Análisis CLUSCATA en Excel
Este tutorial muestra como calcular e interpretar un clustering de materias en una tarea CATA mediante CLUSCATA en Excel usando XLSTAT.
Base de datos para ejecutar el método CLUSCATA
Al principio de este tutorial en el link dado se Los datos usados para ilustrar el método CLUSCATA vienen de un experimento Check-All-That-Apply (CATA) donde 114 consumidores evaluaron 6 fresas usando 16 atributos (Ares & Jaeger, 2013). Los consumidores fueron encuestados para evaluar cuales de los atributos propuestos aplicaron para describir cada una de las fresas.
Objetivo de este tutorial
El objetivo aquí es realizar un análisis de datos de tres pasos:- Segmentar a los sujetos según sus percepciones de los productos. El método CLUSCATA se utilizará para crear las clases más homogéneas posibles.
-
Analizar cada clase de asignaturas utilizando el método CATATIS para determinar las diferencias en las percepciones de las fresas entre clases.
-
Determinar los índices de calidad de la agrupación.
Usaremos la función CLUSCATA para hacer este análisis. Esta herramienta nos permitirá alcanzar los tres objetivos definidos anteriormente.
Configurar un análisis CLUSCATA en XLSTAT
Seleccione XLSTAT/Funciones avanzadas/Análisis de datos sensoriales/función CLUSCATA.

Aparece el cuadro de diálogo de CLUSCATA.

En la pestaña General, seleccione los datos CATA (todos sus datos combinados). El Formato indica cómo fusionó sus datos, horizontal o verticalmente. Si el Formato es horizontal, debe indicar el número de jueces, y si es vertical, Productos y Jueces son obligatorios.
Aquí nuestros datos se fusionan verticalmente y, por lo tanto, seleccionamos los Productos y Jueces. Además, tenemos Etiquetas de los atributos, por lo que marcamos la casilla Etiquetas de atributo para indicarlo a XLSTAT.
En la pestaña Opciones, decidimos dejar automática la elección del número de clases, y aplicar una consolidación de las clases obtenidas por el algoritmo jerárquico para obtener un análisis de conglomerados más preciso.
En la pestaña Gráficos, si selecciona la casilla Mostrar gráficos en los dos primeros ejes, automáticamente tendrá la representación en los 2 primeros ejes factoriales de los diferentes mapas. Si la desmarca, se abrirá una ventana y podrá elegir sus ejes.
Interpretación de los resultados de un análisis CLUSCATA con XLSTAT
El siguiente gráfico es un dendrograma. Representa cómo funciona el algoritmo para agrupar a los sujetos. Como puede ver, el algoritmo ha agrupado con éxito todos los temas. La línea de puntos representa el truncamiento automático, lo que lleva a dos clases.
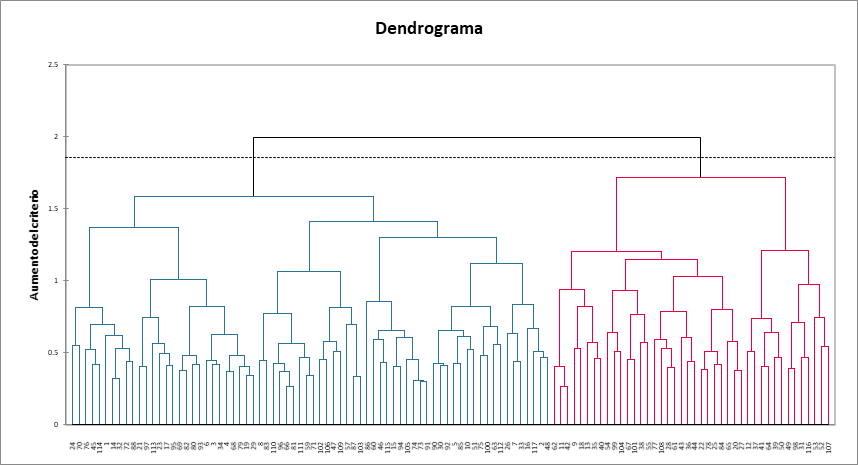
A continuación se presentan tres tablas, con los resultados por grupos por asignatura, por clase y el número de asignaturas de cada clase. Podemos ver aquí que la clase 1 contiene muchas más materias que la clase 2.

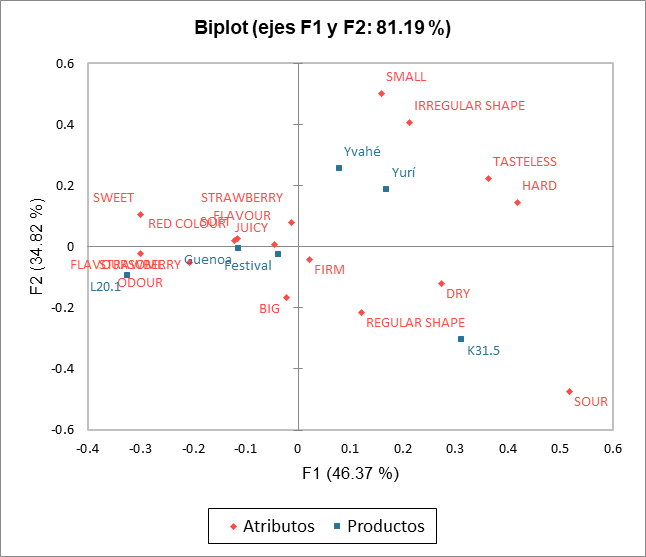
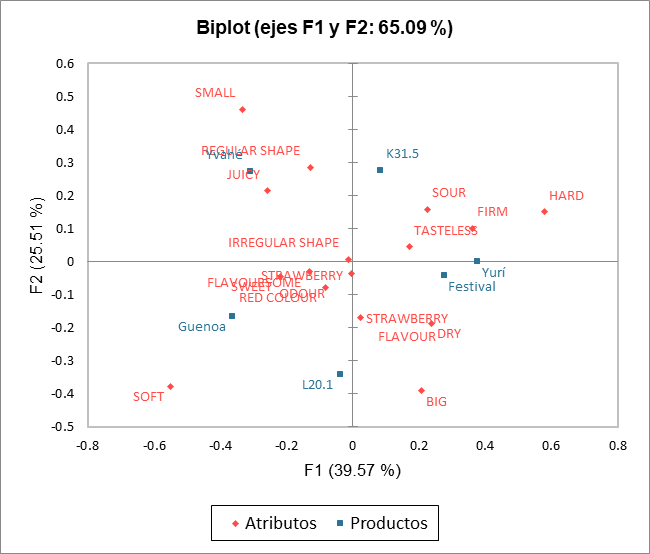
Luego viene el análisis de cada una de las clases construidas. La representación de los productos y atributos en cada clase resalta las diferencias de percepción entre las clases de materias. De hecho, las fresas Yvahé y Yurí se colocan juntas en la clase 1 y se consideran diferentes en la clase 2. También podemos señalar que la fresa Yvahé se considera de forma bastante irregular en la clase 1 y de forma regular en la clase 2.
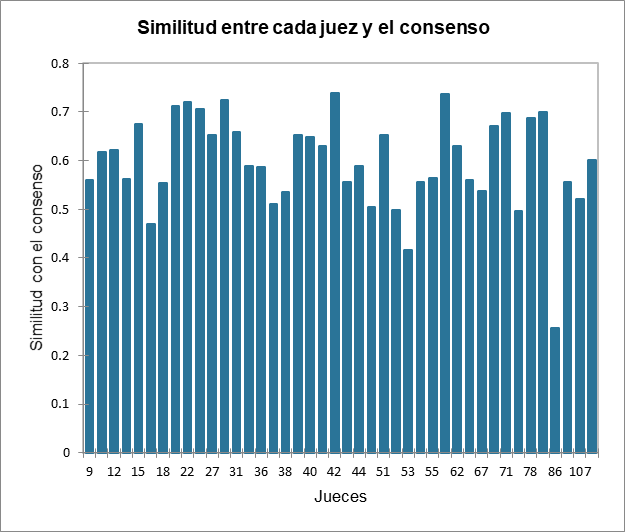
El siguiente gráfico da indicaciones sobre la proximidad de los sujetos y la tabla de consenso de la clase en la que se ubican. Estas proximidades están representadas por el coeficiente s de similitud de Ochiai, que es un índice de similitud entre 0 y 1. En la clase 2, podemos observar que el sujeto 86 está mucho más alejado del consenso que los demás, lo que significa que no se ajusta bien a la clase. Su percepción es diferente a las dos clases (ya que ha sido colocado en la clase que más le corresponde por el algoritmo). Este tipo de problema se puede resolver agregando la clase "K + 1" en la pestaña Opciones, que es una clase adicional diseñada para dejar de lado materias atípicas. En una tarea CATA, es muy frecuente dejar de lado gran parte de las asignaturas con la clase "K + 1". Esto se debe al hecho de que los sujetos a menudo dan resultados muy diferentes.
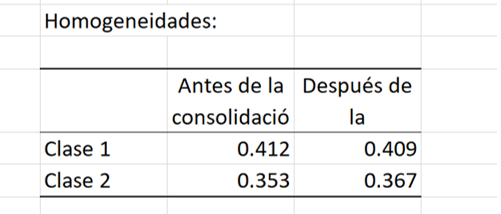
Finalmente, el índice de homogeneidad de cada clase permite evaluar la calidad del análisis de conglomerados. Cuanto más cerca estén estos índices de 1, más homogéneas serán las clases. Aquí vemos que la clase 1 es más homogénea que la clase 2. Esta homogeneidad podría mejorarse con la adición de una clase "K + 1".
¿Ha sido útil este artículo?
- Sí
- No