Análisis de datos de preferencia con Excel
Este guía muestra como configurar e interpretar un análisis de datos de preferencia en Excel usando XLSTAT.
Los datos provienen de una encuesta sobre 119 personas acerca de sus preferencias entre 5 variedades de manzanas.
Objetivo del tutorial
El objetivo de este tutorial es:
-
determinar qué variedades de manzana son las más populares
-
comparar las variedades de manzana por pares
-
determinar el nivel de acuerdo entre los evaluadores
Para alcanzar estas metas, vamos a utilizar la funcionalidad del análisis de datos de preferencia en XLSTAT.
Configurar el analisis de datos de preferencia en XLSTAT
Seleccione la funcionalidad XLSTAT / Análisis de datos sensoriales / Liking data analysis

El cuadro de dialogo del Liking data analysis aparece.
En la pestaña General, puede seleccionar los datos de preferencia, los productos (manzanas) y los evaluadores.

En la pestaña Opciones, hemos decidido centrar los evaluadores para que no haya un efecto causado por los qué tienen la tendencia a poner mejoras notas. Además, hemos elegido aguparlos.

Las calculaciones empiezan cuando hace clic en OK.
Interpretar los resultados de un análisis de datos de preferencia en Excel con XLSTAT
El primer etapo es la visualización y el análisis antes de centrar los evaluadores. Uno de los resultados que podemos ver es la nota media de los evaluadores antes de centrar (no es necesario de mostrarla despues de centrar porqué sera 0). Podemos ver qué algunos evaluadores tienen una tendencia a poner mejoras notas que los otros, entonces es necesario de centrarlos.

Después de haber centrado los evaluadores, podemos ver los diagramos de caja de los productos. Nos permiten de evaluar la disperción de los datos de preferencia para cada variedad de manzana. Aqui, podemos ver que la manzana 992 ha sido evaluada con mas diferencias de opinion que las otras porqué su rango intercuartil es superior a los otros.

La tabla siguiente contiene el resultado del analisis de la varianza (ANOVA) con los datos de preferencia como variable dependiente y los productos como factor. Nos permite determinar si hay al menos un producto que tiene una media nota diferente de los otros
.

Para determinar las diferencias entre estos productos, podemos observar los siguientes gráficos relacionados con las medias. Es claro que tenemos dos grupos de productos, y qué las manzanas 257 y 548 son mas populares que las manzanas 106, 366, y 992.

La cartografía de las preferencias internas nos permite de determinar, para cada evaluador, los productos preferidos. Aqui podemos ver que, a pesar de que los productos 257 y 548 son los preferidos en los graficos de arriba, no es un consensus (los evaluadores son muy dispersados). Entonces, una clusterización de los evaluadores es una buena idea para estudiarlos en grupos. El dendrográma nos propone 3 grupos de evaluadores.

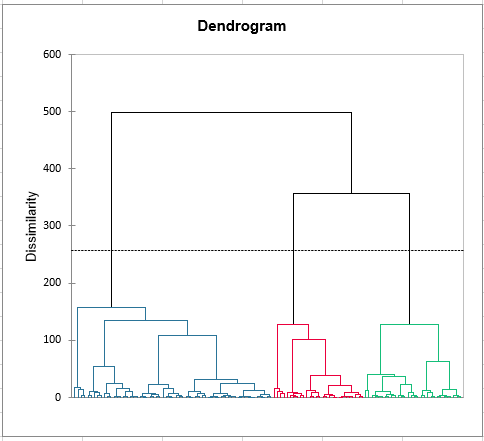
Análisis de las diferencias entre los grupos de evaluadores
La comparación de los grupos de evaluadores es comun en análisis sensorial. Ahora tenemos que aplicar los resultados de la clusterización, pero también se realiza sobre grupos conocidos a priori (por ejemplo hombres y mujeres). Para realizar este análisis, tenemos que seleccionar los datos en forma horizontal en el campo "Liking data" y también los grupos de evaluadores en el campo "Grupos de evaluadores".



Primero, el análisis se realiza para cada grupo, y por ejemplo podemos enfocarnos en las medias de los productos en cada grupo. Podemos ver que al último grupo no le gusta la manzana 257 en contrario de los otros, pero le gusta mas la manzana 366. El segundo grupo se distingue por su aversión hacia la manzana 992.

Ademas, una comparación de los productos por pares se realiza al fin del analisis. Por ejemplo, para la manzana 106, la ANOVA indica que hay una diferencia significativa entre los grupos, y el gráfico de las medias indica que el grupo 1 es diferente de los otros grupos.


Para concluir, hemos empezado con un análisis global de los datos de preferencia. Después, nos hemos dado cuenta qué había una diferencia entre las opiniones de los evaluadores y hemos utilizado el resultado de su clusterización para comparar grupos de evaluadores.
¿Ha sido útil este artículo?
- Sí
- No