Tutorial de análisis CATA Check-All-That-Apply en Excel
Este tutorial le ayudará a configurar e interpretar un análisis CATA en Excel utilizando el software estadístico XLSTAT.
Conjunto de datos para ejecutar un análisis CATA en XLSTAT
Para este tutorial, utilizamos datos proporcionados por Ares et al. (2014). Corresponden a la evaluación de 6 productos (5 regulares y 1 ideal) por 119 consumidores sobre 15 atributos. Los datos se registran en un formato binario (0: atributo no marcado; 1: atributo marcado). Además, cada producto (excepto el ideal) es calificado en general (0-10) por cada consumidor.
Los datos están en formato vertical, lo que significa que tenemos una fila por cada combinación de consumidor y producto.
Objetivo de este tutorial
Este tutorial tiene como objetivo realizar un análisis CATA (Check-All-That-Apply) para caracterizar los productos probados por los consumidores.
Configuración de un análisis CATA en XLSTAT
-
Para realizar un análisis CATA, haga clic en Sensorial / Datos CATA / Análisis de datos CATA.
-
En la pestaña General, primero asegúrese de seleccionar el formato de datos Vertical.
-
En el campo Datos CATA, seleccione la tabla de atributos.
-
Luego, seleccione las columnas de Consumidor, Muestra y Preferencia en los campos Evaluadores, Productos y Datos de preferencia, respectivamente.
-
Capture el identificador del producto ideal en el campo Producto ideal.
Importante: El conjunto de datos debe estar equilibrado (un evaluador por cada producto).
En la pestaña Opciones(1), seleccione la distancia Chi-cuadrado para el Análisis de Correspondencias, validación de datos CATA y la Independencia de atributos.
-
Haga clic en el botón OK.
-
Aparece un cuadro de diálogo para seleccionar y validar los ejes a mostrar en la representación gráfica del análisis de correspondencias. Simplemente haga clic en el botón Listo.
Interpretación de los resultados de un análisis CATA en XLSTAT - Primera parte
Las dos primeras tablas y gráficos se refieren a la validación de los datos CATA. En primer lugar, se realiza una detección de los evaluadores que marcaron mucho más o menos que los demás. En nuestro caso, la mayoría de los jueces marcaron entre el 20 % y el 35 % del tiempo, pero algunos de ellos tienen un comportamiento particular. Por ejemplo, ¡el evaluador 27 solo marcó el 7 % del tiempo! A continuación, se realiza un análisis similar de los atributos para detectar atributos sobreutilizados o infrautilizados.
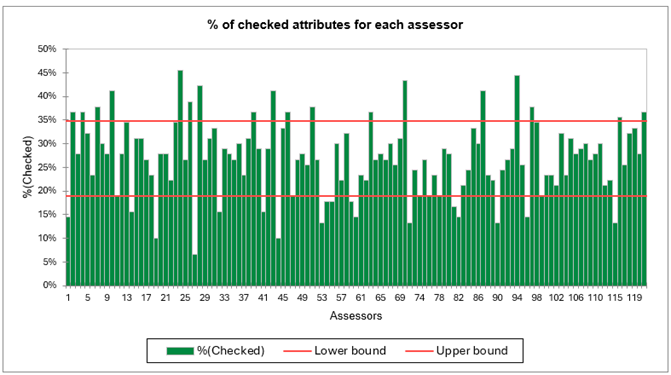
Luego, se realiza un análisis que combina los dos anteriores. Indica el porcentaje de verificaciones por evaluador y por atributo. Este análisis permite determinar si los atributos se verifican de manera consensuada o no. El atributo "Jugoso" presenta contrastes, con algunos evaluadores marcándolo más del 80 % del tiempo y otros marcándolo menos del 20 %.
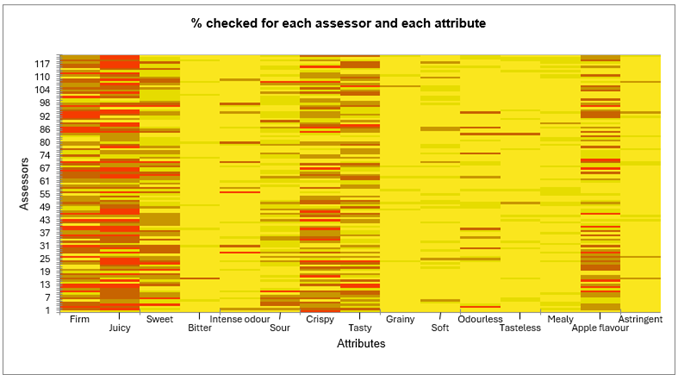
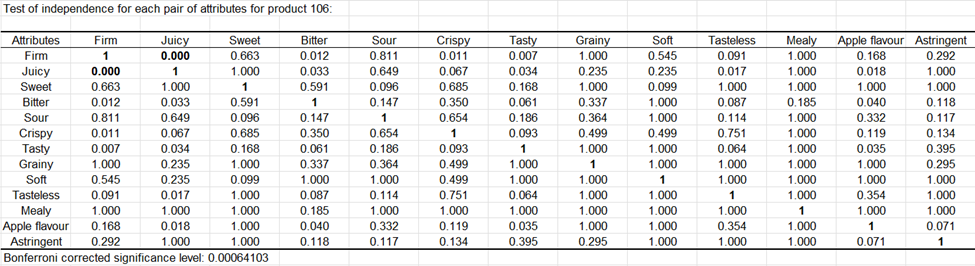
Para un atributo dado, la prueba Q de Cochran permite probar el efecto de una variable explicativa (Productos) sobre si los consumidores perciben el atributo o no. Un valor p bajo más allá de un umbral de significancia indica que los productos difieren significativamente entre sí. Si el valor p es significativo, el usuario puede estar interesado en examinar comparaciones múltiples por pares, representadas por letras minúsculas dentro de las celdas de la tabla:
-
dos productos que comparten la(s) misma(s) letra(s) no difieren significativamente.
-
dos productos que no tienen letras en común difieren significativamente.
Podemos ver que todos los atributos, excepto dos relacionados con el olor (inodoro y olor intenso), están asociados a valores p significativos a 0.05. Por ejemplo, si consideramos el atributo crujiente, el producto 257 es el más marcado. Sin embargo, no es significativamente más crujiente que el 548 (verifique las letras). Los productos 992 y 366 son los menos crujientes y no difieren significativamente entre sí.
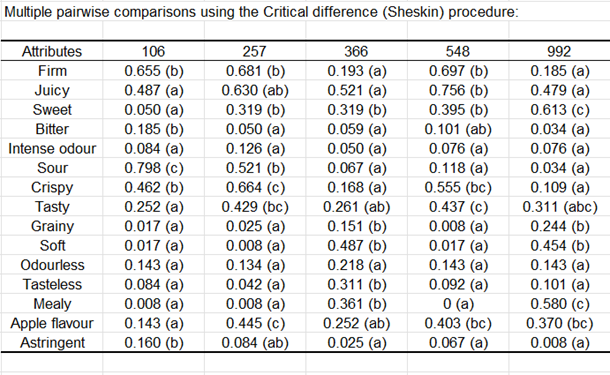
Para cada uno de los productos, se realiza una prueba de independencia de atributos para determinar si estos atributos no son redundantes. Así, podemos ver que para el producto 106, los atributos jugoso y firme son redundantes.
La siguiente tabla de contingencia es la suma de las tablas de atributos a través de los evaluadores. Se utiliza para realizar un análisis de correspondencias (AC).
Se prueba la independencia entre las filas y las columnas (este resultado está actualmente disponible solo para el AC clásico, utilizando la distancia Chi-cuadrado). Dado que el valor p es menor que el nivel de significancia (0,05), concluimos que es muy probable que existan diferencias reales entre los productos en términos de sus perfiles sensoriales.
La tabla de valores propios y el gráfico correspondiente permiten verificar la calidad del análisis. La calidad del análisis es buena (92,17 % de la inercia total explicada en las dos primeras dimensiones).
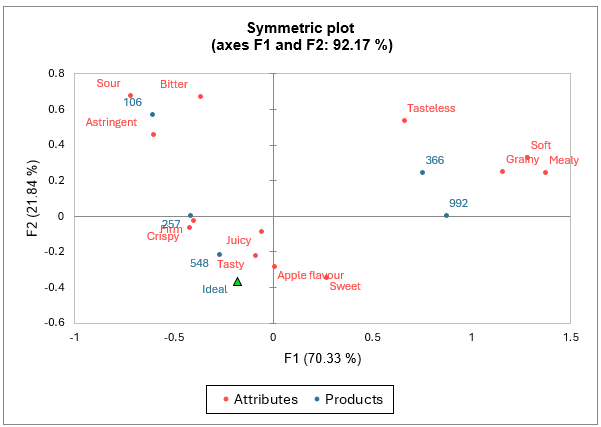
Según el mapa del análisis, un producto ideal debería ser relativamente sabroso, jugoso, crujiente, firme y dulce, y tener un sabor a manzana.
Por otro lado, no debería ser relativamente demasiado ácido, amargo, astringente, granuloso, blando, harinoso o insípido. El producto 548 parece ser el más cercano al producto ideal, mientras que el producto 106 está lejos debido a su relativa amargura, acidez y astringencia. Los productos 366 y 992 también están relativamente lejos del producto ideal.
Más información sobre el análisis de correspondencias está disponible aquí.
A continuación, se muestra una matriz de correlación que incluye atributos (correlación tetrachorica) y puntuaciones de agrado (correlación biserial, última fila). Observamos algunas correlaciones fuertes. La correlación negativa entre dulce y ácido indica que cuando las personas marcan ácido, no marcan dulce, y viceversa. Las puntuaciones de agrado parecen estar positivamente, aunque débilmente, correlacionadas con los atributos que estaban vinculados al producto ideal en el análisis de correspondencias (jugoso, sabroso, sabor a manzana).
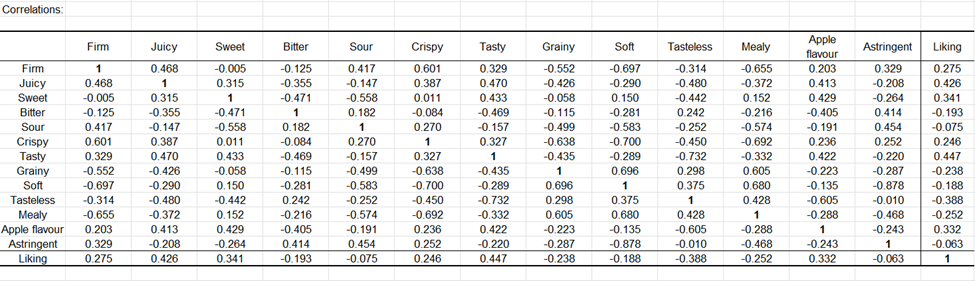
El Análisis de Coordenadas Principales (PCoA) se aplica a los coeficientes de correlación y los resultados se visualizan en un mapa bidimensional. El gráfico de sedimentación indica que las dos primeras dimensiones son suficientes para interpretar las relaciones entre los atributos. Aquí también vemos que el agrado está asociado con los atributos jugoso, sabroso y sabor a manzana.
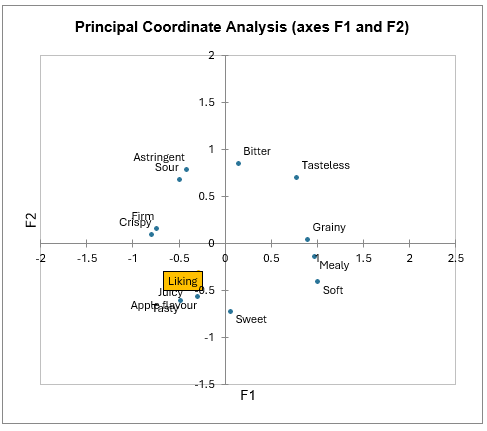
Más información sobre el análisis de coordenadas principales está disponible aquí.
Interpretación de los resultados de un análisis CATA en XLSTAT - Segunda parte
Cuando los datos de agrado están disponibles, los siguientes resultados están relacionados con el análisis de penalizaciones.
Un primer análisis basado en la incongruencia, donde el atributo falta en el producto real pero está presente en el producto ideal, permite identificar los atributos indispensables. Una tabla resumen indica las frecuencias con las que ocurren P(No)|(Yes) y P(Yes)|(Yes) para cada atributo. La representación gráfica que sigue muestra estas frecuencias así como el porcentaje de registros para estas ocurrencias.
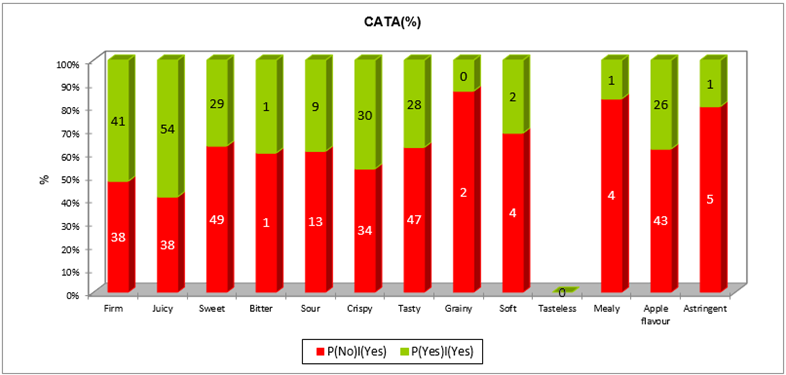
Se presentan luego las caídas medias en el agrado entre las dos situaciones para cada atributo y se prueban sus significancias. Por ejemplo, el atributo "firme" implica un aumento de 1.5 puntos de agrado entre los productos evaluados y el producto ideal. Este aumento es significativo al 0.05 (p < 0.0001).
Nota: En caso de que no haya un producto ideal, este análisis se sustituye por un análisis de la presencia y ausencia de los atributos.
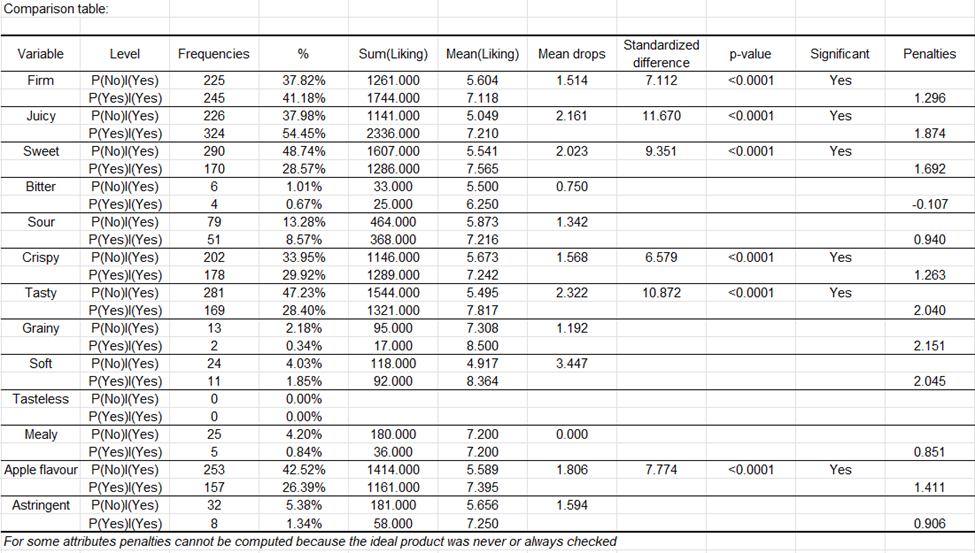
El gráfico del impacto medio muestra los atributos con un impacto medio significativo. Los aumentos medios se muestran en azul y se identifican como "indispensables", mientras que las disminuciones medias se muestran en rojo.
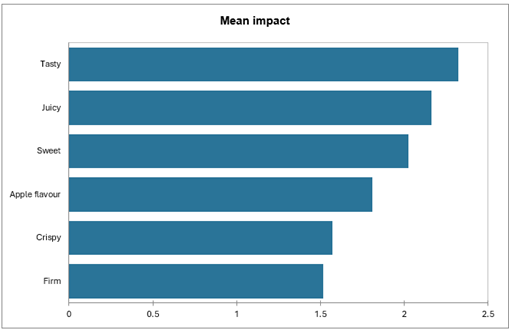
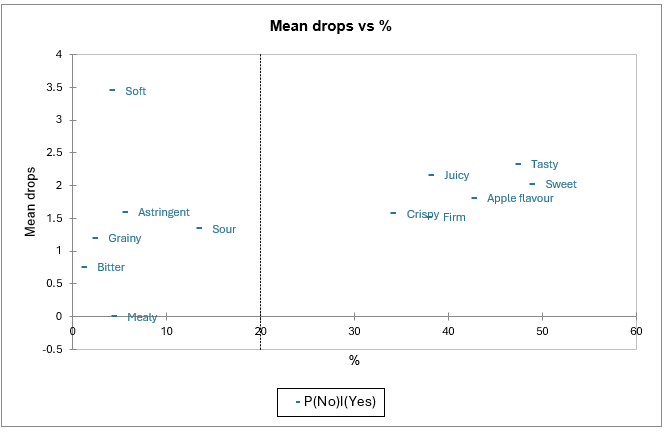
El gráfico de caídas medias vs % también permite identificar claramente los atributos “indispensables”.
-
El eje Y corresponde a las diferencias en la apreciación del producto cuando los consumidores marcan tanto un producto como el producto ideal (celda [1,1] de la tabla de "análisis de atributos") y cuando solo marcan el producto ideal (celda [0,1]).
-
El eje X representa el porcentaje de entradas que incluyen una marca para el producto ideal sin que se marque el producto real. Esto corresponde a una situación en la que el atributo describe bien el producto ideal pero se percibe relativamente poco en los productos reales.
Por lo tanto, los atributos asociados a altas coordenadas en ambos ejes X e Y (sabroso, dulce, jugoso, sabor a manzana, crujiente, firme) aparecen aquí nuevamente como “indispensables”.
Un segundo análisis permite identificar los atributos “agradables de tener”. Es similar al primero, pero se basa en la incongruencia en la que el atributo está ausente en el producto ideal pero presente en el producto real.
Nota: Este análisis solo está disponible cuando se cuenta con un producto ideal.
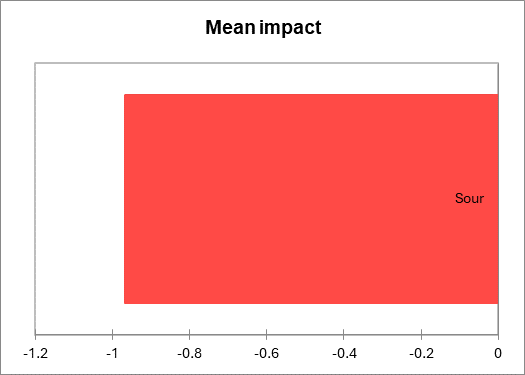
El gráfico del impacto medio muestra los atributos con un impacto medio significativo. Los aumentos medios se muestran en azul y se identifican como “agradables de tener”, mientras que las disminuciones medias se muestran en rojo y se identifican como “no deseables”. Aquí, solo se pudo analizar el atributo Ácido.
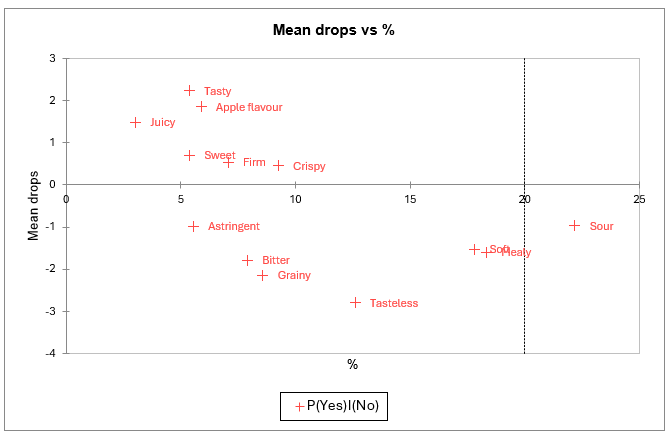
El gráfico de las caídas medias frente al porcentaje también permite identificar claramente los atributos “que no deben tenerse” y “agradables de tener”.
-
El eje Y corresponde a las diferencias en la apreciación del producto cuando los consumidores no marcaron ni el producto ideal ni el producto real (celda [0,0] en la tabla de "Análisis de Atributos") y cuando marcaron el producto (celda [1,0]).
-
El eje X representa el porcentaje de entradas que incluyen una marca para el producto real sin que el producto ideal sea marcado, lo que corresponde a una situación en la que el atributo describe bien los productos reales, pero es relativamente poco marcado para el producto ideal.
Por lo tanto, los atributos asociados a bajas coordenadas en el eje Y (astringente, amargo, granuloso, insípido, blando, harinoso, ácido) aparecen aquí como “que no deben tenerse”. Los atributos asociados a altas coordenadas en el eje Y son “agradables de tener”.
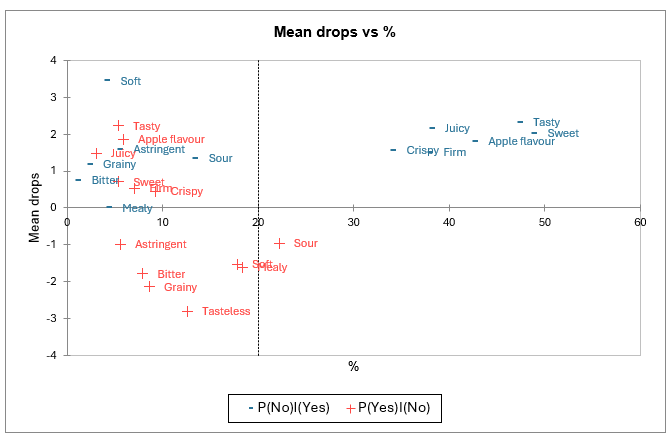
Las dos análisis anteriores se resumen finalmente en un solo mapa. Nuevamente, sabroso, dulce, sabor a manzana, firme, crujiente y jugoso aparecen como “imprescindibles”; y ácido aparece como “no deseable”.
Luego, se muestra una tabla 2x2 para cada atributo. A la izquierda de cada tabla, se encuentran los valores registrados para el producto ideal y en la parte superior, los valores obtenidos para los productos evaluados. En las celdas de las tablas, podemos encontrar la preferencia promedio (promediada sobre los evaluadores y los productos) y el % de todos los registros que corresponden a esta combinación de 0s y/o 1s.
Para un atributo dado, si se ha marcado para el producto ideal (segunda línea de la tabla) y si la preferencia para los productos marcados (celda [1,1]) es significativamente más alta que la preferencia para los productos no marcados (celda [1,0]), entonces el atributo es un “imprescindible”.
Por otro lado, si el atributo no está marcado para el producto ideal (primera línea de la tabla) y si la preferencia para los productos no marcados (celda [0,0]) es significativamente más alta que la preferencia para los productos marcados (celda [0,1]), entonces el atributo es “no deseable”.
Si (celda [0,1]) > (celda [0,0]) de manera significativa, entonces el atributo es “agradable de tener”. Si el atributo no está marcado para el producto ideal (primera línea de la tabla), no es ni “no deseable” ni “agradable de tener”, y si la preferencia para los productos marcados (celda [0,1]) es comparable a la preferencia para los productos no marcados (celda [0,0]), entonces el atributo no perjudica.
XLSTAT considera que dos productos son comparables si el valor absoluto de su diferencia es inferior a 1. Finalmente, si el atributo no es imprescindible y la preferencia para los productos marcados (celda [1,1]) es comparable a la preferencia para los productos no marcados (celda [1,0]), el atributo no influye.
Algunas tablas pueden corresponder a las 3 situaciones.
XLSTAT intentará asociar cada tabla 2x2 a una única situación al vincularla a una de las reglas anteriores, respetando este orden.
Tenga en cuenta que, para tomar una decisión sobre un atributo, XLSTAT verificará que se respete el umbral elegido para el tamaño de la población (pestaña Opciones 2 del cuadro de diálogo). Por ejemplo, para el atributo Firme, el 41% de los productos evaluados (no ideales) están marcados tanto para el producto evaluado como para el producto ideal. La preferencia promedio de estos registros es 7,1.

En la tabla resumen final, podemos ver que 6 de los 15 atributos son “imprescindibles”, 1 es “no perjudicial” y 1 atributo es “no deseable”. Los atributos restantes no pudieron ser relacionados con ninguna categoría.
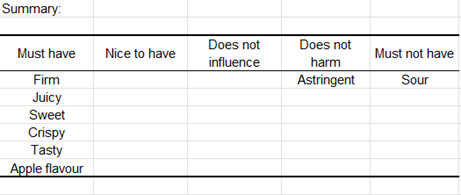
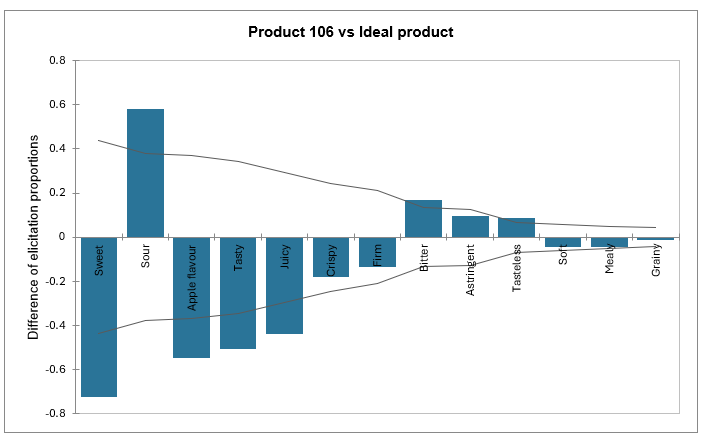
Finalmente, se puede observar una representación gráfica de la diferencia de evaluación para cada producto en comparación con el ideal. Para cada atributo, se puede ver si el producto es similar o diferente al producto ideal. Cuantas más diferencias presenta un atributo, más problemático es y se ubicará en el lado izquierdo del gráfico. En cambio, cuanto más similar sea el producto al producto ideal para un atributo dado, más cerca estará la línea de 0. Si la diferencia es negativa, el atributo no está presente en la cantidad adecuada, mientras que si es positiva, el atributo está demasiado presente.
El intervalo de confianza se utiliza para determinar si la diferencia con el producto ideal es significativa.
En el ejemplo del tutorial, el valor representado por la primera barra en el gráfico 'Producto 106 vs Producto ideal' se puede calcular de la siguiente manera: (6/119) – (92/119) = 0,0504 – 0,7731 = -0,7227.
Para profundizar
Descubra otro método para analizar conjuntos de datos CATA disponible en XLSTAT: CATATIS. Para clasificar a los consumidores con datos CATA, utilice el método CLUSCATA.
¿Ha sido útil este artículo?
- Sí
- No