Análisis de Panel Sensorial: tutorial en Excel
Este tutorial muestra cómo evaluar la calidad de un panel sensorial en Excel usando el software estadístico XLSTAT.
Datos para el análisis de panel sensorial
Los datos utilizados en este tutorial corresponden a la evaluación de 14 botas de esquí diferentes por 15 esquiadores (denominados en adelante evaluadores o jueces) con experiencia en las pruebas sensoriales para la industria textil. Se han utilizado 6 descriptores para llevar a cabop la evaluación de las botas por los 15 evaluadores.
Configuración de un análisis de panel
Una vez activado XLSTAT, seleccione el comando XLSTAT - Análisis de datos sensoriales / Análisis de panel (véase más abajo), o haga clic en el botón correspondiente de la barra de herramientas XLSTAT - Datos sensoriales.

Tras hacer clic en el botón, aparece el cuadro de diálogo.

Seleccione los datos en la hoja de Excel. Puesto que está disponible un factor de sesión, activamos la opción y seleccionamos la columna correspondiente.

Se dispone de varios modelos son posibles dependiendo de si se selecciona una sesión, se desea un modelo con o sin interacciones entre los factores, y si tenemos en cuenta que el evaluador y la sesión (repetición) son efectos fijos o aleatorios. Los factores aleatorios son considerados como variables aleatorias con media 0 y una varianza dada. Esto significa que se tiene en cuenta que, una vez que el efecto del producto es tomado en consideración, los demás efectos son puramente debidos al azar. Esto sólo es válido si se puede considerar que no existe una diferencia estructural entre los evaluadores o entre sesiones. Estas hipótesis se puede comprobar en los análisis que siguen.
Interpretación de los resultados de un análisis de panel
Tras hacer clic en el botón OK, comienzan los cálculos. Llevará algún tiempo el poder acceder a la hoja de resultados, dado que se crean muchos gráficos. Le recomendamos que no haga clic en Excel hasta que se vea de nuevo el cursor.
La primera tabla corresponde a los estadísticos básicos de resumen de las diferentes variables de entrada. Puede usar esta información examinando los valores mínimo y máximo para asegurarse de que no hay valores absurdos en los descriptores.
El primer paso del análisis consiste en ejecutar un ANOVA sobre todo el conjunto de datos para cada descriptor uno después del otro, con el fin de identificar los descriptores para los que no existe efecto del producto. Para cada descriptor, se muestra la tabla de Tipo III SS del ANOVA para el modelo seleccionado. Si no hay ningún efecto del producto para un descriptor, es decir, si el valor de p es mayor que un umbral dado, que descriptor puede ser eliminado del análisis, siempre y cuando la correspondiente opción haya sido señalada en la pestaña Opciones del cuadro de diálogo (Filtrar descriptores no discriminantes). La siguiente tabla corresponde a la tabla de la variable Suavidad.

A continuación, una tabla resumen permite comparar los valores p del efecto del producto para los diferentes descriptores. Los análisis que siguen únicamente serán ejecutados para los descriptores que permiten discriminar los productos, lo que significa para todos los descriptores para los cuales el valor p es menor que 0.05 (que es el valor que hemos introducido en el cuadro de diálogo). En nuestro caso particular, existe un efecto del producto para todos los descriptores, de modo que todos los descriptores permanecen en los siguientes pasos del análisis.

Luego viene la tabla de CAP (Control de Rendimiento de los Evaluadores). Ten en cuenta que esta salida se basa en cálculos de ANOVA y, por lo tanto, solo se genera si cada producto ha sido visto al menos 2 veces, o en otras palabras, si el número de observaciones es mayor que el número de jueces multiplicado por el número de productos. La parte izquierda es un resumen de los descriptores. Están ordenados de acuerdo a su discriminación de producto. Si el valor p es inferior a 0,1, el color es amarillo. Si es inferior a 0,05, el color es verde. De lo contrario, el color es rojo. Es exactamente lo contrario para la interacción producto*evaluador, ya que no es positivo tener una interacción significativa. El promedio del atributo y la raíz cuadrada del error están disponibles en las columnas 3 y 4.
El lado derecho de la tabla se refiere a los evaluadores. Advertencia, si se ha aplicado un filtro, esta parte se mostrará debajo del anterior. Los evaluadores se clasifican según su promedio de clasificación de los efectos producidos individualmente en todos los descriptores. Para un descriptor determinado, si un evaluador no discrimina los productos, tendrá un "=". Si discrimina los productos y está de acuerdo con el panel (prueba de su contribución a la interacción sujeto*producto), tendrá un "+". En caso contrario, se mostrará un "-". Finalmente, si el evaluador tiene un efecto de sesión para el descriptor correspondiente (efectos del humor), o si es significativamente menos fiable que otros jueces de una sesión a otra, se considera no repetible y entonces tendrá un "!" añadido.

El segundo paso consiste en realizar un análisis gráfico. Se muestran gráficos de caja y de “strip” para los 6 descriptores. Podemos ver entonces cómo, para cada descriptor, los diferentes jueces usan una escala de clasificación para evaluar los diferentes productos. En el gráfico de caja para la variable Suavidad podemos ver que los jueces 9 y 15, pese a que tienen una media similar, usan la escala de clasificación de forma distinta. Vemos también que los jueces 3, 4, 5, 6 y 7, pese a que usan rangos de calificación similares, tienden a calificar de forma diferente en términos de posición. Por supuesto, estos gráficos nada nos dicen acerca de la concordancia entre los jueces: podemos ver un caso en el que, aunque los gráficos de caja parecen muy similares, el producto correspondiente al valor mínimo para uno de los jueces (los valores mínimo y máximo se muestran con puntos azules en los gráficos de caja) podría equivaler al máximo otorgado por otro juez.

Ahora queremos comprobar si los evaluadores están de acuerdo en los diferentes descriptores, y cómo los descriptores aportan diferentes posibilidades de calificación (estén o no correlacionados). El tercer paso comienza con la reestructuración de la tabla de datos, con el fin de tener una tabla que contiene una fila por cada producto y una columna por cada par de evaluador y descriptor - si hay varias sesiones, la tabla contiene los promedios - seguido de un PCA en esta misma tabla. El PCA se lleva a cabo sobre los datos estandarizados.
El gráfico que se muestra a continuación corresponde a la misma gráfica de correlaciones PCA replicadas para cada descriptor, destacando en rojo los 15 puntos de los pares (evaluador, descriptor) correspondientes al descriptor mencionado en el título. Esto permite comprobar en un solo paso el grado en que los evaluadores están o no de acuerdo para todos los descriptores, una vez que se elimina el efecto de la posición y la escala (debido a que el PCA se lleva a cabo sobre los datos estandarizados).
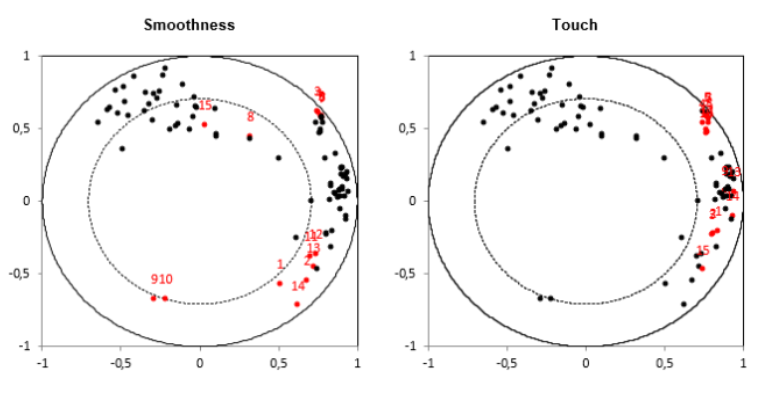
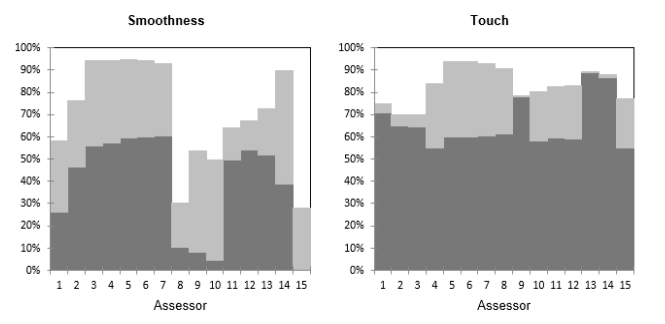
El siguiente gráfico muestra para cada par (evaluador, descriptor) el % de varianza explicado por el gráfico PCA. En gris oscuro se puede ver el % explicado por el primer eje y en gris claro el % de la varianza explicado por el segundo eje. Vemos que para la variable suavidad, hay diferentes grupos de evaluadores, con evaluadores (8, 9, 10) que están más relacionados con el segundo eje, pero aún así mal representados. También podemos confirmar que las variables elasticidad y cierre están próximas y son explicadas por el segundo eje.
Para estudiar con mayor precisión la relación entre descriptores, se muestra un gráfico MFA (análisis de factores múltiples, “Multiple Factor Analysis”) de los descriptores. El MFA se basa en una tabla en la que hay tantas subtablas como descriptores, donde cada subtabla contiene los promedios de cada producto (filas) por cada juez (columnas).

Durante el cuarto paso, se realiza un ANOVA para cada evaluador por separado, y para cada uno de los 6 descriptores, con el fin de comprobar si hay un efecto de producto o no, para verificar para cada evaluador si es capaz de distinguir los productos utilizando los descriptores disponibles. Se muestra una tabla para cada evaluador para evidenciar si hay un efecto del producto o no para los diversos descriptores. Los valores de p se muestran en negrita si son inferiores al umbral definido en la pestaña Opciones del cuadro de diálogo. Los valores p que aparecen en negrita corresponden a los descriptores para los cuales el evaluador era capaz de diferenciar los productos. La siguiente tabla corresponde a la tabla del evaluador 1. Podemos ver que este juez fue capaz de diferenciar los productos utilizando las variables Sensación en los pies y Elasticidad.

Se utiliza a continuación una tabla resumen para contar para cada evaluador el número de descriptores para los cuales fue capaz de diferenciar los productos. Se muestra el porcentaje correspondiente. Este porcentaje es una simple medida de la capacidad de discriminación de los evaluadores. Los porcentajes se muestran en un gráfico de barras.

Para el quinto paso, una tabla global presenta inicialmente las clasificaciones (promediadas sobre las sesiones si se ha seleccionado esa opción) para cada evaluador en filas, y cada par (producto, descriptor) en las columnas. Esta es seguida por una serie de tablas y gráficos para comparar, para cada producto, los evaluadores (promediados sobre las posibles repeticiones) para el conjunto de descriptores. Estos gráficos se pueden utilizar para identificar las tendencias fuertes y las posibles clasificaciones atípicas de algunos evaluadores. La línea roja corresponde al valor promedio de todos los evaluadores para el producto de interés y la línea azul al evaluador seleccionado en la lista en la parte superior izquierda del gráfico. En el siguiente ejemplo podemos ver que el evaluador 10 puntuó al producto 7 por debajo de la media en Suavidad y Tacto, y cerca de la media de los otros descriptores.
El sexto paso permite la identificación de los evaluadores atípicos a través de la medida para cada producto de la distancia euclidiana de cada evaluador a un promedio de todos los evaluadores en el espacio de todos los descriptores. Una tabla que muestra las distancias para cada producto y el mínimo y el máximo calculado en todos los evaluadores, permite la identificación de los jueces que están cerca o lejos del consenso. El siguiente gráfico permite visualizar estas distancias. Cuanto menor sea la distancia, más cercano estará el evaluador al consenso (centroide). El valor 0 corresponde a la media de todos los evaluadores. Si para un producto determinado, todos los evaluadores darían la misma calificación en todos los descriptores, el mínimo y máximo serían 0 para ese producto. Si un evaluador diera exactamente el valor correspondiente a la media obtenida en los otros descriptores, tendríamos un valor mínimo igual a cero para ese producto. En el siguiente ejemplo, vemos que el evaluador 4 no está de acuerdo con los otros evaluadores, excepto en el producto 10 donde su calificación está más cerca de la media.

Puesto que se ha seleccionado la variable “sesión”, el séptimo paso comprueba si para algunos evaluadores existe un efecto sesión, típicamente un efecto de orden. Esto se evalúa usando una prueba de rangos signados de Wilcoxon, ya que tenemos únicamente dos sesiones (en el caso de que tuviéramos 3 o más sesiones, usaríamos la prueba de Friedman). Se calcula la prueba para todos los productos, descriptor por descriptor. Podemos ver en la tabla de más abajo que para 4 de 6 descriptores existe un efecto sesión para el juez 1, de acuerdo con la prueba no paramétrica. Podemos ver asimismo que para la variable Sensación en los pies existe un efecto sesión para 9 de los 15 jueces.

Luego, para cada evaluador y cada descriptor, se calcula cuál es el rango máximo observado entre las sesiones a través de los productos. Se puede ver el producto que corresponde a la distancia máxima poniendo el ratón sobre el triángulo rojo que se muestra en cada celda. Por ejemplo, vemos que hay un rango elevado para el evaluador 15 en la variable Suavidad y que corresponde al producto 8. En nuestro caso particular, vemos aquí que hay rangos altos para la mayoría de los pares de (evaluador, descriptor). Esto hace que la validez de esta encuesta sea cuestionable.

Puesto que para cada combinación triple (evaluador, producto, descriptor) existe al menos una calificación, el octavo paso consiste en una clasificación de los evaluadores. La clasificación se realiza en primer lugar sobre los datos en bruto y, a continuación, sobre los datos estandarizados para eliminar los posibles efectos de escala y posición.


Finalmente, se muestra una tabla preformateada para un análisis procrusteano generalizado (Generalized Procrustean Analysis, GPA) en el caso de que desee llevar a cabo este análisis.
¿Ha sido útil este artículo?
- Sí
- No