Comment interpréter des résultats contradictoires entre une ANOVA et des tests de comparaisons multiples
Cet article explique comment interpréter des résultats contradictoires entre une ANOVA et des comparaisons multiples par paires. Deux exemples exécutés dans XLSTAT sont présentés. Les données utilisées ont été simulées artificiellement.
Quelques mots sur les outils de comparaisons multiples par paires
Pourquoi faire des comparaisons multiples par paires ?
L’ANOVA permet de détecter la présence d'effets statistiquement significatifs d’un facteurs sur une variable dépendante. Par exemple, dans le cadre d’une étude visant à tester l’effet d’un facteur impliquant 4 traitements médicaux sur la pression artérielle, un test d’ANOVA répondrait à la question très générale : existe-t-il au moins un traitement significativement différent des autres sur le plan statistique ? Si le test d’ANOVA se solde par un effet significatif, une autre question peut être soulevée : quels traitements précis sont significativement différents les uns des autres ? Cette question exige la mise en œuvre de tests de différences entre des paires de traitements pris deux à deux.
La problématique des comparaisons multiples
Les outils de comparaisons multiples par paires impliquent généralement le calcul d’une p-value pour chaque paire de modalités comparées. La p-value représente le risque de rejeter l'hypothèse nulle (H0=groupes proviennent de la même population) alors qu'elle est vraie. Plus le nombre de paires à comparer augmente, plus le nombre de p-values calculées augmente, entraînant par conséquent une amplification du risque de déclarer des effets significatifs à tort. En considérant un seuil de significativité de 5%, on trouverait 5 p-values significatives par pur hasard sur 100 effets détectés comme significatifs. Pour résoudre ce problème, les outils de comparaisons multiples par paires mettent en place des corrections des p-values : ces dernières sont pénalisées (= leurs valeurs sont augmentées) à mesure que leur nombre s’accroît. La méthode de pénalisation diffère d’un outil à l’autre.
Interprétation des résultats contradictoires entre une ANOVA et des comparaisons multiples par paires
Les calculs d’une ANOVA et d’un test de comparaisons multiples reposent sur différentes techniques. Il arrive que les résultats générés par ces deux outils soient contradictoires.
Comparaisons multiples non-significatives suite à une ANOVA significative
Ces résultats sont constatés quand : - La p-value du tableau d’ANOVA est égale ou inférieure au niveau de significativité alpha.
- Toutes les p-values associées aux comparaisons multiples par paires sont supérieures au niveau de significativité alpha.
Un exemple est affiché ci-dessous : 
Cela se produit surtout lorsque :
- Les échantillons (groupes) sont de petite taille. Dans ce cas, la puissance statistique du test de comparaisons multiples n’est pas assez élevée pour détecter des différences significatives.
- Le nombre de modalités est élevé. Plus le nombre de paires à comparer augmente, plus le nombre de p-values calculées augmente, entraînant par conséquent une amplification de la pénalisation de ces p-values.
- L’effet global est faible autrement dit, la p-value est égale ou proche au niveau de significativité.
- Le test de comparaisons multiples utilisé est très conservateur.
La liste n’est cependant pas exhaustive. D’autres situations existent.
Comparaisons multiples significatives suite à une ANOVA non-significative
Ces résultats sont constatés quand :
- La p-value du tableau d’ANOVA est supérieure au niveau de significativité alpha.
- Au moins une p-value associée aux comparaisons multiples par paires est inférieure au niveau de significativité alpha.
Un exemple est affiché ci-dessous :
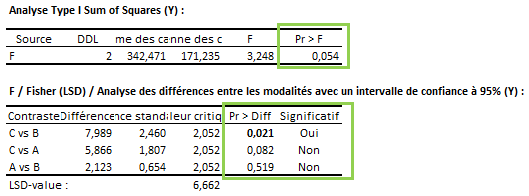
Dans certains cas, le test de comparaisons multiples peut être plus puissant que le test global. Il est alors possible de détecter des différences significatives alors que la p-value d’ANOVA est supérieure au niveau de significativité. En général, nous pouvons nous fier aux résultats des comparaisons multiples malgré un effet global non-significatif sauf si le test de protected Fisher LSD est utilisé.
'An unfortunate common practice is to pursue multiple comparisons only when the hull hypothesis of homogeneity is rejected'. (Hsu, page 177).
Cet article vous a t-il été utile ?
- Oui
- Non