Tutorium zum Durchführen von Penalty-Analysen in Excel
Dieses Tutorium wird Ihnen helfen, eine Penalty-Analyse in Excel mithilfe der Software XLSTAT einzurichten und zu interpretieren.
Datensatz für die Durchführung einer Penalty-Analyse
In diesem Beispiel werden zwei Arten von Daten verwendet:
-
Präferenzdaten (oder Beliebtheitsbewertungen), die einer Umfrage entsprechen, bei der eine bestimmte Marke/Sorte von Kartoffelchips von 150 Verbrauchern bewertet wurde. Jeder Verbraucher gab eine Bewertung auf einer Skala von 1 bis 5 für vier Attribute (Salzigkeit, Süße, Säure, Knusprigkeit) ab - 1 bedeutet "wenig", und 5 "viel" -, und dann gab er eine Gesamtbewertung auf einer Likert-Skala von 1 bis 10 ab.
-
Die Daten wurden auf einer JAR (Just About Right) 5-Punkte-Skala gesammelt. Diese entsprechen Bewertungen, die von 1 bis 5 für vier Attribute (Salzigkeit, Süße, Säure, Knusprigkeit) reichen. 1 entspricht "Überhaupt nicht genug", 2 "Nicht genug", 3 "JAR" (Genau richtig), ein Ideal für den Verbraucher, 4 "Zu viel" und 5 "Viel zu viel".
Ziel dieses Tutorials
Unser Ziel ist es, einige mögliche Richtungen für die Entwicklung eines neuen Produkts zu identifizieren.
Einrichten einer Penalty-Analyse
-
Sobald XLSTAT geöffnet ist, klicken Sie auf Sensorik / Schnellaufgaben / Penalty-Analyse.
-
Das Dialogfeld Penalty-Analyse erscheint.
-
Wir wählen die Beliebtheitsbewertungen aus und dann die JAR-Daten. Die JAR-Etiketten mit 3 Stufen werden ebenfalls ausgewählt, da sie die Interpretation der Ergebnisse erleichtern.
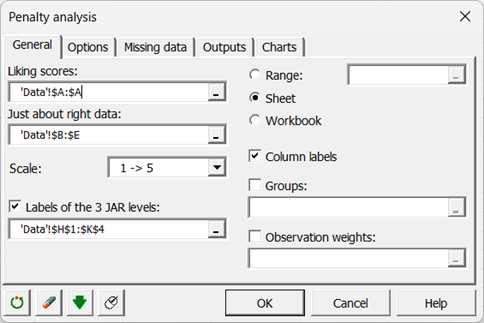
-
Im Reiter Optionen definieren wir die Schwelle für die Stichprobengröße, unterhalb derer die Vergleichstests nicht durchgeführt werden, da sie möglicherweise nicht zuverlässig genug sind.
-
Bei den Ausgaben wurde die Spearman-Korrelation gewählt, da die Daten ordinal sind.
-
Die Berechnungen beginnen, sobald Sie auf OK geklickt haben. Die Ergebnisse werden dann angezeigt.
Interpretieren der Ergebnisse einer Penalty-Analyse
Die Ergebnisse werden anschließend angezeigt. Das erste Ergebnis sind die deskriptiven Statistiken für die Ratingdaten und die vielen JAR Variablen. Die Korrelationsmatrix wird dann angezeigt.
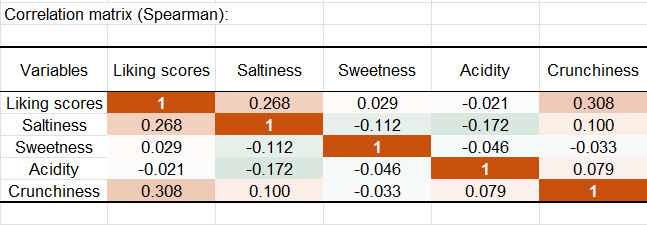
Die Korrelationen zwischen den Ratings und den JAR Variablen sollten nicht interpretiert werden, da die Rakings der JAR Daten nicht wirklich ordinaler Natur sind (5 is weniger als 3 der JAR Skala, während 5 mehr als 3 der Ratingskala darstellt). Ist jedoch eine Korrelation zwischen einer JAR Variable und einer Rating-Variable signifikant von 0 verschieden, so kann dies bedeuten, dass die JAR Variable einen geringen Einfluß auf die Ratings hat: Wenn ein starker Einfluß bestünde, so wäre die Korrelation idealerweise 0. Falls die "zu viel" Fälle einen geringeren Einfluß haben als die "zu wenig", so sollte die Korrelation positiv sein, und negativ im umgekehrten Fall.
Die nächsten Tabellen sind eine Zusammenfassung der JAR Daten. Das folgende Diagramm basiert auf der Tabelle und erlaubt es, rasch darzustellen, wie die JAR Ladungen für jede Dimension verteilt sind.
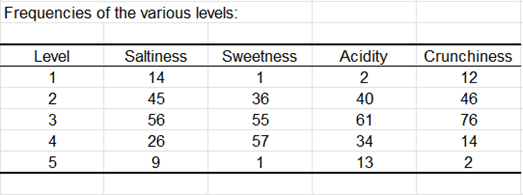
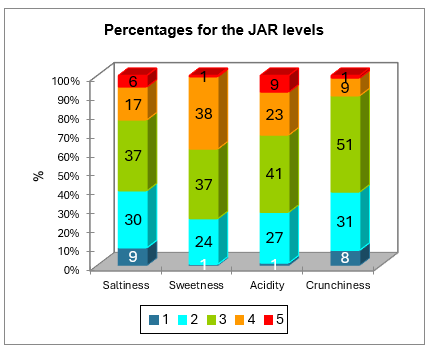
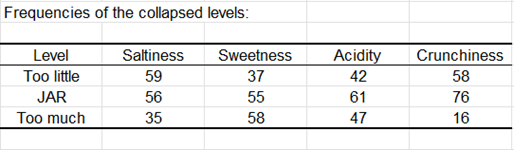
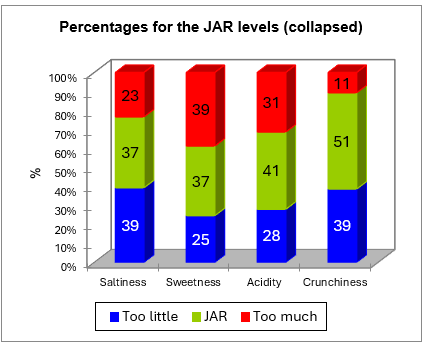
Dann werden die Daten aggregiert zu 3 Skalenniveaus. Die entsprechenden Häufigkeiten werden in Form einer Tabelle und eines Diagramms unten angezeigt.
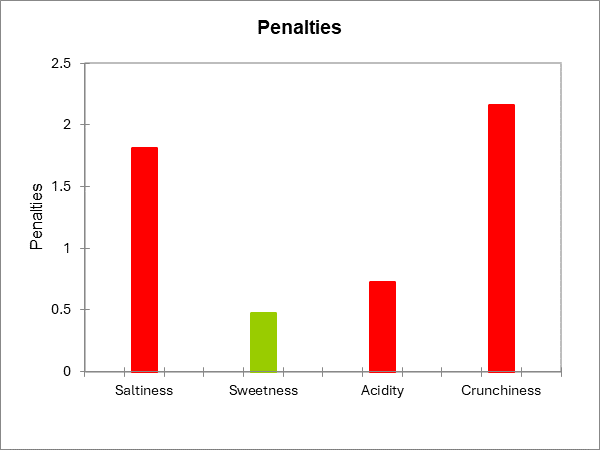
Die nächste Tabelle entspricht der Penalitätenanalyse.
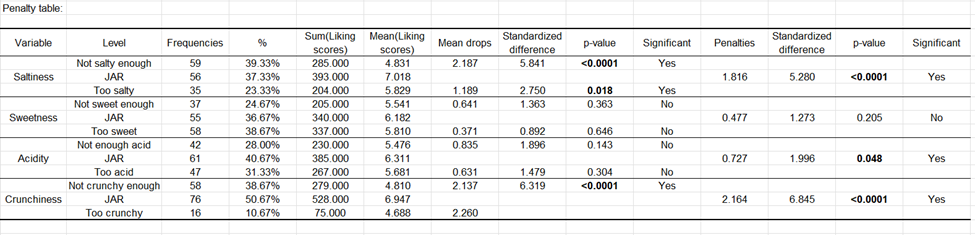
Die folgenden Informationen werden für jede JAR Dimension angezeigt: - Der Name der JAR Dimension. - Die 3 kollabierten Niveaus der JAR Daten. - Die Häufigkeiten, die jedem Niveau entsprechen. - Der zugehörige % für jeden Niveau. - Die Summe der Rating Ladungen für jedes Niveau. - Das durchschnittliche Rating für jedes Niveau. - Die Mittelwertabfälle für die Niveaus "zu viel" und "zu wenig" (Dies ist die Differenz zwischen den Rating Mittelwerten für die JAR Niveaus minus den Niveaus "zu viel" oder "zu wenig".) Diese Information ist interessant, da sie zeigt wie viele Punkte im Rating Sie verlieren, wenn Sie ein Produkt mit der Bewertung "zu viel" oder "zu wenig" für einen Konsumenten. - Die standardisierte Differenz ist ein statistisches Zwischenergebnis, das später für die Vergleichstests benutzt wird. - Die p-values entsprechen den Vergleichstests der Mittelwerte der JAR Niveaus und den Mittelwerten der beiden unteren Niveaus (Dies ist ein multipler Vergleich zwischen 3 Gruppen.). - Eine Interpretation wird automatisch erzeugt und hängt von dem gewählten Signifikanzniveau ab (hier 5%). - Anschließend wird die Penalität errechnet. Dies ist eine gewichtete Differenz zwischen den Mittelwerten (Mittelwert der Ratings für JAR - Mittelwert der Ratings für die beiden übrigen Niveaus zusammengenommen.). Diese Statistik gab dieser Methode ihren Namen. Dies zeigt, wie viele Rating-Punkte Sie verlieren, wenn Sie nicht den Erwartungen des Konsumenten entsprechen. - Die standardisierte Differenz ist ein statistisches Zwischenergebnis, das für die Vergleichstest benötigt wird. - Die p-value entsprechen den Vergleichstests der Mittelwerte der JAR Niveaus mit den Mittelwerten der anderen Niveaus. Die ist äquivalent mit dem Test, ob die Penalitäten signifikant von 0 verschieden sind oder nicht. - Eine Interpretation wird automatisch erzeugt und hängt von dem gewählten Signifikanzniveau ab (hier 5%).
Für die Dimension der Salzigkeit, sieht man, dass die Konsumenten ein Produkt stark penalisieren, wenn es als nicht salzig genug angesehen wird. Beide Mittelwertabfälle sind signifikant von 0 verschieden und ebenfalls die Gesamtpenalität.
Für die Dimensionen Süße und Säuregehalt ist keiner der Tests signifikant. Die umso zutreffender für die Süße.
Für die Dimension der Knackigkeit können der Mittelwertabfall für das Niveau "zu viel" nicht berechnet werden, da der %-Satz der Fälle in diesem Niveau kleiner als der gewählte Schwellwert von 20% ist. Wenn ein Produkt nicht knusprig genug ist, so wird das Produkt stark penalisiert.
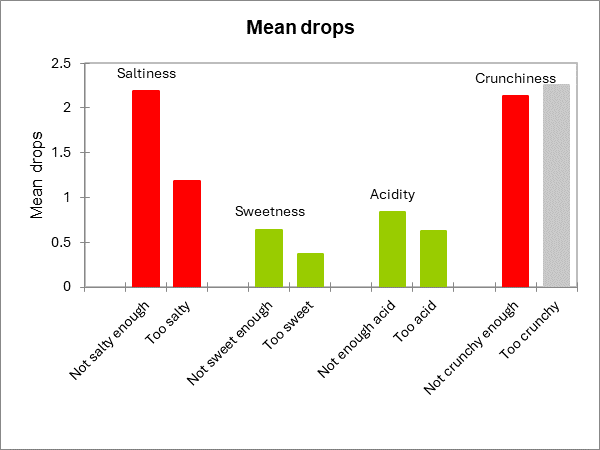
Die nächsten beiden Diagramme fassen die beschriebenen Ergebnisse zusammen. Falls die Säule rot ist, so ist die Differenz signifikant, ist sie dagegen grün, so ist die Differenz nicht signifikant. und falls sie grau eingefärbt ist, so wurde der Test nicht berechnet, da nicht genügend Fälle vorliegen.
War dieser Artikel nützlich?
- Ja
- Nein