Präferenz-Mapping in Excel durchführen - Anleitung
Dieses Tutorium hilft Ihnen, das Konzept des Präferenz-Mapping zu verstehen, eine Präferenz-Karte in Excel mithilfe von XLSTAT zu zeichnen und zu interpretieren.
Was ist Präferenz-Mapping?
Wir unterscheiden zwei Arten von Präferenz-Mapping-Methoden:
1. Interne Präferenzzuordnung
Diese Methode entspricht der MDPREF (Multidimensional Analysis of Preference Data) und basiert auf einer PCA (Principal Component Analysis), die auf Präferenzdaten mit Produkten in Zeilen (Beobachtungen) und Verbrauchern in Spalten (Variablen) durchgeführt wird. Bei den Daten handelt es sich um die von den Verbrauchern für jedes Produkt abgegebenen Bewertungen. Die Präferenzkarte ist ein biplot (zwei- oder dreidimensional) der Beobachtungen und der Variablen.
Da die Fähigkeit zur Zusammenfassung der Präferenzkarte mit der Anzahl der Verbraucher abnimmt (die Anzahl der zu interpretierenden Achsen steigt), wird manchmal eine nicht-metrische PCA verwendet, um die Anzahl der erforderlichen Achsen zu reduzieren. Die nicht-metrische PCA besteht aus einer monotonen Transformation der Daten, so dass die Variabilität, die durch die k (k=2 oder 3) ersten Achsen erklärt wird, maximiert wird. Diese Transformation impliziert, dass die Bewertungen eine ordinale Bedeutung haben und dass die Abstände oder Verhältnisse zwischen den Bewertungen nicht wichtig sind. Um die Anzahl der Achsen zu reduzieren, können Sie die Verbraucher auch gruppieren und die PCA mit den Gruppen als Variablen durchführen.
Die interne Präferenzzuordnung ermöglicht die Erstellung einer Karte, auf der die Präferenzen der Verbraucher oder Verbrauchergruppen in Form von Vektoren dargestellt sind. 2. Externes Präferenz-Mapping
Diese Methode ermöglicht es, die von den Verbrauchern gezeigten Präferenzen mit bestimmten physikalisch-chemischen, sensorischen oder wirtschaftlichen Eigenschaften der Produkte in Verbindung zu bringen. Dieser Ansatz ist wichtig, da er den Marketing- und F&E-Teams eine zuverlässige Grundlage für die Anpassung oder Entwicklung von Produkten bietet, die den Erwartungen der Verbraucher entsprechen.
Diese Methode erfordert eine zusätzliche Tabelle, die die Produkte mit einer Reihe von Kriterien beschreibt. Im Gegensatz zur internen Präferenzzuordnung besteht der erste Schritt darin, die Produkte auf der Grundlage ihrer Merkmale zuzuordnen.
Dies kann durch die Durchführung einer Hauptkomponentenanalyse (PCA), einer Korrespondenzanalyse (CA) oder einer verallgemeinerten Prokrustes-Analyse (GPA) erreicht werden.
Diese erste Visualisierung wird als sensorische Karte bezeichnet. Unter Anwendung der PREFMAP-Methode modellieren wir dann für jeden Verbraucher (oder jede Gruppe von Verbrauchern) die Bewertungen, die für die Produkte abgegeben wurden, wobei wir als erklärende Variablen die Merkmale der Produkte verwenden, um die Verbraucher auf der sensorischen Karte darzustellen. Das vollständige Modell schreibt:
Y = Si aiXi + Si biXi'² + Sij cijXiXj
Die PREFMAP-Methode verwendet vier Teilmodelle:
· Vektormodell: bi und cij sind Null. Das Modell ist ein Hyperplan. Dieses Modell erlaubt es, die Beobachtungen auf einer sensorischen Karte als Vektoren darzustellen. Die Größe der Vektoren kann mit dem R'² des Modells in Beziehung gesetzt werden; in diesem Fall ist das zugrunde liegende Modell umso besser, je länger der Vektor ist. Die Präferenz des Verbrauchers nimmt zu, je weiter man in Richtung des Vektors geht. Die Interpretation der Präferenz kann durch Projektion der Produkte auf die verschiedenen Vektoren erfolgen (Produktpräferenz). Der Nachteil dieses Modells besteht darin, dass es vernachlässigt, dass bei einigen Kriterien wie Salzgehalt oder Temperatur die Präferenz bis zu einem optimalen Wert ansteigen und dann abnehmen kann;
· Kreisförmiges ideales Punktmodell: Die bi sind gleich und die cij sind null. Das Modell entspricht einer hyperquadrischen Hypersurface. Wenn die Fläche ein Maximum in Bezug auf die Präferenz hat, sprechen wir von einem idealen Punkt. Hat diese Fläche ein Minimum, so spricht man von einem anti-idealen Punkt. Mit dem Kreismodell ist es möglich, Isopräferenzkreislinien um den idealen oder anti-idealen Punkt zu ziehen.
· Elliptisches Idealpunktmodell: Die cij sind Null. Das Modell entspricht einer hyperquadrischen Hypersurface. In diesem Fall sind die Isopreferenzlinien Ellipsen, was die Interpretation der Abstände der Produkte zu den idealen oder anti-idealen Punkten komplexer macht. Wenn die bi entgegengesetzte Vorzeichen haben, gibt es keinen idealen oder anti-idealen Punkt, sondern nur einen Sattelpunkt, dessen Interpretation kompliziert ist.
· Quadratisches Flächenmodell: Dieses Modell entspricht dem vollständigen Modell, dessen Form eine Hypersurface ist. Dieses Modell ermöglicht die Berücksichtigung von Wechselwirkungen zwischen den Merkmalen (cijXiXj).
Wie führt man ein Präferenz-Mapping mit XLSTAT durch?
Das folgende Beispiel zeigt, wie man mit der PREFMAP-Methode eine Präferenzkarte erstellen kann.
· Die Daten zur Verbraucherakzeptanz: 99 Verbraucher bewerteten 10 verschiedene Handelsmuster von Kartoffelchips. Diese Daten wurden dem Artikel von Schlich und McEwan (1992) entnommen. Die Bewertungen wurden von 1 bis 30 eingestuft (30 entspricht der höchsten Akzeptanz). Diese Daten wurden in einer 99 x 10-Tabelle gespeichert.
· Die Durchschnittsbewertungen, die aus den von 8 Experten abgegebenen Bewertungen der 10 Chips-Proben für 4 Textur- und 7 Geschmacksattribute berechnet wurden. Diese Daten, die vom Autor dieses Tutoriums auf der Grundlage des Artikels von Schlich und McEwan (1992) für Unterrichtszwecke simuliert wurden, bilden eine Tabelle im Format 10 x 11.
Schritt 1: Gruppierung der Verbraucher
Wir konzentrieren uns auf die Bewertungen, die von den 99 Verbrauchern abgegeben wurden. Da die Zahl der Verbraucher beträchtlich ist, haben wir beschlossen, sie in homogene Gruppen einzuteilen, um die Interpretation der PREFMAP-Ergebnisse zu erleichtern. Wir haben uns für das Agglomerative Hierarchische Clustering (AHC) entschieden. Da es bereits ein Tutorial zu AHC gibt, gehen wir hier nicht näher darauf ein. Das Dialogfeld des AHC wurde wie unten gezeigt ausgefüllt.
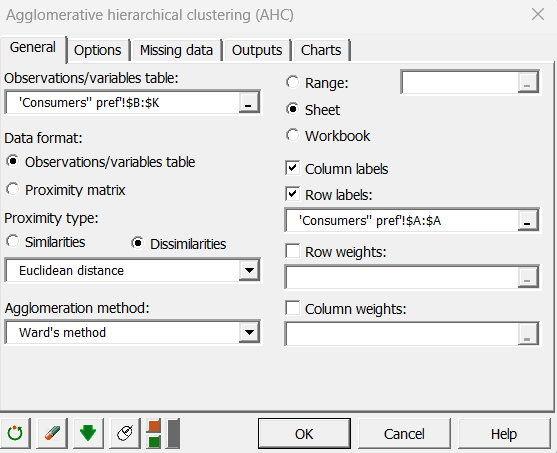
Auf der Registerkarte "Optionen" wurde die Option "Zentrieren/Reduzieren" für "Zeilen" aktiviert, um die Unterschiede zwischen den Beurteilungsskalen der Verbraucher zu verringern. Die Option "Trunkierung" wurde nicht aktiviert.
Betrachtet man das Dendrogramm, so ist es sinnvoll, mit 9 Gruppen zu arbeiten.
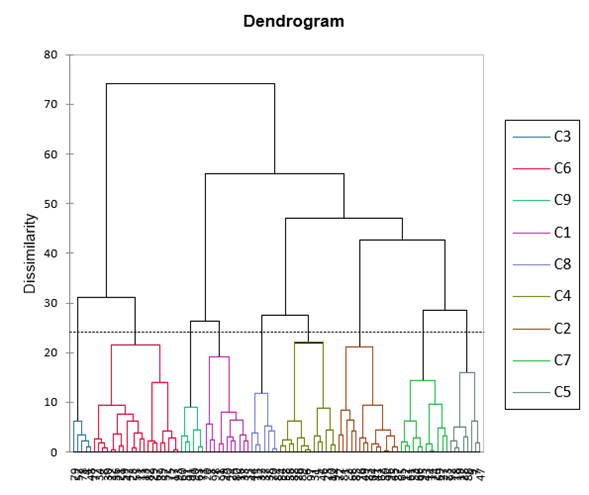
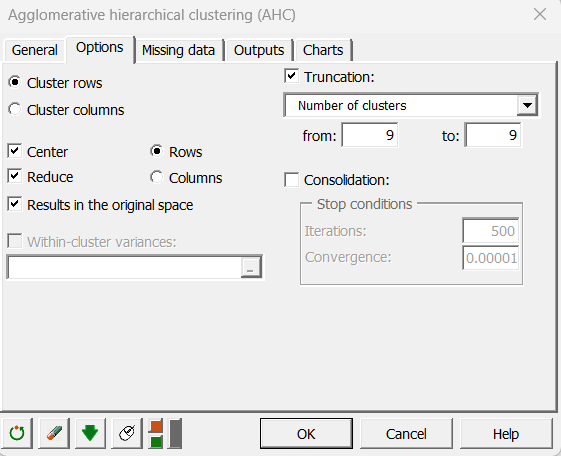
Anschließend führen wir die AHC erneut aus, wobei wir angeben, dass wir 9 Cluster anfordern. Das Dialogfeld wurde wie unten dargestellt ausgefüllt. Der einzige Unterschied zum vorherigen Fall besteht darin, dass wir um eine Trunkierung bitten.
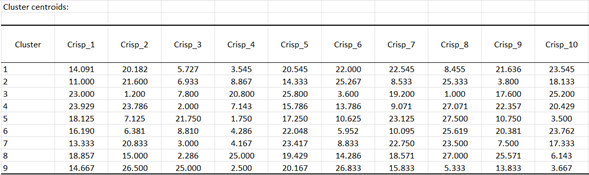
Wir speichern dann die Zentren der Cluster für den letzten Schritt der Analyse. Die Tabelle wird kopiert und in ein neues Blatt mit dem Namen "Clusters' pref." eingefügt (Edit / Paste special with Transposed option).
Schritt 2: Erstellen der Präferenzkarte mit der PREFMAP-Methode
In diesem Abschnitt wenden wir die PREFMAP-Methode an, wobei wir die von den Experten vergebenen Noten und die von den Verbrauchern abgegebenen Bewertungen verwenden, die durch die standardisierten Bewertungen für die 9 Cluster zusammengefasst werden.
Einrichten einer Präferenzzuordnung
Um das Dialogfenster Präferenzzuordnung zu aktivieren, starten Sie XLSTAT und wählen Sie den Befehl XLSTAT / Analyse der sensorischen Daten / Präferenzzuordnung oder klicken Sie auf den entsprechenden Button in der XLSTAT Toolbar (siehe unten).
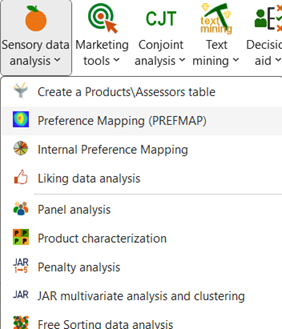
Wenn Sie auf die Schaltfläche klicken, wird das Dialogfeld Präferenzzuordnung angezeigt. Wählen Sie die Daten in der Excel-Tabelle aus. Dem "Y / Präferenzdaten" entsprechen die Bewertungen der 8 Cluster. Das Feld "X / Konfiguration" entspricht den von den Experten abgegebenen Bewertungen. Mit der Option "Vorläufige Transformation" können Sie direkt eine PCA mit den Rohdaten durchführen. Wir haben die Pearson-Methode gewählt.
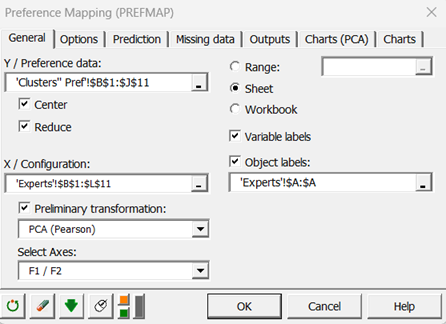
Auf der Registerkarte Optionen wurde zur Auswahl des besten Modells unter den vier möglichen Modellen ein F-Quotient-Test mit einem Signifikanzniveau von 0,1 (10 %) durchgeführt. Das heißt, wenn ein komplexeres Modell keinen F-Quotienten mit einem p-Wert von weniger als 0,1 ergibt, wird das komplexere Modell verworfen.
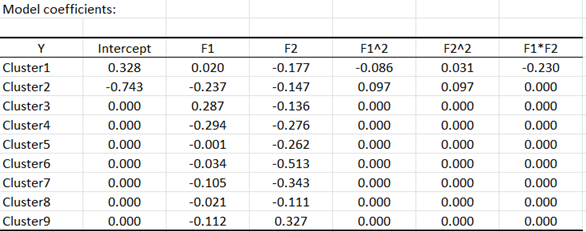
Wir haben die Koeffizienten des Modells ausgewählt, um die Länge der Vektoren auf der Präferenzkarte zu bestimmen.
Interpretation eines Präferenz-Mappings
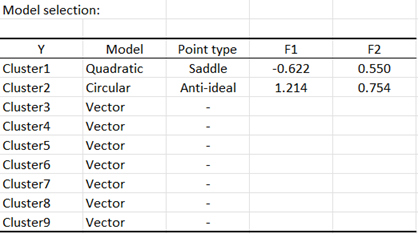
Die Ergebnisse, die wir erhalten (siehe unten), zeigen, dass das Vektormodell das beste Modell für die Cluster 3 bis 9 ist. Für Cluster 1 schneidet das quadratische Modell am besten ab. Es ist jedoch nicht signifikant. Das zirkuläre Modell ist das beste Modell für Cluster 2 und es ist signifikant. Für das quadratische Modell, das für Cluster 1 beibehalten wurde, gibt es keinen Idealpunkt, sondern einen Sattelpunkt. Der Sattelpunkt stellt einen Schwellenwert dar, an dem die Variabilität der Präferenz gering ist, bevor sie schneller zunimmt (oder in die entgegengesetzte Richtung abnimmt). Für Cluster 2 haben wir einen anti-idealen Punkt. Der anti-ideale Punkt entspricht der niedrigsten Präferenz für die Gruppe.
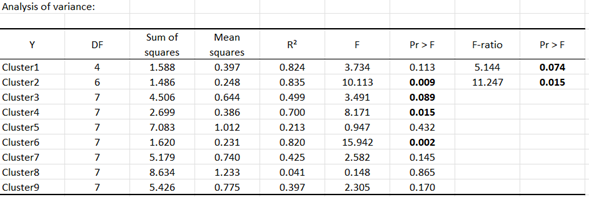
Ein Blick auf die Tabelle der Varianzanalyse zeigt, dass die Modelle nur für die Cluster 2, 3, 4 und 6 signifikant sind.
Die Präferenzkarte ermöglicht eine schnelle Interpretation der Ergebnisse. Betrachtet man sowohl die Präferenzkarte als auch das Konturdiagramm der PCA, so stellt man fest, dass die Verbraucher in Cluster 3 Pommes frites bevorzugen, die nicht schmelzen, sondern zerkocht und knusprig sind. Die Verbraucher aus Cluster 6 mögen knusprige Pommes frites und lehnen fettige Pommes ab. Für Cluster 2 ist es schwer zu sagen, was sie bevorzugen, aber es scheint, dass sie Chips, die nicht salzig und durchschnittlich in allen Kriterien sind (der Punkt liegt nahe am Ursprung), stark ablehnen (Anti-Idealpunkt). Sie mögen auch keine Chips, die nicht künstlich und nicht hart sind.
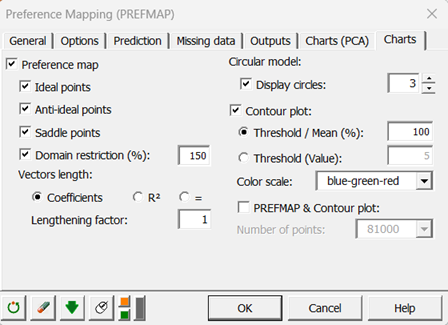
Hinweis: Wenn ein Ideal-/Anti-Ideal-/Sattelpunkt nicht angezeigt wird, weil er sich außerhalb des Darstellungsbereichs befindet, können Sie den Wert der "Bereichsbegrenzung" auf der Registerkarte "Diagramme" des Dialogfelds erhöhen, um den Darstellungsbereich zu erweitern.
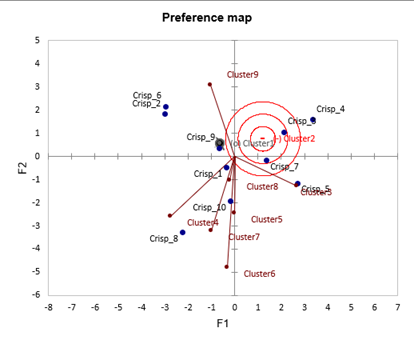
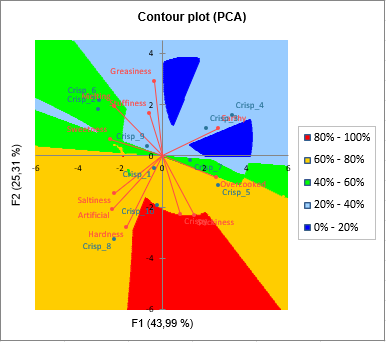
Wenn wir auf den Cluster zoomen, dem ein Anti-Idealpunkt entspricht, können Sie sehen, dass ein graues Kreuz angezeigt wird. Die dickeren Linien entsprechen der Richtung, in der die Präferenz zunimmt, und die dünneren der Richtung, in der sie abnimmt. Je länger die Linie ist, desto stärker ist der Effekt.
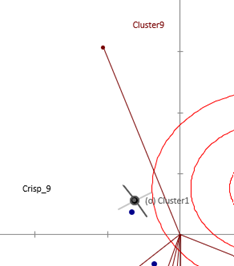
Anhand des Konturdiagramms lässt sich erkennen, wie viele Cluster in einem bestimmten Bereich der Präferenzkarte eine überdurchschnittliche Präferenz aufweisen (diese wird anhand aller angepassten Modelle ermittelt).
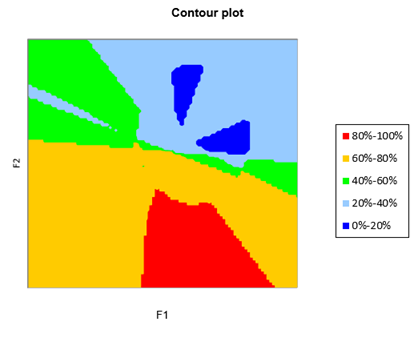
Beide Karten können übereinander gelegt werden. Wählen Sie dazu im Dialogfeld Diagramme die Option PREFMAP & Niveauliniendiagramm.
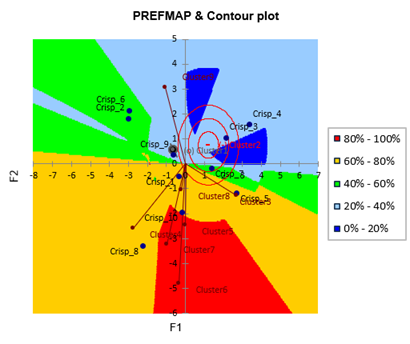
Es werden die Präferenzordnungen für die verschiedenen Verbrauchergruppen angezeigt.
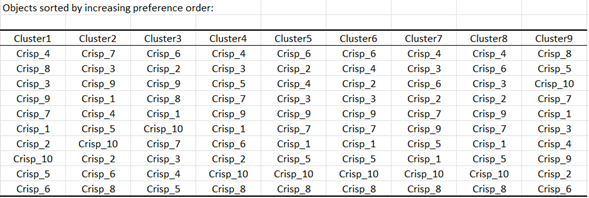
Wir stellen fest, dass die Chips 4, die sich durch einen erdigen, nicht süßen und nicht salzigen Geschmack auszeichnen, von den Gruppen 1, 4, 6, 7 und 8 überhaupt nicht gemocht werden. Chips 8 werden von den meisten Clustern bevorzugt, außer von Cluster 9. Die Marketing- und F&E-Teams können diese Informationen berücksichtigen, um ihre Kreation neuer Chips in die richtige Richtung zu lenken.
War dieser Artikel nützlich?
- Ja
- Nein