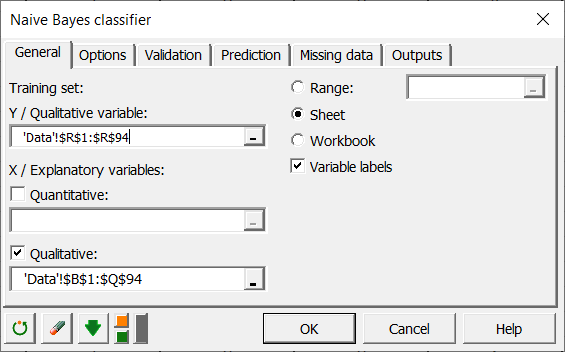
A continuación, hay que seleccionar el conjunto de datos de predicción que se compone de los 7 animales de la parte inferior de la lista.

En la pestaña Opciones, puede elegir entre varias distribuciones paramétricas si está utilizando datos cuantitativos, o usar una distribución empírica para estimar las probabilidades condicionales. Para datos cualitativos, sin embargo, sólo tiene sentido la distribución empírica y, por tanto, la selección de distribución se desactiva como se muestra en la siguiente captura de pantalla.
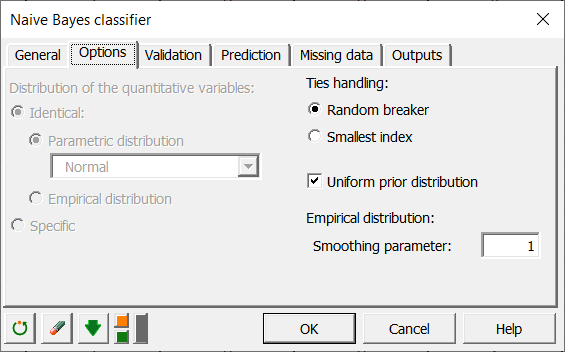
Con el fin de hacer que su clasificador sea más robusto con variables cualitativas la hora de clasificar nuevas observaciones, es posible que desee aplicar un suavizado de Laplace (Laplace smoothing) fijando el parámetro de suavizado a un valor entero distinto de 0. En nuestro caso, vamos a fijar este valor en 1. Por último, activamos los 7 resultados en la pestaña Resultados, como se muestra a continuación.
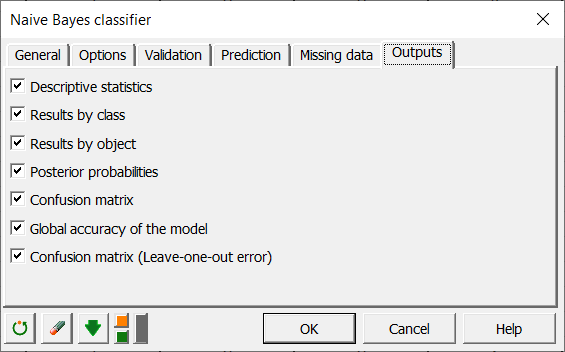
Los cálculos empiezan una vez haya hecho clic en OK.
Interpretación de los resultados de una clasificación Naive Bayes en XLSTAT
Las dos primeras tablas muestran la frecuencia observada y la distribución de frecuencias relativas de la clase de salida y los atributos en la muestra de entrenamiento.
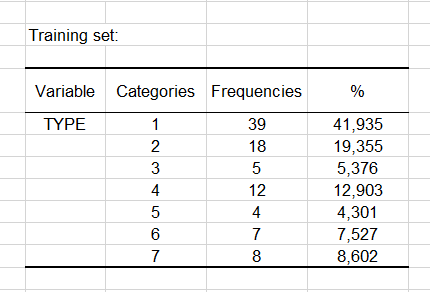
Podemos ver en la primera tabla que la clase de tipo 1 de animales es, con mucho, la más frecuente en la muestra de aprendizaje o entrenamiento con 41.935%. En la siguiente tabla, podemos ver que no se observaron casos de animales con 5 patas en la muestra de aprendizaje.
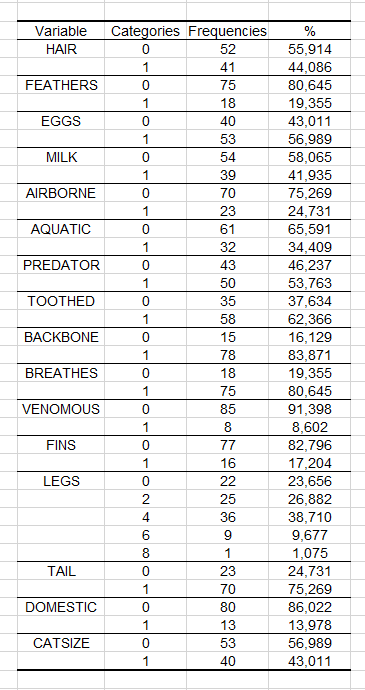 Sin embargo, podemos ver en la siguiente tabla que muestra la distribución de frecuencias observadas en el conjunto de predicción que se ha incluido un animal de patas 5 en el conjunto de predicción.
Sin embargo, podemos ver en la siguiente tabla que muestra la distribución de frecuencias observadas en el conjunto de predicción que se ha incluido un animal de patas 5 en el conjunto de predicción.
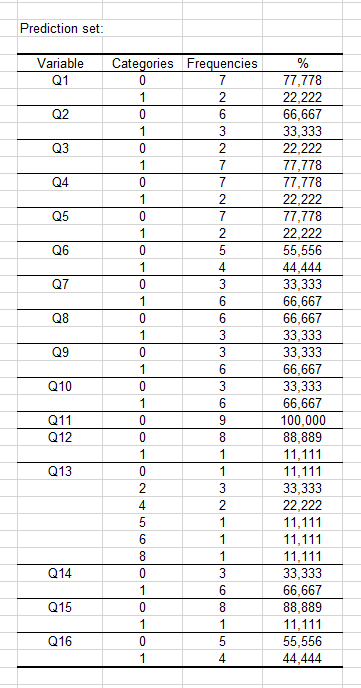
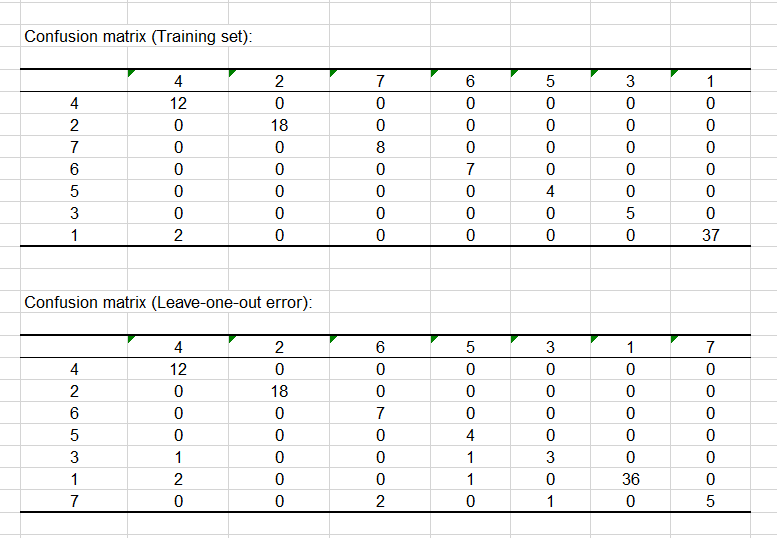
Será interesante ver cómo nuestro clasificador reacciona a esta nueva modalidad que no estaba presente en la muestra de entrenamiento. Pero primero, vamos a echar un vistazo al desempeño de nuestro clasificador en los datos de entrenamiento con las dos matrices de confusión que se muestran a continuación. Podemos ver en la imagen siguiente, que el clasificador presenta una alta tasa de resultados positivos verdaderos en ambas matrices, lo cual es muy alentador.
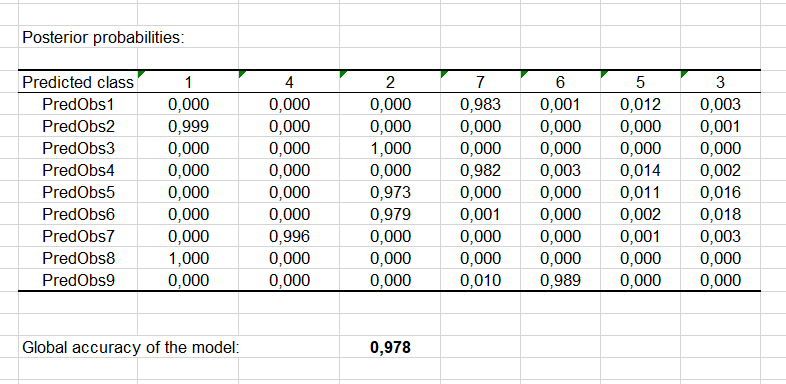
Por último, la clasificación para nuestro conjunto de predicción se visualiza a través de dos tablas como se muestra a continuación:
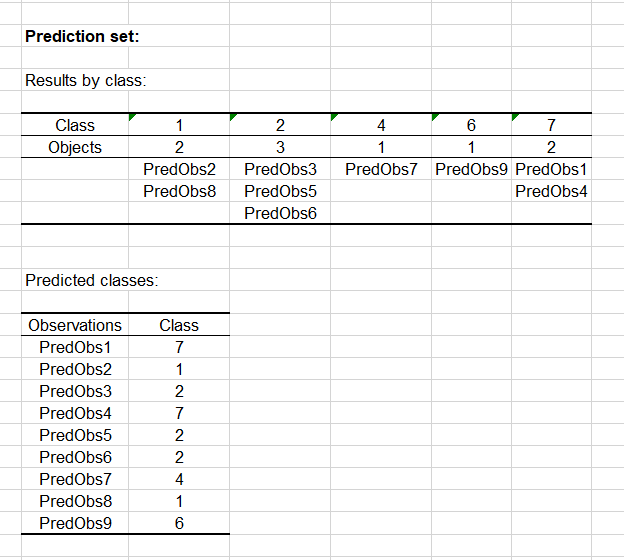 Los resultados se dan por clase en la primera tabla y para cada observación en la segunda pestaña. Podemos ver que la observación marcada PredObs4 se ve afectada una clase de tipo 7.
Este es el animal de 5 patas que mencionamos más arriba. Es una estrella de mar, y de hecho pertenece al tipo 7, junto con el cangrejo, la almeja y el cangrejo de río.
Por lo tanto, gracias al suavizado de Laplace, nuestro clasificador ha etiquetado con éxito esta observación.
Los resultados se dan por clase en la primera tabla y para cada observación en la segunda pestaña. Podemos ver que la observación marcada PredObs4 se ve afectada una clase de tipo 7.
Este es el animal de 5 patas que mencionamos más arriba. Es una estrella de mar, y de hecho pertenece al tipo 7, junto con el cangrejo, la almeja y el cangrejo de río.
Por lo tanto, gracias al suavizado de Laplace, nuestro clasificador ha etiquetado con éxito esta observación.
Por último, se ofrece la probabilidad posterior de cada clase para cada observación del conjunto de predicción:
¿Ha sido útil este artículo?
- Sí
- No