Analyse de données de Tri Libre (Free Sorting) dans Excel
Ce tutoriel explique comment réaliser et interpréter une analyse de données de Tri Libre avec Excel en utilisant XLSTAT.
Jeu de données de Tri Libre
Les données utilisées pour illustrer l’analyse de Tri Libre se rapportent à une expérience où 25 consommateurs (sujets) de Product Perceptions Ltd ont gouté 14 chocolats différents et en ont fait des groupes.
Ces données sont précisément décrites dans Courcoux, P., Faye, P., & Qannari, E. M. (2014). Determination of the consensus partition and cluster analysis of subjects in a free sorting task experiment. Food Quality and Preference, 32, 107–112.
But de ce tutoriel
Le but ici est d’étudier deux caractéristiques des données de Tri Libre :
- les proximités et différences entre les produits, c’est-à-dire les chocolats ici.
- les accords entre les consommateurs, de façon individuelle et globale.
Pour cela, nous utiliserons la fonction Analyse de données de Tri Libre de XLSTAT. Cet outil nous permettra de visualiser les liens entre les produits, ainsi que de calculer des indices de similarité entre les consommateurs. Enfin, une représentation graphique des consommateurs sera également proposée.
Paramétrer la boîte de dialogue de l’Analyse de données de Tri Libre
Une fois XLSTAT lancé, sélectionnez le menu XLSTAT / Fonctions avancées / Analyse de données sensorielles/ Analyse de données de Tri Libre.

La boîte de dialogue Analyse de données de Tri Libre apparaît.
 Dans l’onglet Général, vous pouvez alors sélectionner les données de Tri Libre.
Dans l’onglet Général, vous pouvez alors sélectionner les données de Tri Libre.
La Méthode indique votre choix sur la stratégie que vous préférez adopter. STATIS utilisera la méthode indiquée à la suite d’un prétraitement adapté. AFC sur la matrice de cooccurrence réalisera une Analyse Factorielle des Correspondances sur la matrice de cooccurrence des produits. Enfin, ACM utilisera une Analyse des Correspondances Multiples sur les données brutes saisies.
Ici nos consommateurs (sujets) contiennent des libellés, nous cochons donc la case Libellés des sujets pour l’indiquer à XLSTAT. De plus, nous sélectionnons les Libellés des produits de l’expérience.
Dans l’onglet Sorties, si vous sélectionnez la case Analyse des sujets, vous aurez dans un second temps une analyse basée sur la proximité des réponses des différents sujets afin d’en faire une représentation graphique.
Dans l’onglet Graphiques, si vous sélectionnez la case Graphiques sur deux axes, vous aurez automatiquement la représentation des différentes cartes sur les 2 premiers axes factoriels. Si vous le décochez, une fenêtre s’ouvrira alors et vous pourrez choisir vos axes.
Interpréter les résultats d’une analyse de données de Tri Libre
Un des résultats les plus important de l’analyse de données de Tri Libre est la représentation graphique des produits. Sur le graphique suivant nous pouvons voir d’une part que nous avons 31.18% d’inertie expliquée par les deux premiers axes, ce qui est très commun dans le cas de variables qualitatives. Il est conseillé cependant de regarder les axes 3 et 4, mais dans notre cas aucune information supplémentaire ne nous est donnée. Le graphique montre que les sujets ont globalement trouvé 5 groupes de chocolats. De plus, il est clair que le groupe constitué de Divine et Green&Blacks ainsi que celui contenant JSValue et TescoValue sont complètement éloignés des autres.
 L’homogénéité est un indicateur global (entre 1/nombre de sujets et 1) de l’accord entre les consommateurs. Ici elle est de 0.639, ce qui est correct mais montre qu’il y a quand même quelques différences de point de vue entre les consommateurs.
L’homogénéité est un indicateur global (entre 1/nombre de sujets et 1) de l’accord entre les consommateurs. Ici elle est de 0.639, ce qui est correct mais montre qu’il y a quand même quelques différences de point de vue entre les consommateurs.
![]()
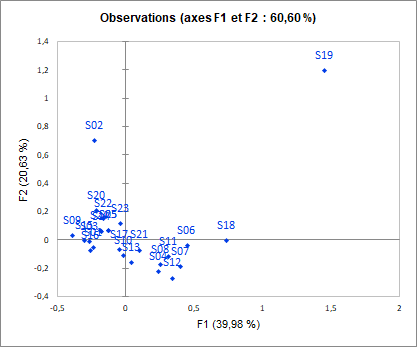
Afin d’étudier plus précisément ces différences de point de vue entre consommateurs, l’analyse des sujets permet de les représenter. Nous voyons clairement dans nos données que le sujet S19 a un point de vue complètement à part des autres sujets. Une solution pourrait être d’enlever ce sujet et de recommencer l’analyse.
Cet article vous a t-il été utile ?
- Oui
- Non