Classification k-means dans Excel
Ce tutoriel vous aidera à configurer et interpréter une Classification k-means dans Excel avec le logiciel XLSTAT.
Vous n'êtes pas sûr que cet outil de clustering soit celui dont vous avez besoin ? Consultez ce guide.
Jeu de données pour réaliser une classification avec la méthode des nuées dynamiques (k-means clustering)
Les données proviennent du US Census Bureau. Elles correspondent à la mesure de paramètres démographiques dans 51 États des États-Unis en 2000 et 2001. Dans le cadre de ce tutoriel, seules les données de l'année 2001 ont été conservées et, afin de supprimer les effets d'échelle, les variables initiales ont été converties en taux pour 1000 habitants.
But de ce tutoriel
Le but est ici de créer des classes homogènes d'États. Ces données sont aussi utilisées pour le tutoriel de l'Analyse en Composantes Principales (ACP) et dans le tutoriel sur la classification ascendante hiérarchique (CAH).
Remarque : si vous essayez de faire l'analyse proposée ci-dessous sur les mêmes données, il est fort probable que vous n'obteniez pas les mêmes résultats. En effet, la méthode des nuées dynamiques implique un tirage aléatoire. Pour obtenir les mêmes résultats, vous devrez fixer la graine des nombres aléatoires à 4414218 dans les Options/Avancées de XLSTAT.
Paramétrer une classification avec la méthode des nuées dynamiques (k-means clustering)
-
Une fois XLSTAT lancé, cliquez sur Analyse de données / Classification k-means.
-
La boîte de dialogue du clustering k-means apparaît.
-
Sélectionnez les données sur la feuille Excel. Dans cet exemple, les données commencent à la première ligne, il est donc plus rapide et plus facile d'utiliser le mode de sélection par colonne. Cela explique pourquoi les lettres correspondant aux colonnes sont affichées dans les cases de sélection.
-
La variable POPULATION TOTALE n'a pas été sélectionnée, car nous nous intéressons principalement aux dynamiques démographiques. La dernière colonne (> 65 POP. EST.) n'a pas été sélectionnée car elle est complètement corrélée avec la colonne précédente.
-
Étant donné que le nom de chaque variable est présent en haut du tableau, nous devons cocher la case Étiquettes des variables.
-
Le critère sélectionné est le Déterminant(W) car il permet d'éliminer les effets d'échelle des variables.
-
La distance euclidienne est choisie comme indice de dissimilarité car c'est la plus classique à utiliser pour le clustering k-means.
-
Nous avons défini le nombre de clusters à créer sur 4.
-
Enfin, les étiquettes de ligne sont sélectionnées (colonne ÉTAT) car le nom de l'État est spécifié pour chaque observation.

-
Dans l'onglet Options, nous avons augmenté le nombre de répétitions à 10 afin d'améliorer la qualité et la stabilité des résultats.
-
Enfin, dans l'onglet Sorties, nous pouvons choisir d'afficher une ou plusieurs tables de sortie.
Interpréter les résultats d'une classification avec la méthode des nuées dynamiques (k-means clustering)
Après les statistiques descriptives des variables sélectionnées, et la synthèse des différentes répétitions, XLSTAT indique comment se décompose l’inertie pour la classification optimale. La décomposition de l’inertie pour la meilleure partition parmi les répétitions est affichée. (Rappel : Inertie Totale = Inertie inter-classes + Inertie intra-classe).

Après une série de tableaux donnant les barycentres des classes, la distance entre chaque barycentre, les objets centraux (il s’agit des États les plus proches des barycentres), un tableau réparti les États par classe.
Le tableau ci-dessous indique pour chaque classe les États qui lui ont été affectés.

Un tableau présente ensuite pour chaque État, l'identifiant de classe auquel il a été affecté. Une partie du tableau est présentée ci-dessous. On pourra ensuite fusionner ces données avec le tableau initial pour d'éventuelles analyses complémentaires (une analyse discriminante par exemple).
Les options Corrélations avec les barycentres et Coefficients de silhouette étant activées, les colonnes associées se retrouvent dans ce même tableau :

Un graphique correspondant au coefficient de silhouette permet de juger visuellement l’appartenance d’une observation à une classe. Si le coefficient de silhouette est proche de 1, l’observation est jugée bien classée. À contrario, si le coefficient est proche de -1, l’observation est alors moyennement plus proche en distance d’une autre classe.

Les coefficients de silhouette moyens par classe peuvent être comparés afin de connaître quelle classe est la plus homogène selon ce coefficient.
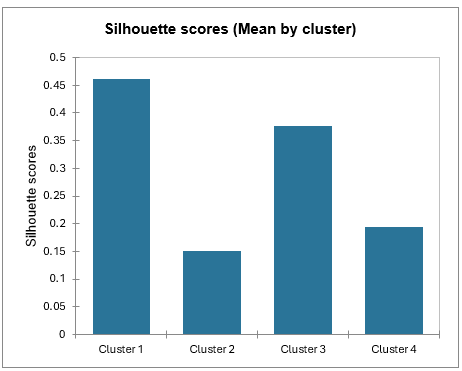
La classe 1 est la classe avec le coefficient de silhouette le plus élevé. Cependant, la classe 2 possède un coefficient proche de 0, il serait alors judicieux de modifier le nombre de classes. En effet, dans le tutoriel sur la Classification Ascendante Hiérarchique CAH, on montre qu'il serait plus pertinent de regrouper les États en trois classes plutôt qu'en quatre.
La vidéo ci-dessous vous montre comment réaliser ce tutoriel sur les nuées dynamiques.

Cet article vous a t-il été utile ?
- Oui
- Non