Extraction de caractéristique dans Excel
Ce tutoriel explique comment extraire des vecteurs de caractéristiques à partir d'une collection de documents texte dans Excel avec le logiciel XLSTAT.
L'extraction de caractéristique est utilisée pour réduire la quantité de ressources requises pour décrire un grand nombre de données textuelles. C'est un terme générique pour décrire les méthodes de construction de combinaisons de variables pour résoudre cette problématique tout en décrivant les données avec une précision suffisante.
Les "caractéristiques extraites" sont couramment utilisées dans les méthodes de classification de documents dans lesquelles la fréquence d'occurrence de chaque mot dans un document est utilisée comme caractéristique pour l'apprentissage d'un classificateur.
Jeu de données pour réaliser une extraction de caractéristique
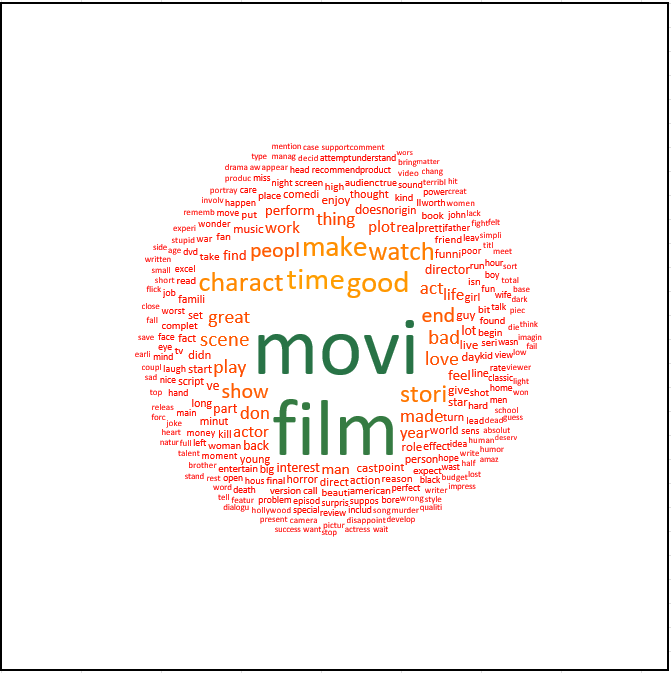
Dans ce tutoriel, nous utiliserons les données provenant de l’Internet Movie Database (IMDB) qui se composent de 4000 critiques de films rédigées en anglais.
Paramétrer une Extraction de caractéristique avec XLSTAT
-
Ouvrir XLSTAT.
-
Sélectionner le menu XLSTAT/ Text Mining / Extraction de caractéristiques. La boîte de dialogue apparaît.
-
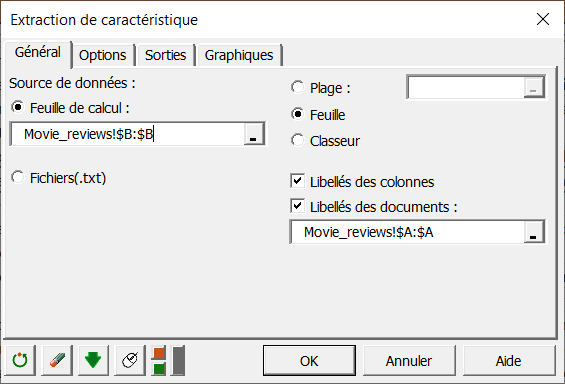
Sélectionner "Review" dans la partie Feuille de calcul.
-
Sélectionner "Id" en tant que Libellés des documents.
-
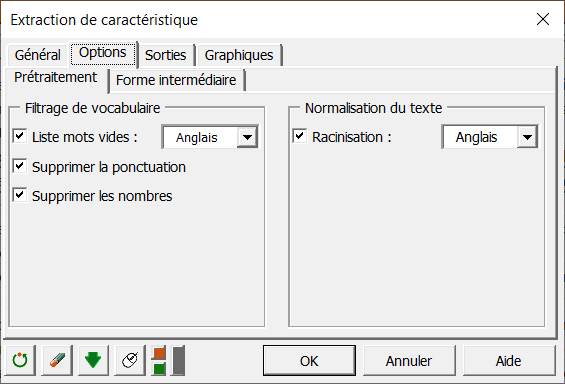
Dans le sous-menu Prétraitement de l'onglet Options :
-
Exclure les mots vides anglais.
-
Supprimer les ponctuations et nombres.
-
Activer l'option Racinisation.
-
-
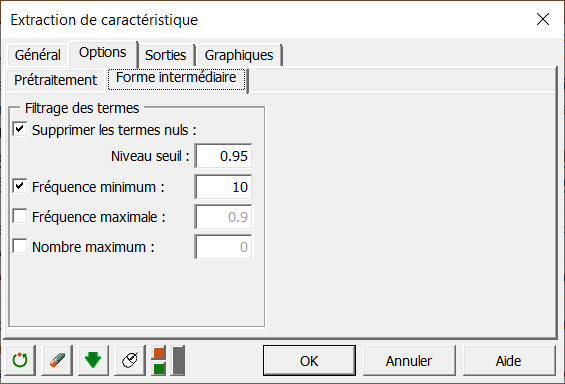
Dans le sous-menu Forme intermédiaire, appliquer un filtre :
-
Activer l'option Supprimer les termes nuls.
-
Entrer 10 en tant que Fréquence minimum.
-
-
Cliquer sur OK.
Interpréter les résultats d’une extraction de caractéristiques
La matrice documents-termes est affichée.
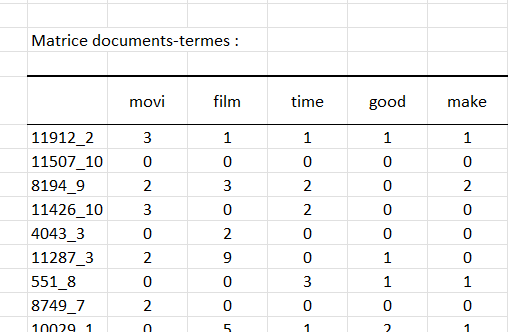
Les termes dont la proportion de présence est inférieure à 5% sur l’ensemble des critiques ont été supprimés.
Les termes qui apparaissent moins de 10 fois sur l’ensemble des critiques ne sont pas présents dans la matrice documents-termes générée.
Le nuage de mots qui représentent la fréquence des mots présents dans toutes les critiques, est affiché à la suite de la matrice documents-termes.
Cet article vous a t-il été utile ?
- Oui
- Non