Déployer une fonction R dans Excel avec XLSTAT-R
Ce tutoriel décrit chacune des étapes à suivre pour déployer une fonctionnalié R avec XLSTAT-R.
Pour faire fonctionner XLSTAT-R dans votre environnement XLSTAT, veuillez tout d'abord consulter ce tutoriel.
Réaliser une régression basée sur les rangs dans Excel - XLSTAT
Pour ce tutoriel, nous choisissons de travailler sur la fonction rfit du package {Rfit}. Elle permet d'estimer des coefficients basés sur le rang pour les modèles linéaires. Ces estimations sont considérées comme plus robustes que les méthodes d'estimation plus classiques, en ce qui concerne les valeurs aberrantes.
Les paramètres d'entrée de la fonction rift sont :
-
une variable dépendante quantitative
-
des variables qualitatives ou quantitatives indépendantes (explicatives)
Nous ajouterons également la possibilité d'afficher un graphique représentant les coefficients de régression. Nous utiliserons pour cela le moteur graphique de XLSTAT.
Etape 1 : Ouvrir le fichier XML et remplir la Structure de la section "Method"
Les fonctionnalités XLSTAT-R sont codées avec le langage XML. Une documentation détaillée sur la syntaxe XML de XLSTAT-R est disponible ici. Le code XML complet lié à ce tutoriel est disponible ci-dessus.
Pour commencer à développer notre fonctionnalité, nous avons besoin d'ouvrir un fichier XML depuis XLSTAT-R. Pour cela, cliquez sur l'onglet XLSTAT-R / Ouvrir un fichier XML vierge.
Le fichier s'ouvre dans votre éditeur de texte par défaut selon le chemin spécifié dans l'onglet Options XLSTAT-R. Cependant, nous vous recommandons fortement d'éditer vos fichiers XML en utilisant l'éditeur Sublime (Windows et Mac) ou Notepad+++ (Windows seulement).
Notez qu'il est également possible de démarrer votre projet à partir d'une fonctionnalité déjà existante. Cela peut être utile lorsque la fonctionnalité que vous souhaitez développer a une structure d'entrée ou de sortie similaire à celle qui a déjà été développée dans XLSTAT-R. Les fonctionnalités existantes sont généralement stockées à cette adresse : %AppData%\ADDINSOFT\XLSTAT\XLSTAT-R\groups
Il est maintenant temps de remplir les attributs liés à la structure Method. La structure Method est la racine de votre projet de fonctionnalité XLSTAT-R. Ici, vous devez définir des attributs importants tels que le nom de votre fonctionnalité, la structure des données d'entrée, les bibliothèques R qu'elle utilisera, etc.
Pour remplir les attributs et les sous-nœuds de la section Method, remplacez les exemples de texte entre les quotes.

Remplissez les attributs de la structure Method comme suit :
-
text="Rank-Based Regression". Il s'agit du nom de votre fonctionnalité.
-
datastructure="model". Cette structure implique que les données seront fusionnées dans une formule R. Elle est spécifique aux fonctions R qui impliquent des variables dépendantes et indépendants ou prédictives, comme la fonction rfit. Pour les structures de données régulières, saisissez simplement "data".
-
function="rfit". Il s'agit du nom de la fonction R que vous déployez ou du nom de votre propre procédure.
-
group="Rfit". Il s'agit du nom du menu sous lequel votre fonction sera mémorisée dans le menu déroulant d'XLSTAT-R. Ce sera également le nom du dossier dans lequel vous enregistrerez votre projet XML.
-
packages="Rfit". Inclure ici la liste des packages qui doivent être chargés pour que votre fonctionnalité marche. Pour inclure plusieurs packages, il faut les séparer par des virgules. Pour inclure, par exemple, le package plotrix qui permet de générer des diagrammes R avec des barres d'erreur, il faut écrire packages="Rfit,plotrix".
-
family="Robust Linear Modeling". Attribut optionnel.
-
question="How can I obtain robust linear model estimates?". Attribut optionnel.
-
synonyms="Robust regression". Attribut optionnel.
Remplissez les sous-nœuds de la structure Method comme suit :
-
<AuthorXML>John Smith</AuthorXML>. Indiquer le nom de l'auteur du fichier XML.
-
<AuthorRFunction>John Kloke</AuthorRFunction>. Entrer ?rfit dans R pour connaître le nom de l'auteur de la fonction R.
-
<CompatibilityXLSTAT>19.5</CompatibilityXLSTAT>. Indiquez ici la version XLSTAT sous laquelle vous développez la fonctionnalité. Vous pouvez la trouver en allant dans XLSTAT / A propos de XLSTAT.
-
<CompatibilityR>3.4.2</CompatibilityR>. Indiquez ici la version R que vous utilisez. Elle peut être trouvée lorsque vous ouvrez la console R.
-
<DateCreated>2017.09.29</DateCreated>. Indiquez ici la date à laquelle vous avez créé votre fichier XML.
-
<DateModified>2017.09.29</DateModified>. Indiquez ici la date à laquelle vous avez modifié votre fichier XML. Assurez-vous d'actualiser cette date chaque fois que vous postez une nouvelle modification à votre fonctionnalité.
-
<PackageVersion>rfit 0.23.0</PackageVersion>. Indiquez ici la version du package que vous utilisez. Vous pouvez la trouver en chargeant les packages dans votre console R et en exécutant la commande sessionInfo(). Si vous avez plusieurs packages, séparez-les par des points virgules (par exemple, rfit 0.23.0**;** plotrix 3.6-6).
-
<RDescription>Minimizes Jaeckel's dispersion function to obtain a rank-based solution for linear models.</RDescription>. Inclure ici la description de la fonctionnalité que vous pouvez trouver dans la section Description des pages d'aide des fonctions R.
Etape 2: Sauvegarder votre fichier XML
Localisez votre répertoire de travail XLSTAT-R\groups. Il est généralement situé dans %AppData%\ADDINSOFT\XLSTAT\XLSTAT-R\groups
Créez un dossier Rfit et enregistrez votre modèle XML sous rfit.xlm. Le nom du dossier doit correspondre à l'attribut group de la structure Method et le nom du fichier XML doit correspondre à l'attribut function.
Tout au long du processus de développement, nous vous conseillons vivement de vérifier l'évolution de votre projet dans l'interface XLSTAT-R. Pour ce faire :
-
Sauvegardez votre fichier.
-
Ouvrez XLSTAT puis allez dans le menu R et cliquez sur Actualiser.
-
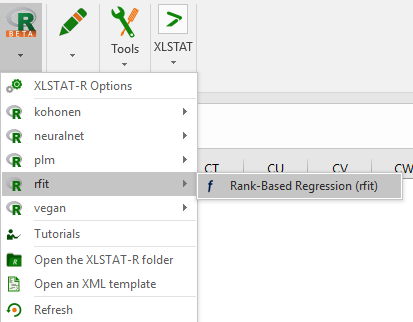
Ouvrez votre fonctionnalité dans le menu R.
Etape 3: Déterminer ce qu'il faut inclure dans l'interface utilisateur
Déterminer les paramètres d'entrée
La première question que l'on peut se poser ici est : quelles sont les entrées à inclure dans l'interface utilisateur XLSTAT-R (c'est-à-dire la boîte de dialogue) ? Pour un projet aussi simple que celui-ci, nous décidons d'utiliser les arguments de la fonction R comme entrées. Examinons ces arguments.
Ouvrez la console R, chargez la bibliothèque Rfit et l'aide de la fonction rfit en tapant les lignes de commande suivantes :
> library(Rfit)
> ?rfit
Dans la documentation d'aide, sous la section Usage, vous trouverez la fonction avec les principaux arguments associés et une explication de chaque argument :
rfit(formula, data, subset, yhat0 = NULL, scores = Rfit::wscores, symmetric = FALSE, TAU = "F0", ...)
Dans ce tutoriel, nous allons introduire des données qui seront automatiquement fusionnées par XLSTAT dans une formule R grâce à la structure de données du model dans le moteur XLSTAT-R. Nous laisserons également l'utilisateur manipuler l'argument booléen symmetric ainsi que l'argument TAU.
Déterminer les onglets à inclure dans la boite de dialogue
L'interface utilisateur (la boite de dialogue) est configurée sous la section <!-- START USER INTERFACE -->.
L'interface utilisateur est organisée en onglets. Ici, nous décidons d'inclure la structure classique de la boîte de dialogue XLSTAT : Général, Options, Données manquantes, Sorties et Graphiques.
Etape 4: Configurer l'onglet General
Nous commençons par configurer l'onglet Général. Dans cet onglet, nous voulons principalement inclure :
-
Une entrée de variable dépendante quantitative;
-
Entrées de variables explicatives quantitatives;
-
Entrées de variables explicatives qualitatives;
-
En option, étiquettes d'observation.
Pour configurer un champ permettant de saisir les données, vous pouvez utiliser le nœud général DataField. Cependant, XLSTAT-R comporte des noeuds spécifiques pour traiter les données qui doivent être fusionnées dans une formule R. Ces nœuds ont l'avantage de permettre à l'utilisateur de configurer les modalités et les interactions à inclure dans la formule à l'aide d'une boîte de dialogue point-and-click. Nous utiliserons ces noeuds spéciaux.
L'onglet est lancé en utilisant le code suivant :
<Tab text="#General" >
Ici nous utilisons le signe # car la chaîne de caractère General est traduite en plusieurs langues dans XLSTAT. Le code XML recherche la chaîne de caractères dans le dictionnaire XLSTAT et l'affiche dans la boîte de dialogue avec le langage configuré XLSTAT.
Tapez le code suivant:
<YQuantiField text="Dependent variable" controltip="Select your dependent variable" rname="data" />
<Spacer height="2" />
<XQuantiField rname="data" optional="true" optiondefault="true" />
<XQualiField rname="data" optional="true" optiondefault="false" />
-
YQuantiField est le nœud spécifique d'XLSTAT-R qui configure un champ de saisie pour la sélection de variables dépendantes quantitatives. L'attribut text définit la légende qui apparaîtra dans la boîte de dialogue. L'attribut controltip définit le curseur qui apparaît lorsque l'utilisateur passe la souris sur le champ. L'attribut rname définit le bloc de données R dans lequel les données sélectionnées seront stockées.
-
Spacer est le nœud utilisé pour séparer les éléments de la boîte de dialogue les uns des autres. L'attribut height est défini en pixels.
-
XQuantiField et XQualifield sont les nœuds spécifiques d"XLSTAT-R qui configurent les champs de saisie pour la sélection des variables explicatives quantitatives et qualitatives, à inclure dans la formule R. Ces noeuds incluent par défaut les valeurs des attributs text. L'attribut optional ajoute une case à cocher (checkbox) à ces champs de saisie pour les rendre facultatifs. L'attribut optiondefault définit la valeur par défaut de la case à cocher.
Voici à quoi ressemble l'interface utilisateur à ce stade :

Il est maintenant temps de configurer la deuxième partie de l'onglet Général. Tapez le code suivant :
<NextColumn />
<VarHeaders text="Variable labels" />
<Spacer height="10" />
<ObsLabelsField rname="data" />
<Spacer height="6" />
</Tab>
-
NextColumn permet de basculer vers le côté droit de la boîte de dialogue dans l'onglet courant.
-
VarHeaders est une case à cocher spécifique d'XLSTAT qui indique si les noms des variables ont été sélectionnées ,ou non, lors de la sélection des données.
-
ObsLabelsField est également un champ de données spécifique d'XLSTAT dans lequel l'utilisateur peut sélectionner des noms de ligne ou d'observation. Ici, les libellés sélectionnés seront introduits tels quels dans l'objet de données R.
-
</Tab> ferme la configuration de l'onglet Général.
Voici l'onglet Général complété :

Il est maintenant temps de configurer l'onglet Options.
Etape 5: Configurer l'onglet Options
Ici, nous décidons d'inclure un contrôle sur les Interactions et les arguments symmetric et TAU que l'utilisateur souhaite inclure dans la fonction rfit .
-
Symmetric est un argument booléen (TRUE ou FALSE). L'utilisation d'une checkbox est appropriée dans cas.
-
TAU peut prendre une valeur parmi une liste limitée de valeurs. L'utilisation d'une combobox est appropriée dans cas.
<Tab text="#Options" >
<Interactions reportgroup="1" />
<CheckBox text="Symmetric" name="SymmetricAnalysis" rname="symmetric" default="false" reportgroup="2" />
<Spacer height="6" />
<ComboBox text="Routine" name="Routine" rname="TAU" default="0" left="55" width="100" reportgroup="3" >
<Item text="Fortran" rname="F0" />
<Item text="R" rname="R" />
<Item text="None" rname="N" />
</ComboBox>
<Spacer height="6" />
</Tab>
-
Interactions est un nœud préconfiguré spécifique d'XLSTAT qui permet à l'utilisateur de sélectionner le niveau d'interactions dans la boîte de dialogue principale. Après avoir cliqué sur OK, une autre boîte de dialogue permet à l'utilisateur de sélectionner les interactions spécifiques qu'il souhaite inclure. L'attribut optionnel reportgroup inclut cette entrée dans le résumé de configuration du rapport de résultats. Le niveau d'interaction sera le premier élément "1" à afficher dans l'en-tête du rapport (sommaire de configuration).
-
L'argument symmetric du nœud CheckBox contient plusieurs attributs. name est le nom interne de XLSTAT-R. rname est l'objet R dans lequel l'entrée sera stockée Par défaut, cette case à cocher produira un objet R nommé symmetric et contenant la valeur FALSE.
-
Le nœud Combobox qui définit la valeur de l'argument TAU de R inclut les membres de l'élément. Chaque élément contient un élément de la liste des éléments possibles de l'argument. Dans chaque élément, l'attribut text définit le texte qui sera affiché dans la liste déroulante. L'attribut rname contient la valeur qui sera stockée dans l'objet TAU si l'élément est sélectionné. L'attribut par défaut dans le nœud ComboBox contient l'index de l'élément à utiliser par défaut. Cet indice commence à 0. Dans ce cas, la valeur par défaut sera "F0". left définit le nombre de pixels par lequel le contrôle doit être déplacé vers la gauche. width définit la largeur du contrôle en pixels.

Etape 6: Configurer l'onglet données manquantes
Nous choisissons de conserver l'onglet données manquantes par défaut dans le fichier XML. Ce sont des options XLSTAT spécifiques pour le traitement des données manquantes. Pour plus d'informations, reportez-vous à la documentation de XLSTAT-R.
<Tab text="#Missing" leftcolumnwidth="220" >
</Tab>
Il est utile d'ajouter la possibilité ignore dans la liste pour les méthodes capables d'ignorer les données manquantes.

Etape 7: Configurer les onglets Sorties et Graphiques
Dans ce tutoriel, nous choisissons de conserver le code XML des onglets sorties et graphique tels qu'ils sont dans le fichier original. Cela générera automatiquement des options de checkbox dans les onglets en fonction de ce qui est spécifié dans la section SPECIFICATION OF RESULTS TO DISPLAY IN EXCEL (étape 9).
Voici le code:
<!-- OUTPUTS TAB OF THE DIALOG BOX -->
<Tab text="#Outputs" >
<AutoOutputs stats="true" />
</Tab>
<!-- CHARTS TAB OF THE DIALOG BOX -->
<Tab text="#Charts" >
<AutoCharts />
</Tab>
Dans le nœud AutoOutputs, l'attribut stats indique que le moteur XLSTAT doit calculer et afficher des statistiques descriptives sur les données sélectionnées.
Avant de passer à la section de configuration du rapport des résultats (c'est-à-dire la spécification des résultats à afficher dans Excel), nous vous proposons de passer à la section Code R au bas du fichier XML. Une fois le code configuré, nous reviendrons à la configuration des résultats.
Etape 8: Ecrire le code R
Sélection des résultats d'analyse à afficher dans les sorties
Le format d'objet R le plus simple d'XLSTAT-R capable d'afficher les résultats est data frames . Jetons un coup d'oeil au résultat de la fonction rfit de base pour voir comment nous pourrions extraire un data frames. Ouvrez une console R et retournez à la section d'aide rfit. Copiez et collez le code dans la section Exemples en bas.
> library(Rfit)
> ?rfit
> data(baseball)
> data(wscores)
> fit<-rfit(weight~height,data=baseball)
> summary(fit)
Call:
rfit.default(formula = weight ~ height, data = baseball)
Coefficients:Estimate Std. Error t.value p.value(Intercept) -228.57144 56.14659 -4.0710 0.000146 ***height 5.71429 0.76018 7.5171 4.373e-10 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Overall Wald Test: 56.50621 p-value: 0
Le tableau des coefficients vaut la peine d'être affiché, car il comprend à la fois les estimations (première colonne) et les valeurs p associées (dernière colonne).
Voyons comment nous pourrions extraire ce tableau spécifique. Conseil : la fonction names() permet souvent de vérifier les éléments que vous pouvez extraire à partir d'objets R complexes.
> names(summary(fit))
[1] "coefficients" "waldstat" "waldpval" "overall.test" "call"
Peut-être que l'élément coefficients contient ce que nous cherchons.
> summary(fit)$coefficients
Estimate Std. Error t.value p.value
(Intercept) -228.571442 56.1465857 -4.070977 1.459710e-04
height 5.714286 0.7601755 7.517061 4.373127e-10
Succès ! Vérifions si cela correspond à une data frame :
> is.data.frame(summary(fit)$coefficients)
[1] FALSE --> Ce n'est pas le cas.
Par conséquent, la transformation ci-dessous sera nécessaire à un moment donné dans le code :
> as.data.frame(summary(fit)$coefficients)
Rédaction du code : quelques notes préliminaires
L'écriture du code R est généralement effectuée dans la dernière section du fichier XML (R CODE), sous le nœud RScript. Le nœud RScript comprend des sous-nœuds ScriptLine dans lesquels vous pouvez insérer des lignes de commande R.
Il y a deux façons d'écrire du code R dans XLSTAT-R. Vous pouvez passer d'un code à l'autre en utilisant l'attribut booléen replacebyvalue dans le nœud RScript.
-
replacebyvalue="true": XLSTAT-R remplace automatiquement les rnames trouvés dans le code XML par leurs valeurs chaque fois qu'ils sont appelés dans les ScriptLines, et lorsque l'attribut replace dans les ScriptLines est mis à TRUE. Cette méthode est utile chaque fois que vous souhaitez programmer rapidement les fonctions XLSTAT-R en imitant les fonctions R. Elle présente des limites si vous souhaitez manipuler des objets R dans un code R plus complexe visant à produire des résultats supplémentaires.
-
replacebyvalue="false": XLSTAT-R stocke automatiquement les entrées de la boîte de dialogue dans les objets R, ce qui permet une manipulation plus souple du code R.
Dans ce tutoriel, nous allons utiliser la première méthode pour écrire du code R dans les templates XLSTAT-R.
Ecrire le code en utilisant replacebyvalue="true".
Tapez le code suivant :
<RScript replacebyvalue="true" >
<ScriptLine replace="true" code="results=rfit(formula,data,symmetric,TAU)" />
<ScriptLine replace="true" code="results$CoefficientsDataFrame=as.data.frame(summary(results)$coefficients)" />
</RScript>
Il y a deux lignes de script. La première appelle la fonction rfit de R. L'objet de formula est généré automatiquement par XLSTAT grâce à la structure de données Model. Avec la méthode replacebyvalue="true", tous les éléments insérés après sont remplacés par leurs valeurs saisies dans la boîte de dialogue à chaque exécution de la boîte de dialogue.
Dans le fichier XML, les résultats R à afficher doivent être stockés dans un objet de résultats. C'est pourquoi nous avons créé l'objet results dans la première ligne et le sous-objet CoefficientsDataFrame dans l'objet de résultats.
Voici un script R typique généré avec ce code. Ce script est automatiquement généré dans le répertoire de travail XLSTAT-R chaque fois que vous exécutez la fonctionnalité de XLSTAT. Le fichier script est susceptible de se trouver ici : %AppData%\ADDINSOFT\XLSTAT\XLSTAT-R\datastore\Rfitresults\rfit.script.R
> list.of.packages <- c('Rfit')
> new.packages<-list.of.packages[!(list.of.packages %in% installed.packages()[,'Package'])]
> if(length(new.packages)) install.packages(new.packages, repos='http://cran.us.r-project.org')
> library('Rfit');
> data<-read.csv(file='%AppData%/ADDINSOFT/XLSTAT/XLSTAT-R/datastore/data.csv', header=TRUE, sep=';', dec='.')
> results<-rfit(weight ~ +height,data,symmetric=FALSE,TAU='F0')
> results$CoefficientsDataFrame<-as.data.frame(summary(results)$coefficients)
> write.table(results$CoefficientsDataFrame, file = %AppData%/ADDINSOFT/XLSTAT/XLSTAT-R/datastore/Rfitresults/CoefficientsDataFrame.csv', na='', row.names =TRUE, quote=FALSE, sep=';', dec=',')
Jetez un coup d'oeil à la ligne de commande rfit() et voyez comment les éléments ont été remplacés automatiquement.
Etape 9: Configurer de l'affichage des sorties dans Excel
Il est maintenant temps de revenir à la section de configuration du rapport des résultats (c'est-à-dire la spécification des résultats à afficher dans Excel). Cette section comprend le nœud RResults . Il inclut autant de sous-nœuds de résultat qu'il y a de résultats à afficher dans les sorties.
Insérez le code suivant:
<RResults>
</RResults>
-
text: définit le titre du résultat dans les sorties;
-
rname: élément de l'objet de résultats à afficher, typiquement data frame;
-
type: type de données stockées dans les éléments rname;
-
rowlabels: libellés des lignes de résultat à afficher. S'il est défini à rdesc, les libellés de ligne d'objet R sont utilisés;
-
collabels: libellés des colonnes de résultats à afficher. S'il est défini à rdesc, les libellés de colonne d'objet R sont utilisés;
-
chartname (facultatif): le nom du graphique à afficher, basé sur ce résultat;
-
charttype: le type de graphique à afficher (voir la documentation pour plus d'informations). Le barchart (0/1) affiche un histogramme. Le zéro (0) signifie que les libellés des lignes du tableau seront utilisées comme libellés des barres, et le (1) signifie que la première colonne sera utilisée comme données à afficher (estimations du coefficient).
Ce code affichera le tableau des coefficients ainsi qu'un diagramme à barres des coefficients avec XLSTAT.
Il est tout à fait possible de produire un graphique équivalent en R, en utilisant le code suivant à la place :
<RResults>
<Result text="Coefficients" rname="CoefficientsDataFrame" type="double" rowlabels="rdesc" collabels="rdesc" chartname="Coefficients chart, R style" charttype="r" rplotformat="emf" rplotcode="barplot(results$CoefficientsDataFrame[,1], names.arg=row.names(results$CoefficientsDataFrame), ylab='Estimates', xlab='Coefficients',main='Coefficients Bar Chart')" />
</RResults>
Consultez à présent l'onglet Sorties et Graphiques. Vous remarquerez que les checkboxs sont apparues automatiquement :


Au bas du fichier XML, n'oubliez pas de fermer la structure Method en utilisant le code ci-dessous:
</Method>
Etape 10 : Profitez de votre nouvelle fonctionnalité dans XLSTAT!
Voici quelques captures d'écran de la fonctionnalité exécutée sur l'ensemble de données ANCOVA. Vous pouvez télécharger les données ci-dessus.
Ouvrir R / Rfit / Rank-Based Regression
Remplissez l'onglet général comme suit:

Activez l'option Interactions dans l'onglet Options.
Cliquez sur OK.
Dans la boîte de dialogue qui apparaît, sélectionnez les variables à inclure :

Sélectionnez les variables que vous souhaitez conserver et cliquez sur OK.
Interpréter les résultats.

Cet article vous a t-il été utile ?
- Oui
- Non