Análisis Penalty: tutorial en Excel
Este tutorial le ayudará a configurar e interpretar un análisis penalty en Excel usando el software estadístico XLSTAT.
Datos para ejecutar un análisis penalty
Se utilizan dos tipos de datos en este ejemplo:
Datos de preferencia (o puntuaciones de agrado) que corresponden a una encuesta en la que una marca/tipo de papas fritas fue evaluada por 150 consumidores. Cada consumidor dio una calificación en una escala de 1 a 5 para cuatro atributos (Salinidad, Dulzura, Acidez, Crujencia) - 1 significa "poco", y 5 "mucho" -, y luego dio una puntuación general de agrado en una escala Likert de 1 a 10.
Los datos se recopilaron en una escala JAR (Justo lo Adecuado) de 5 puntos. Estas corresponden a calificaciones que van de 1 a 5 para cuatro atributos (Salinidad, Dulzura, Acidez, Crujencia). 1 corresponde a «No es suficiente en absoluto», 2 a «No es suficiente», 3 a «JAR» (Justo lo Adecuado), un ideal para el consumidor, 4 a «Demasiado» y 5 a «Demasiado en exceso».
Objetivo de este tutorial
Nuestro objetivo es identificar algunas posibles direcciones para el desarrollo de un nuevo producto.
Configuración de un análisis penalty
-
Una vez que XLSTAT esté abierto, haga clic en Sensorial / Tareas rápidas / Análisis de penalización.
-
Aparece el cuadro de diálogo de Análisis de penalización.
-
Seleccionamos las puntuaciones de agrado y luego los datos JAR. También se seleccionan las etiquetas JAR de 3 niveles, lo que facilita la interpretación de los resultados.
-
En la pestaña Opciones, definimos el umbral del tamaño de la muestra por debajo del cual no se realizarán las pruebas de comparación, ya que podrían no ser lo suficientemente fiables.
-
En las Salidas, se eligió la correlación de Spearman porque los datos son ordinales.
-
Los cálculos comienzan una vez que usted ha hecho clic en OK. Luego, se mostrarán los resultados.
Interpretación de los resultados de un análisis penalty
Los primeros resultados son los estadísticos descriptivos de los datos de gusto y las diferentes variables JAR. Se muestra seguidamente la matriz de correlaciones.
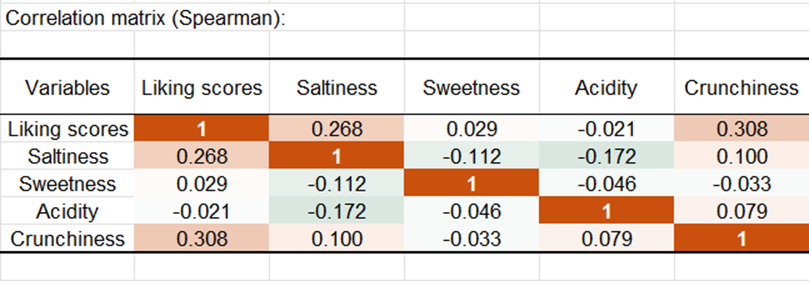
Las correlaciones entre las variables gusto y JAR no deben ser interpretadas, toda vez que los rangos de los datos JAR no son verdaderos datos ordinales (5 es inferior a 3 en la escala JAR, mientras que 5 es más de 3 en la escala gusto).
Sin embargo, si una correlación entre una variable JAR y una variable de gusto es significativamente diferente de 0, ello podría significar que la variable JAR tiene un bajo impacto en el gusto: si tuviera un impacto fuerte, la correlación debería ser idealmente 0. Si los casos “excesivo” tienen un impacto menor que los casos “demasiado poco”, la correlación puede ser positiva, y viceversa para las correlaciones negativas.
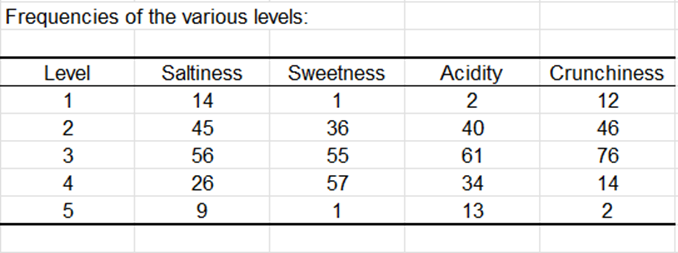
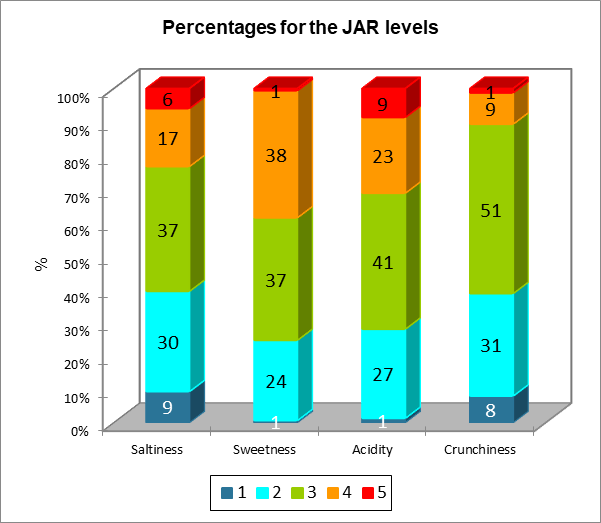
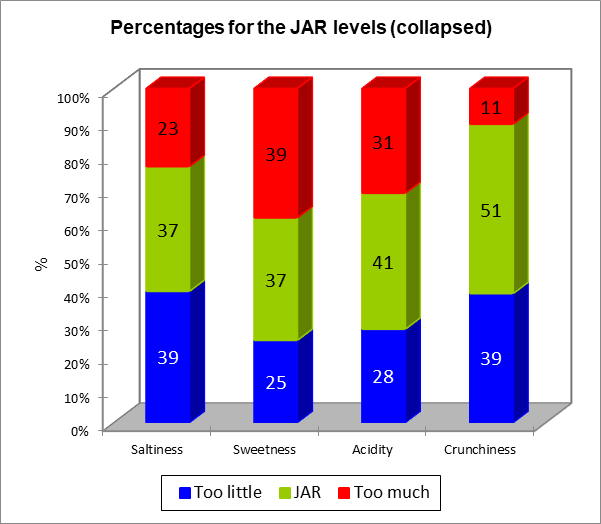
La siguiente tabla es un resumen de los datos JAR. El gráfico que sigue se basa en esa tabla, y permite visualizar rápidamente cómo se distribuyen las puntuaciones JAR para cada dimensión.
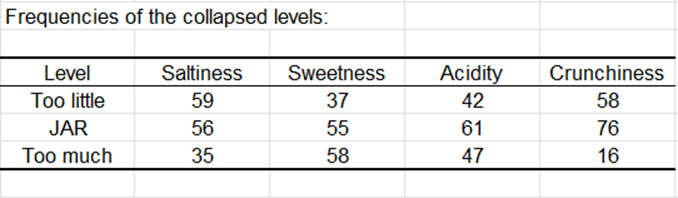
Los datos se agregan a continuación en una escala a 3 niveles. La tabla de frecuencias y el gráfico correspondientes se muestran más abajo.
La tabla siguiente corresponde al análisis penalty.
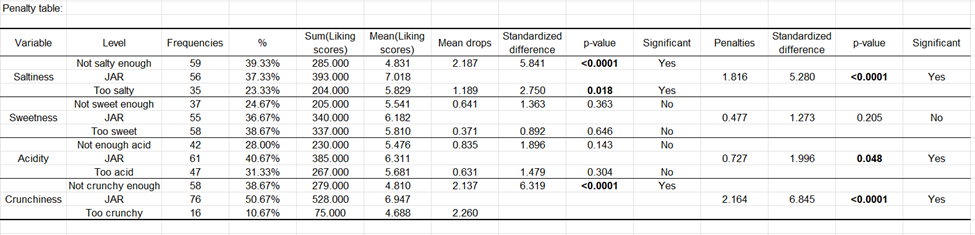
Se muestra la siguiente información para cada dimensión JAR:
-
El nombre de la dimensión JAR.
-
Los 3 niveles colapsados de los datos JAR.
-
Las frecuencias correspondientes a cada nivel.
-
El % correspondiente a cada nivel.
-
La suma de las puntuaciones de gusto correspondientes a cada nivel.
-
El promedio de gusto para cada nivel.
-
Las caídas medias para los niveles “demasiado” y “demasiado poco” (esta es la diferencia entre la media de gusto de los niveles JAR menos los niveles “demasiado” o “demasiado poco”. Esta información resulta de interés en la medida en que muestra cuántos puntos de gusto perdemos por tener un producto “demasiado” o “demasiado poco” para un consumidor.
-
Las diferencias estandarizadas son estadístico intermedio que es luego usado para las pruebas de comparación.
-
Los valores p corresponden a la prueba de comparación de la media para el nivel JAR y las medias para los dos niveles restantes (se trata de una comparación múltiple de 3 grupos).
-
Seguidamente se proporciona automáticamente una interpretación, y depende del nivel de significación seleccionado (aquí, el 5%).
-
A continuación se calcula el penalty. Es una diferencia ponderada entre las medias (Media de Gusto para JAR – Media de Gusto para los otros dos niveles tomados juntos). Este estadístico ha dado su nombre al método. Muestra cuántos puntos de gusto se pierden por no ser lo esperado por el consumidor.
-
La diferencia estandarizada es un estadístico intermedio que se usa luego para la prueba de comparación.
-
El valor p corresponde a la prueba de comparación de la media para el nivel JAR con la media de los demás niveles. Equivale a probar si el penalty es significativamente diferente de 0 o no.
-
Se proporciona seguidamente una interpretación automática que depende del nivel de significación seleccionado (aquí el 5%).
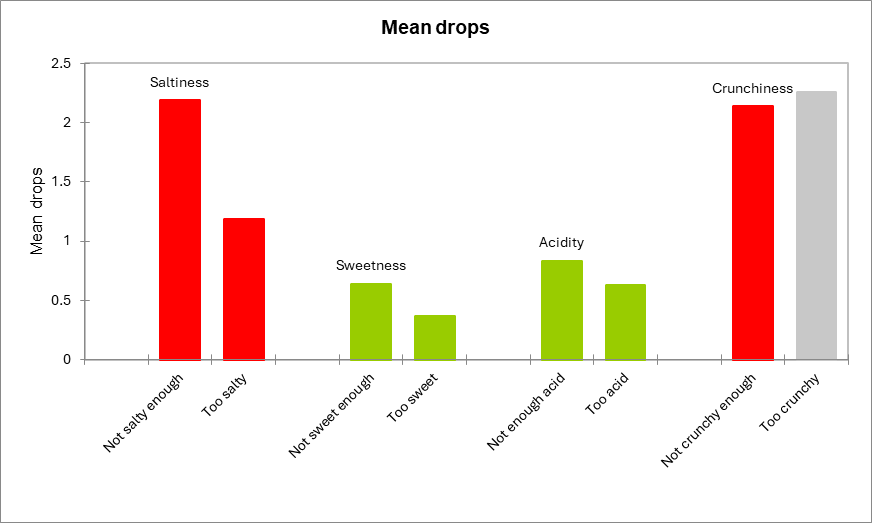
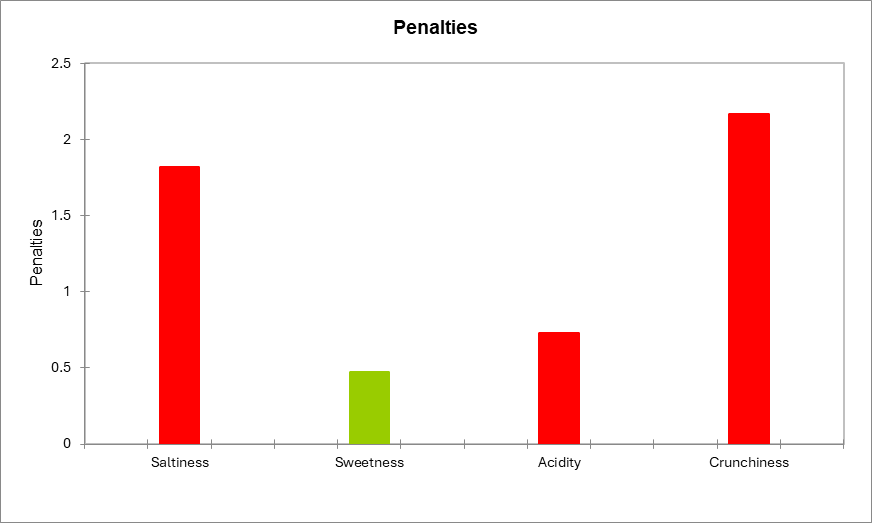
Para la dimensión sabor salado, vemos que los clientes penalizan fuertemente el producto cuando lo consideren no lo suficiente como salada. Ambas caídas medias son significativamente diferentes de 0, y también lo es la pena en general.
Para la dimensión dulzor, ninguna de las pruebas es significativa.
Para la dimensión de acidez, el penalty general es ligeramente significativo, aunque los dos descensos medios no lo son. Esto significa que la acidez sí es importante para los clientes, pero esta encuesta puede no haber sido lo suficientemente potente como para detectar el descenso medio específico (no suficiente ácido y / o demasiado ácido) está implicado.
Para el carácter crujiente, la prueba de descenso medio no se pudo calcular para el nivel “demasiado”, debido a que el % de los casos en este nivel es inferior al umbral de 20% establecido anteriormente. Cuando el producto no es lo suficientemente crujiente, el producto es muy penalizado.
Los dos gráficos siguientes resumen los resultados descritos anteriormente. Cuando una barra es de color rojo significa la diferencia es significativa; cuando es verde, la diferencia no es significativa; y cuando es gris, la prueba no se calculó porque no había suficientes casos.
¿Ha sido útil este artículo?
- Sí
- No