Árbol de clasificación: tutorial en Excel
Este tutorial le mostrará cómo crear e interpretar un árbol de clasificación CHAID en Excel con el software XLSTAT.
Datos para crear un árbol de clasificación CHAID
Los datos provienen de [Fisher M. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7, 179 -188] y corresponden a 150 flores Iris, definidas por cuatro variables (longitud del sépalo, anchura del sépalo, longitud del pétalo, anchura del pétalo) y sus especies. Tres especies diferentes se han incluido en este estudio: Setosa, Versicolor y Virginica.



Iris Setosa, Versicolor y Virginica.
Objetivo de este árbol de clasificación CHAID
Our goal is to test if the four descriptive variables allow to efficiently predict to which species a flower corresponds, and in this case, to identify rules that would help classifying the flowers on the basis of the four variables.
Nuestro objetivo es poner a prueba si las cuatro variables descriptivas permiten predecir de manera eficiente a qué especie pertenece una flor y, en este caso, identificar las reglas que ayudarían a la clasificación de las flores sobre la base de las cuatro variables.
Nota: el mismo caso se trata en el tutorial sobre análisis discriminante.
Configuración del cuadro de diálogo para generar un árbol de clasificación CHAID
Tras abrir XLSTAT, elija el comando XLSTAT / Aprendizaje Automático / Árboles de clasificación y regresión, o bien haga clic en el botón correspondiente de la barra de herramientas Aprendizaje automático (véase siguiente captura de pantalla).
Una vez haya hecho clic en el botón, aparece el cuadro de diálogo. La variable dependiente cualitativa corresponde aquí a la variable “Especies”.
Las Variables explicativas cuantitativas son las cuatro variables descriptivas.
Elegimos utilizar el algoritmo CHAID y fijamos la profundidad máxima del árbol a 3 para evitar la obtención de un árbol demasiado complejo.

En la pestaña Opciones, varias opciones técnicas permiten controlar mejor la forma en que se construye el árbol.

En pestaña Gráficos en primer lugar seleccionamos la opción Gráficos de barras para mostrar la distribución de las especies en cada nodo.
Como veremos más adelante, la opción Gráficos circulares también se está utilizando en este tutorial.
Los cálculos empiezan una vez haya hecho clic en OK. A continuación, se muestran los resultados.
Interpretación de los resultados de un árbol de clasificación CHAID
Después de los estadísticos simples de todas las variables seleccionadas, XLSTAT muestra información sobre la estructura del árbol. Esto incluye para cada nodo, el valor de p para la segmentación (splitting), el número de objetos en cada nodo, el % que corresponde a los nodos padre e hijo, la variable de segmentación, el valor(es) o intervalos de esta última, y la pureza (purity) que indica cuál es el % de objetos que pertenecen a la categoría dominante de la variable dependiente en ese nodo.

El siguiente resultado es el árbol de clasificación.
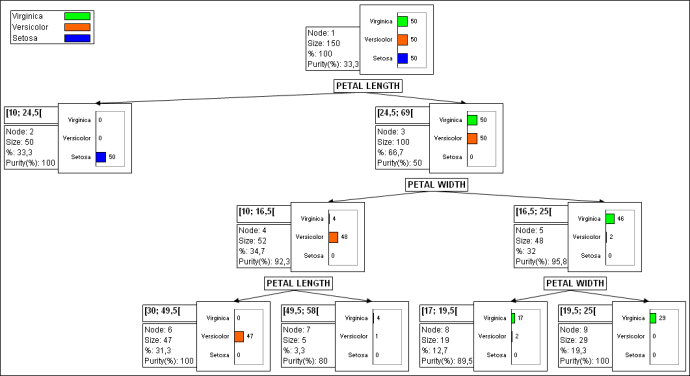
Este diagrama permite visualizar los pasos sucesivos durante los cuales el algoritmo CHAID identifica las variables que permiten dividir o segmentar mejor las categorías de la variable dependiente. Por lo tanto, vemos que usando únicamente la longitud del pétalo, el algoritmo ha encontrado una regla que permite separar perfectamente las flores del iris de la especie Setosa. Si la longitud del pétalo es de entre 10 y 24.5, entonces la especie es Setosa.
La información disponible en cada nodo se explica a continuación.

El algoritmo se detiene cuando no se puede encontrar ninguna regla adicional, o cuando se alcanza uno de los límites establecidos por el usuario (número de objetos en un nodo padre o hijo, profundidad máxima del árbol, valor p del umbral para la segmentación).
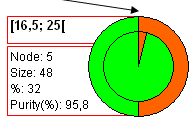
XLSTAT ofrece una segunda posibilidad de visualizar los árboles de clasificación. En lugar de utilizar gráficos de barras, utiliza gráficos circulares o sectoriales. Estos últimos son más fáciles de leer cuando hay muchos nodos y muchas categorías en la variable dependiente. El círculo interior del ciclograma corresponde a las frecuencias relativas de las categorías a las que corresponden los objetos contenidos en el nodo. El anillo exterior muestra la distribución de las categorías en el nodo padre.

La siguiente tabla contiene las reglas construidas por el algoritmo de una manera menos visual, pero más legible: las reglas están escritas en lenguaje natural. La pureza (purity) proporciona el % que corresponde a la categoría mayoritaria a nivel de nodo. También se muestra el número de objetos que corresponden a la categoría.

De esta manera, vemos que “Si PETAL LENGHT está en el intervalo [30; 49.5 [ y PETAL WIDTH está en el intervalo [10; 16,5 [ entonces SPECIES es Versicolor en el 100% de los casos”; esta regla es verificada por 47 flores.
Las reglas que corresponden a las hojas del árbol (i.e., los nodos terminales) permiten calcular predicciones para cada observación, con una probabilidad que depende de la distribución de las categorías en el nivel de hoja. Estos resultados se muestran en la tabla “Resultados por objeto”.

Vemos que 3 observaciones han sido clasificadas erróneamente por el algoritmo. Este resultado es casi idéntico al que se obtiene con un análisis discriminante, donde las observaciones clasificadas erróneamente son las número 5, 9 y 12.
La matriz de confusión resume la reclasificación de las observaciones, y permite ver rápidamente el % de las observaciones bien clasificadas, esto es, la ratio entre el número de observaciones que han sido bien clasificadas y el número total de observaciones. En este caso equivale al 98%.

Los árboles creados por XLSTAT son parcialmente dinámicos. Se puede podar el árbol en un nivel determinado en todas las ramas, o podemos podar sólo una rama determinada. Para podar el árbol primero tiene que hacer clic en un nodo. Cuando aparecen los seis puntos grises alrededor del nodo, haga clic con el botón derecho del ratón para mostrar el menú contextual:

Si decidimos ocultar un sub-árbol, el árbol se vuelve a crear sin las ramas a partir del nodo seleccionado. Los contornos del nodo se muestran en color rojo.
Por supuesto, es posible después mostrar de nuevo el sub-árbol oculto utilizando el mismo menú contextual.
¿Ha sido útil este artículo?
- Sí
- No