Analyse discriminante PLS-DA dans Excel
Ce tutoriel explique comment mettre en place et interpréter une analyse discriminante par les moindres carrés partiels PLS-DA dans Excel en utilisant XLSTAT.
Jeu de données pour réaliser une analyse discriminante par les moindres carrés partiels - PLS-DA
Les données proviennent de [Fisher M. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7, pp 179 -188] et correspondent à 150 fleurs d'Iris, décrites par 4 variables quantitatives (longeur des sépales, largeur des sépales, longueur des pétales, largeur des pétales), et par leur espèce.
Trois différentes espèces font partie de cette étude : setosa, versicolor and virginica. Notre but est de tester si les quatre variables descriptives permettent de distinguer les espèces, puis de représenter les données dans l'espace factoriel, afin de vérifier visuellement si les espèces sont bien discriminées.
Paramétrer une Analyse Discriminante PLS
Pour effectuer une analyse discriminante PLS, il faut activer la boîte de dialogue de la régression PLS. Lancez XLSTAT, puis sélectionnez la commande Régression PLS de la barre d'outils Modélisation des données.
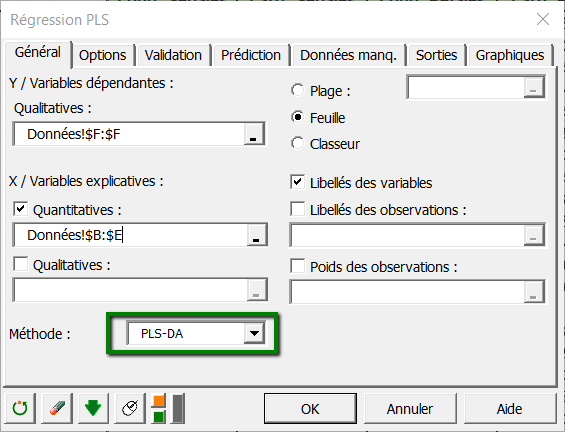
Une fois que vous avez cliqué sur le bouton, la boîte de dialogue apparaît. Sélectionnez au niveau des Variables dépendantes (le "Y" du modèle), la variable associée aux espèces.
Ce sont en effet les données que l'on veut expliquer au travers des Variables explicatives quantitatives (les "X" du modèle) que sont les descripteurs physiques des fleurs.
Sélectionnez la méthode PLS-DA afin d'effectuer une analyse discriminante PLS.
Puis cliquez sur l'onglet Options et vérifiez que Automatique est bien la condition d'arrêt sélectionnée.
Une fois que vous avez cliqué sur le bouton OK, les calculs commencent puis les résultats sont affichés.
Interpréter les résultats d'une analyse discriminante par les moindres carrés partiels - PLS-DA
Les premiers résultats de l'analyse discriminante correspondent à ceux de la régression PLS dans laquelle les variables dépendantes correspondent aux modalités de la variable espèce.
Après quelques statistiques de base sur les différentes variables sélectionnées (les variables explicatives sont en noir, et les variables dépendantes en bleu) et la matrice de corrélations correspondante, les résultats propres à la régression PLS sont affichés.
Le premier tableau et le graphique correspondant permettent de visualiser la qualité de la régression PLS en fonction du nombre de composantes retenues.

L'indice Q² cumulé est une mesure globale de la qualité de l'ajustement et de la qualité prédictive des 3 modèles (un pour chaque espèce). XLSTAT a automatiquement retenu 4 composantes. On voit que l'indice Q² reste faible. Cela suggère que la qualité de l'ajustement peut être très variable en fonction des espèces.
Les R²Y cum et R²X cum qui correspondent aux corrélations entre les composantes et les variables de départ sont proches de un dès la quatrième composante, ce qui indique que les composantes sont à la fois bien représentatives des X et des Y.
Le premier graphique des corrélations permet de visualiser sur les deux premières composantes générées par l'analyse discriminante PLS les corrélations entre X et les Y du modèle.

Ce graphique nous permet de voir la répartition des espèces et des variables explicatives sur un plan.
Une fois les résultats classiques de la régression PLS analysés, des résultats spécifiques à l'analyse discriminante PLS sont affichés.
Le tableau suivant liste pour chaque fleur, le classement a priori et le classement obtenu à partir du modèle. On remarque que les observations (3, 5) ont été reclassées. If peut y avoir plusieurs raisons pour cela: soit la personne qui a fait mes mesures a fait une erreur d'enregistrement, soit les iris correspondant à ces données ont eu une croissance anormale pour des raisons inconnues, soit le critère de classement utilisé par le spécialiste n'est pas correcte, soit il manque de l'information pour discriminer parfaitement les espèces entre elles.

Sur le graphique suivant sont affichés les individus sur les axes t. Ce graphique permet de confirmer que les individus sont bien discriminés sur les axes t obtenus à partir des variables explicatives initiales.

La matrice de confusion résume l'information concernant les reclassements d'observations, et on peut en déduire les taux de bon et mauvais classement. Le "% correct" correspond au rapport du nombre d'observations bien classées, sur le nombre total d'observations.

XLSTAT vous permet donc d'appliquer un modèle d'analyse discriminante PLS de manière simple. On peut, de plus, prédire la classe associé à de nouvelles observations et utiliser un échantillon de validation afin de valider le modèle.
Cet article vous a t-il été utile ?
- Oui
- Non