Mehrfachkorrespondenzanalyse (MKA) in Excel
Dieses Tutorium wird Ihnen helfen, eine multiple Korrespondenzanalyse in Excel mithilfe der Software XLSTAT einzurichten und zu interpretieren.
Sie sind nicht sicher, ob dies das richtige Tool für die multivariate Datenanalyse ist, das Sie benötigen? Weitere Hinweise finden Sie hier.
Datensatz für die Durchführung einer multiplen Korrespondenzanalyse
Die Daten entsprechen einer Umfrage eines Autoverkäufers, bei der 28 Kunden jeweils 5 Fragen beantworteten eine Woche nach der Abholung Ihres Wagens nach einer mechanischen Reparatur. Die Fragen waren:
-
Sind Sie generell zufrieden mit dem Service? (Ja/Nein)
-
Sehen Sie das Problem als behoben an? (Ja/Nein/Unklar)
-
Wie beurteilen Sie die Begrüßung? (1 bis 5)
-
Ist das Qualität-Preisverhältnis zufriedenstellend? (Ja/Nein)
-
Werden Sie erneut unser Kunde sein? (Ja/Nein/Unklar)
Ziel dieses Tutorials
Durch eine multiple Korresponzanalyse (MKA) wird versucht die Beziehungen zwischen den verschiedenen möglichen Antworten der Fragen zu identifizieren.
Einrichten des Dialogfensters multiple Korrespondenzanalyse
-
Ach dem Öffnen von XLSTAT, wählen Sie den Befehl XLSTAT/Analyse der Daten /Mutliple Korrespondenzanalyse.
-
Nachdem auf den Button geklickt wurde, erscheint das Dialogfenster der multiplen Korrespondenznanlyse.
-
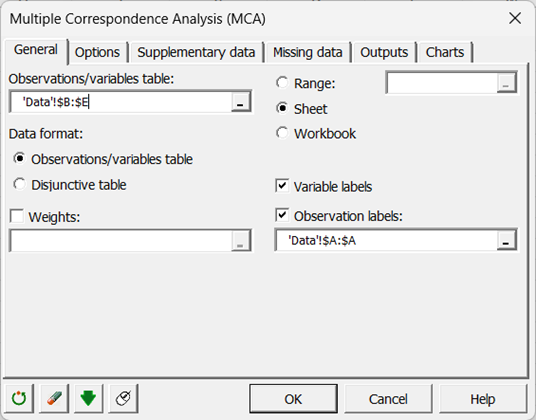
Die Daten entsprechen hier einer Beobachtungen/Variablen-Tabelle.
-
Die “Beschriftungen der Beobachtungen” werden im entsprechenden Feld ausgewählt und die Option “Variablenbeschriftungen” bleibt aktiviert, da die erste Zeile der Tabelle die Namen der Variablen enthält.
-
Im Tab Optionen wählen Sie die Option 1/p als Filteroption aus: Detaillierte Ergebnisse zu Faktoren, deren Eigenwert kleiner als 1/p (wobei p die Anzahl der aktiven qualitativen Variablen ist) sind, werden nicht angezeigt.
-
Im Tab Zusätzliche Daten: Die Variable Come back wird als zusätzliche Variable verwendet, da wir nicht möchten, dass sie die Berechnungen beeinflusst; jedoch möchten wir wissen, wie die Kategorien dieser Variablen auf der Korrespondenzkarte positioniert sind.
-
Im Tab Outputs wählen Sie die Disjunktive Tabelle und Eigenwerte aus.
-
Die Berechnungen beginnen, sobald Sie auf OK geklickt haben. Die Ergebnisse werden dann angezeigt.
Interpretieren der Ergebnisse einer multiplen Korrespondenzanalyse
XLSTAT zeigt zunächst Tabellen an, die in den Berechnungen gebraucht werden (Vollständig disjunktive Tabelle und Burt-Tabelle).
Die Gesamtträgheit ist gleich 2. In der MKA hängt die Gesamtträgheit ausschließ von der Anzahl der Variablen und Kategorien ab und nicht etwa von den Beziehungen zwischen den Variablen. Daher ist dieser Wert statistisch nicht interpretierbar.
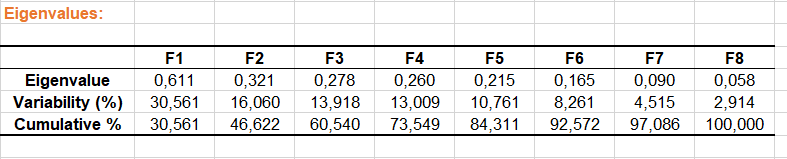
In der darauf folgendenden Tabelle werden die Eigenwerte ungleich Null und die entsprechenden Prozentsätzer der Trägheit angezeigt. Im Gegensatz zur Korrespondenzanalyse (KA) sind die Prozentsätze nicht interpretierbar in Hinblick auf die Qualität der Repräsentation, einzig wichtiges Element für den Benutzer der Methode. Greenacre et al (2005) schlagen den Gebrauch einer angepassten Trägheit von, die näher an der Wirklichkeit ist. Wenn die klassische Berechnung ein Ergebnis von lediglich 46,6% mit den beiden ersten Achsen ergibt, so sieht im hier, dass die Methode der angepassten Trägheit hier 87,3% ergibt.
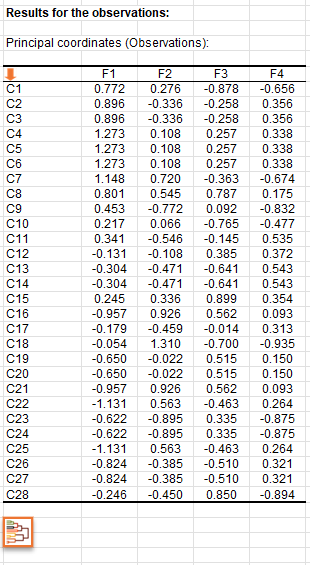
Dann zeigt eine Tabelle die Koordinaten der Kategorien im Faktorrraum an. Die Ergebnisse, die der zusätzlichen Variable entsprechen, werden in blauer Farbe angezeigt. Die Koordinaten der Beobachtungen werden weiter unten angezeigt.
Die Beiträge, die Testwerte und die quadrierten Kosinuswerte helfen bei der Interpretation der Ergebnisse. Bevor man interpretiert, dass zwei Kategorien auf der Karte nah beieinander liegen, sollte man überprüfen, ob ihr Beitrag zu den Achsen der Karte oder ihre quadrierten Kosinuswerte hoch sind.
Die drei folgenden Diagramme entsprechen jeweils der Karte der Kategorien, der Karte der Beobachtungen und dem Biplot, das sowohl die Koordinaten der Beobachtungen als auch der Kategorien auf den ersten beiden Achsen enthält.
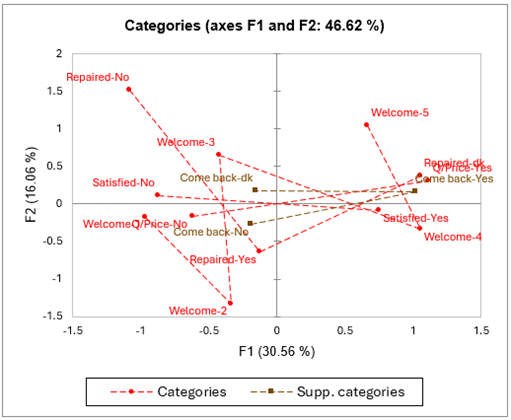
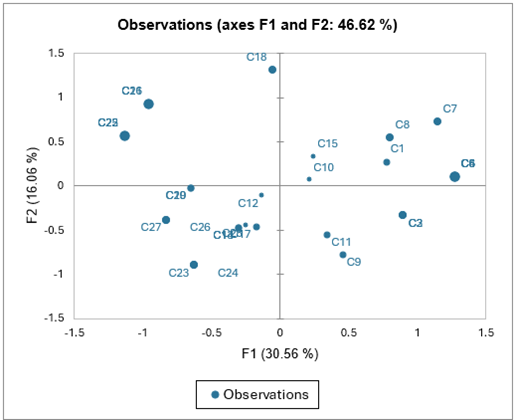
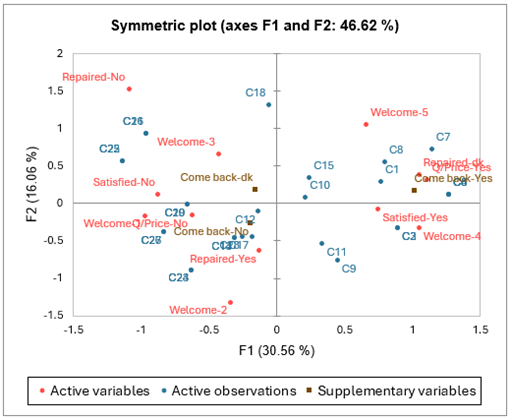
Aus diesen Diagrammen kann man vermuten, dass ein Kunde nur zurückkommt, wenn er mit der Intervention, dem Empfang und dem Preis zufrieden ist. Es fällt auch auf, dass es einen Zusammenhang zwischen der Unzufriedenheit mit der Reparatur und einem schlechten Empfang zu geben scheint. Dies sollte weiter untersucht werden: Hat der Kunde das Problem möglicherweise nicht präzise beschrieben, weil er schlecht empfangen wurde, oder hat der Kunde erneut angerufen, um zu berichten, dass das Problem weiterhin bestand und er von dem Vertreter schlecht behandelt wurde?
Weiterführende Analyse
Durchführen einer Agglomerativen Hierarchischen Clusteranalyse (AHC) nach einer Multiple Korrespondenzanalyse (MCA)
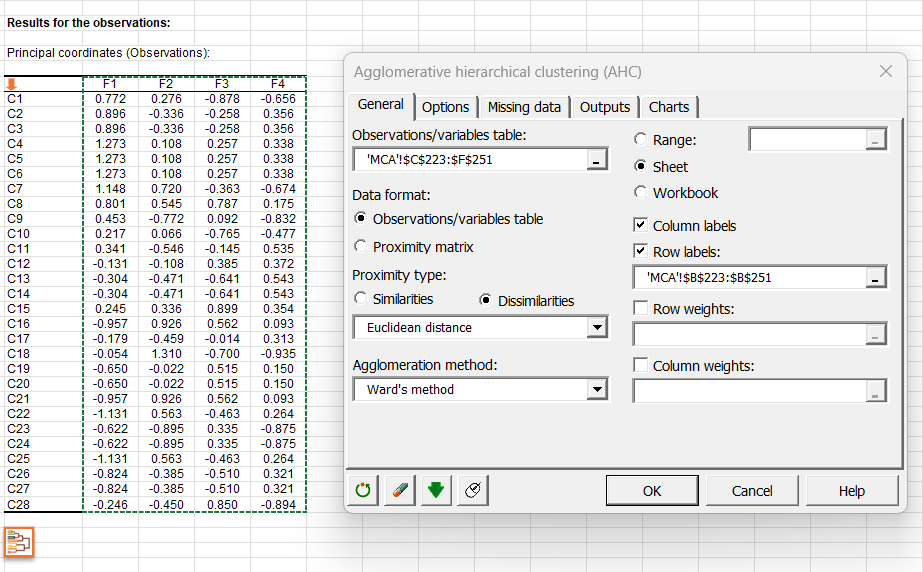
Sie können eine AHC starten, indem Sie auf die Schaltfläche unter der Tabelle der Hauptkoordinaten klicken. Ein orangefarbener Pfeil ermöglicht es Ihnen, direkt ans Ende der Tabelle zu gelangen, wenn diese viele Variablen enthält.
Durch Klicken auf diese Schaltfläche wird das Dialogfeld für die AHC automatisch konfiguriert, und Sie müssen nur noch auf die Schaltfläche OK klicken, um die Analyse zu starten.
Klicken Sie hier , um zu sehen, wie man die Ergebnisse der AHC-Analyse interpretiert.
Sehen Sie sich unser Video zur MCA-Analyse an
Das folgende Video zeigt Ihnen, wie Sie dieses Tutorial durchführen.

War dieser Artikel nützlich?
- Ja
- Nein