Faktoren-Analyse gemischter Daten (PCAmix) in Excel
Dieses Tutorial hilft Ihnen beim Einrichten und Interpretieren einer Faktoren-Analyse gemischter Daten in Excel mithilfe der XLSTAT-Software.
Datensatz zum Durchführen einer Faktoren-Analyse gemischter Daten (PCAmix)
Dieser Datensatz ist ein Teildatensatz, der vom Centre de recherche INRA d'Angers, Frankreich, gesammelt wurden. Die Experten baten die Versuchsteilnehmer, 21 Weine nach unterschiedlichen sensorischen Deskriptoren zu bewerten (14 quantitative Variablen). Außerdem haben wir zwei qualitative Variablen über den Weinursprung und über die Beschaffenheit des Bodens, auf dem die Rebe wächst.
Was ist die PCAmix-Methode?
Verwenden Sie die Faktoren-Analyse gemischter Daten (PCAmix), um eine Datentabelle zu analysieren, in der die Beobachtungen sowohl durch quantitative als auch qualitative Variablen beschrieben werden. Diese Methode wird verwendet um:
- Untersuchen und visualisieren Sie Zusammenhänge zwischen Variablen.
- Erhalten Sie nicht korrelierte Faktoren, die Linearkombinationen der Ausgangsvariablen sind.
- Visualisieren Sie Beobachtungen in einem 2- oder 3-dimensionalen Raum.
Die faktorielle Analyse gemischter Daten ist eine von Hill und Smith (1972) entwickelte Methode. Es wurden nur wenige Varianten dieser Methode entwickelt (Escofier 1979, Pagès 2004). Die in Xlstat verwendete Methode heißt PCAmix und wurde von Chavent et al (2014) entwickelt. Diese Methode kann als eine Mischung aus zwei bekannten Methoden der Faktoranalyse betrachtet werden: der Hauptkomponentenanalyse (PCA), mit der eine Tabelle mit Beobachtungen / quantitativen Variablen untersucht werden kann, und mit der MCA-Analyse (Mehrfach-Korrespondenzanalyse) , mit der Beobachtungen / qualitative Variablen untersucht werden können Tabelle.
Die PCAmix-Methode kann als eine Mischung dieser beiden Methoden angesehen werden. Sie ermöglicht die Analyse einer Tabelle, in der n Beobachtungen sowohl durch quantitative als auch durch qualitative Variablen beschrieben werden. Wie andere multivariate Verfahren zielt die PCAmix-Methode darauf ab, die Datendimensionalität zu reduzieren und sowohl die Nähe zwischen Variablen als auch die Nähe zwischen den Beobachtungen zu identifizieren.
Durchführen einer Mehrfach-Korrespondenzanalyse mit XLSTAT
Wählen Sie nach dem Öffnen von XLSTAT den Menüpunkt XLSTAT / Analysieren von Daten / PCAmix aus (siehe unten).
Wenn Sie auf die Schaltfläche geklickt haben, wird das Dialogfeld PCAmix angezeigt.
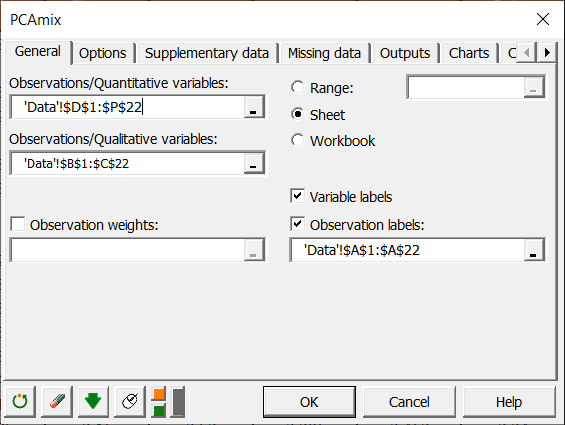
Wählen Sie im Feld Beobachtungen / quantitative Variablen die Spalten D-P und im Feld Beobachtungen / qualitative Variablen die Spalten B-C aus. Die Option Variablenbeschriftungen bleibt aktiviert, da die erste Zeile der Tabelle den Namen der Variablen enthält. Wählen Sie dann die Spalte A im Feld Beobachtungsbezeichnungen aus.
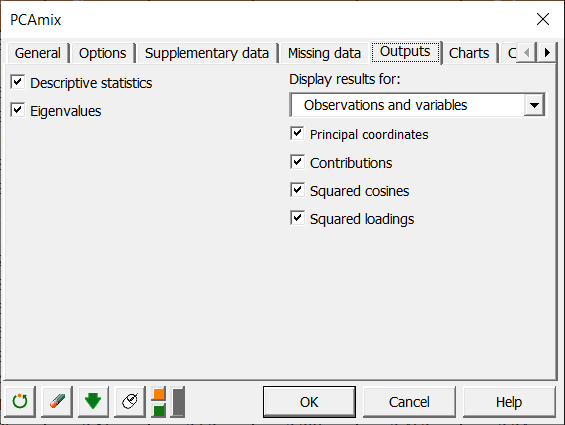 Wir wählen alle verfügbaren Ergebnisse für Variablen und Beobachtungen aus.
Wir wählen alle verfügbaren Ergebnisse für Variablen und Beobachtungen aus.
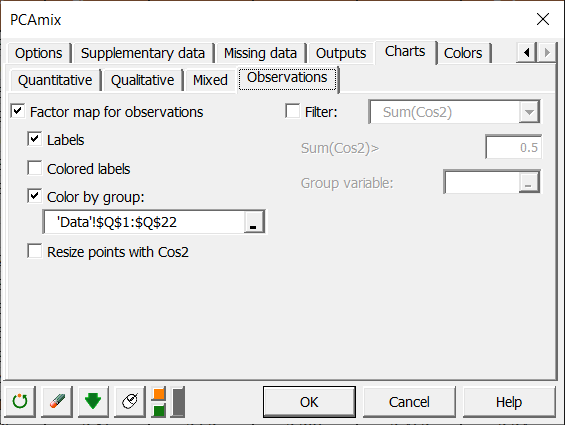 Hier wählen wir Beobachtungen anhand einer Gruppenvariablen aus. Diese qualitative Variable ist eine Umcodierung der quantitativen Variablen „Globale Qualität“. Die Einfärbung erlaubt es uns, Gruppen von Beobachtungen zu unterscheiden. Alle anderen Optionen bleiben auf den Standardeinstellungen.
Hier wählen wir Beobachtungen anhand einer Gruppenvariablen aus. Diese qualitative Variable ist eine Umcodierung der quantitativen Variablen „Globale Qualität“. Die Einfärbung erlaubt es uns, Gruppen von Beobachtungen zu unterscheiden. Alle anderen Optionen bleiben auf den Standardeinstellungen.
Diese letzte Registerkarte wird verwendet, um Farben für die Anzeige der Ergebnisse auszuwählen.
Interpretation der PCAmix-Ergebnissen
XLSTAT zeigt zuerst die deskriptiven Statistiken der ausgewählten Variablen an.
Die folgende Tabelle zeigt die Nicht-Null-Eigenwerte und die entsprechenden Beiträge in%.

Dann werden die Koordinaten der quantitativen Variablen und die Kategorien der qualitativen Variablen auf den faktoriellen Achsen angezeigt. Es werden Cosinus-Quadrate, Beiträge und quadratische Ladungen angezeigt. Für Beobachtungen werden dann dieselben Ergebnisse angezeigt. Bevor Sie die Nähe zwischen zwei Variablen und / oder Beobachtungen interpretieren, sollten Sie überprüfen, ob ihr Beitrag oder ihr Kosinusquadrat auf den betrachteten Achsen hoch ist.
Die folgenden Diagramme sind sehr nützlich, um Beziehungen zwischen Variablen, Beobachtungen und faktoriellen Achsen zu interpretieren:
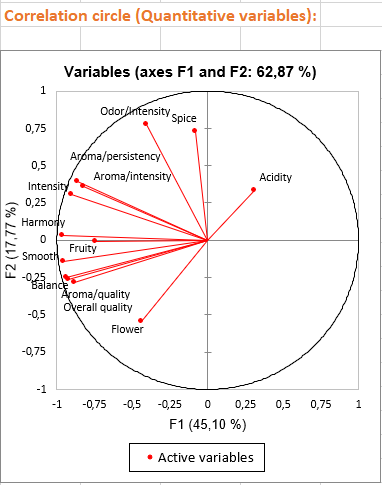
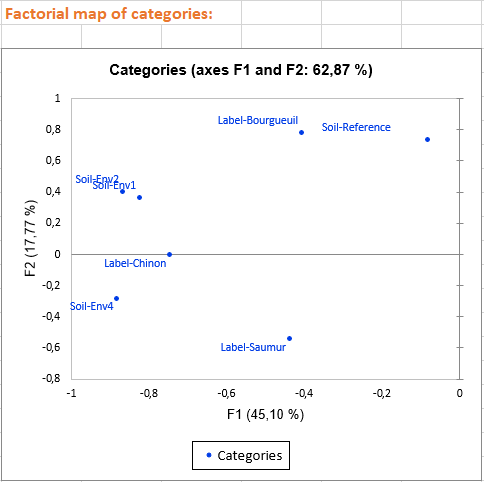
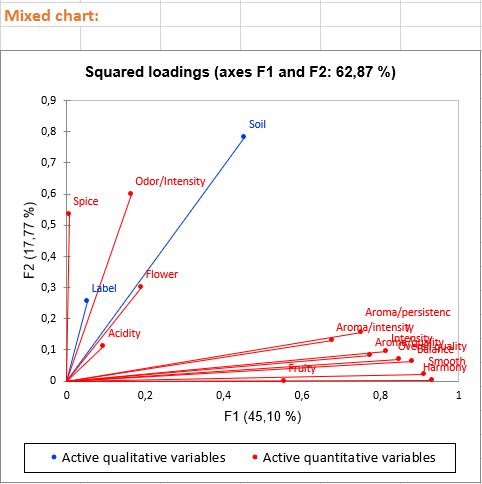
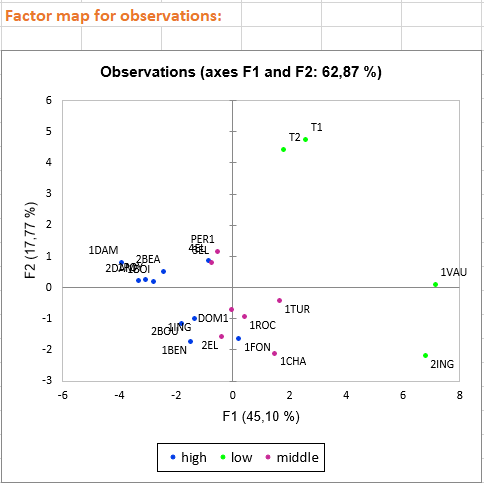
Bei den drei ersten Diagrammen handelt es sich um Variablen und deren Verknüpfungen mit faktoriellen Achsen. Diese Diagramme ermöglichen es uns, faktorielle Achsen zu interpretieren:
- Achse 1 ist stark negativ mit den folgenden Variablen korreliert: Frucht, Blume, Aroma / Intensität, Aroma / Ausdauer, Aroma / Qualität, Balance, Glatt, Intensität, Harmonie, Gesamtqualität. Dies bedeutet, dass Weine mit negativen Werten auf der ersten Achse Weine, einen hohen Werten für diese Variablen sind.
- Achse 2 ist positiv mit den Variablen Geruchintensität und Gewürz korreliert und korreliert negativ mit der Variablen Floral. Dies bedeutet, dass ein Wein mit einem hohen Wert auf Achse 2 ein Wein ist, der eine wichtige Note bezüglich Geruchsintensität und Würzigkeit, aber einen niedrigen Wert für Floral hat. Es wird auch bemerkt, dass die qualitative Variable Sol hoch auf die Achse 2 lädt, zum Beispiel sind Weine von der Sorte Sol-Env4, Weine mit hohen Werten auf der Achse 2.
Mit der Achseninterpretation und des faktoriellen Diagramms der Beobachtungen können wir eine Vorstellung von den Weinmerkmalen erhalten, indem wir ihre Positionen in der Grafik betrachten. Durch die Einfärbung des Weins gemäß seiner globalen Qualität, die als qualitative Variable neu codiert wurde, können die drei Gruppen unterschieden werden. Wir sehen, dass die besten Weine (in Blau) Weine mit negativen Werten auf der ersten Achse und niedrigen Werten auf der zweiten Achse sind. Mittlere Weine stehen hauptsächlich im Zentrum des Diagramms, und weniger geschätzte Weine (in Grün) sind Weine mit hohen Werten auf der Sekundärachse. Dies bedeutet, dass sie würzig sind und wahrscheinlich eine Boden der Art Env4 aufweisen.
War dieser Artikel nützlich?
- Ja
- Nein