Feature extraction tutorial in Excel
This tutorial explains how to extract features vectors from a collection of text documents in Excel using the XLSTAT software.
Feature extraction is used to reduce the amount of resources required to describe a large set of textual data. It is a general term for methods of constructing combinations of the variables to get around these problems while still describing the data with sufficient accuracy. The extracted features are commonly used in methods of document classification where the frequency of occurrence of each word in a document is used as a feature for training a classifier.
Dataset for running a Feature extraction in Excel
In this tutorial, we will use data from the Internet Movie Database (IMBD) which consists of 4000 movie reviews written in English.
Setting up a Feature extraction in Excel using XLSTAT
Once XLSTAT is activated, select the XLSTAT / Advanced features / Text mining / Feature extraction command (see below).
 After clicking the button, the dialog box for the Feature extraction appears.
After clicking the button, the dialog box for the Feature extraction appears.
You can select the data on the Excel sheet either using the Document files option (files importation) or the Worksheet field (cells range selection). The Document labels option is enabled since the first column of data contains the document names.
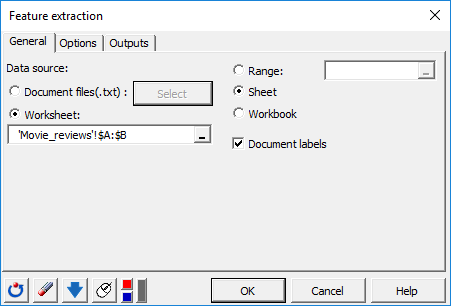 In the Options tab, inside the Preprocessing sub-menu, we choose to exclude a list of stop words (from the English language), delete punctuation marks as well numbers.
In the Options tab, inside the Preprocessing sub-menu, we choose to exclude a list of stop words (from the English language), delete punctuation marks as well numbers.
Text normalization is performed via the Stemming (English) option to reduce words to their common stem (for example the terms "love" - "loving" - "loved" - "lovely" are reduced to the root "lov").
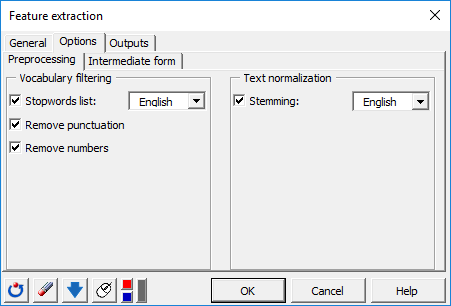 In the Options tab, inside the Intermediate form sub-menu, several options are used to apply filtering at the document-term matrix level.
In the Options tab, inside the Intermediate form sub-menu, several options are used to apply filtering at the document-term matrix level.
We apply a sparsity threshold of 0.95 (95% of sparsity at maximum) via the Remove sparse terms option thus deleting terms whose proportion of presence is lower than 5% over the whole documents (reviews).
A Minimum frequency of 2 is chosen to skip terms occurring less than twice over the whole documents (reviews).
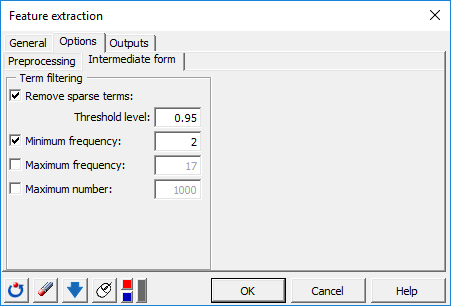 In the Outputs tab, the Document-term matrix option will be activated to display it in the XLSTAT result sheet.
In the Outputs tab, the Document-term matrix option will be activated to display it in the XLSTAT result sheet.
Another option named Export document-term matrix (not selected in our example) allows users to specify a folder path where to export the document-term matrix as comma-separated values (CSV) format.
This option is useful as soon as the number of terms in the matrix exceeds the maximum allowed number of columns that Excel can display in the result worksheet.
 The document-term matrix computation begins once you've clicked OK.
The document-term matrix computation begins once you've clicked OK.
¿Ha sido útil este artículo?
- Sí
- No