Arbre de classification (CHAID) dans Excel
Ce tutoriel vous aide à construire un arbre de classification CHAID dans Excel en utilisant le logiciel de statistiques XLSTAT.
Jeu de données pour créer un arbre de classification (CHAID) et but de ce tutoriel
Les données proviennent de [Fisher M. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7, pp 179 -188] et correspondent à 150 fleurs d'Iris, décrites par 4 variables quantitatives (longeur des sépales, largeur des sépales, longueur des pétales, largeur des pétales), et par leur espèce. Trois espèces font partie de cette étude : setosa, versicolor et virginica.
Notre but est de vérifier si les quatre variables descriptives permettent de prédire efficacement à quelle espèce appartient une fleur, et si tel est le cas, d'identifier les règles qui permettent de déterminer l'espèce d'une fleur connaissant la valeur des 4 variables descriptives.



Iris setosa, versicolor et virginica.
Paramétrer l'arbre de classification (CHAID)
Une fois XLSTAT lancé, choisissez la commande XLSTAT / Machine Learning / Arbres de classification et régression.
La boîte de dialogue apparaît, vous pouvez commencer la sélection des données sur la feuille Excel.
On sélectionne la variable dépendante, qui est dans ce cas précis la variable qualitative "espèce d'Iris". Les variables explicatives sont les quatre variables descriptives : longueur des sépales, largeur des sépales, longueur des pétales, largeur des pétales.
L'option Libellés des variables est laissée activée car la première ligne des colonnes sélectionnées comprend le nom des variables. Nous choisissons la méthode CHAID pour créer l'arbre.
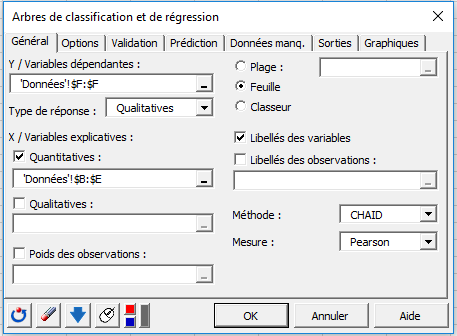
Ensuite, pour ne pas avoir un arbre trop complexe, nous précisons dans les options que nous ne voulons pas que la profondeur de l'arbre dépasse 3. Les options permettent d'ajuster plusieurs paramètres ayant une incidence sur la construction des arbres.
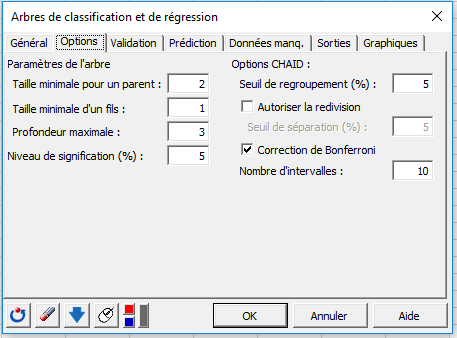
En sortie graphique, nous choisissons d'afficher l'arbre en utilisant des diagrammes en bâtons pour représenter les fréquences des espèces au niveau de chaque nœud de l'arbre.
Les résultats présentés ci-dessous utilisent aussi la représentation des nœuds avec des diagrammes circulaires.
Une fois que vous avez cliqué sur le bouton OK, les calculs commencent et les résultats sont affichés.
Interpréter les résultats d'un arbre de classification (CHAID)
Les deux premiers tableaux regroupent les statistiques descriptives des différentes variables et le tableau des corrélations. En dessous est affichée la matrice de confusion qui résume l'information des reclassements d'observations, et qui permet de déduire les taux de bon et mauvais classement. Le "% correct" correspond au rapport du nombre d'observations bien classées sur le nombre total d'observations.
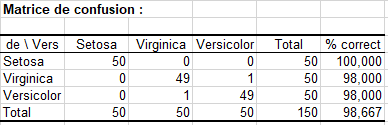
On notera que seulement deux observations ont été mal classées.
Le tableau qui suit nous donne des informations sur la population au sein de chacun des nœuds. En plus de l’effectif total du nœud sont affichés les effectifs par classe (ou modalité) et le pourcentage correspondant. Ces informations permettent de voir la répartition des classes au sein des différents nœuds.
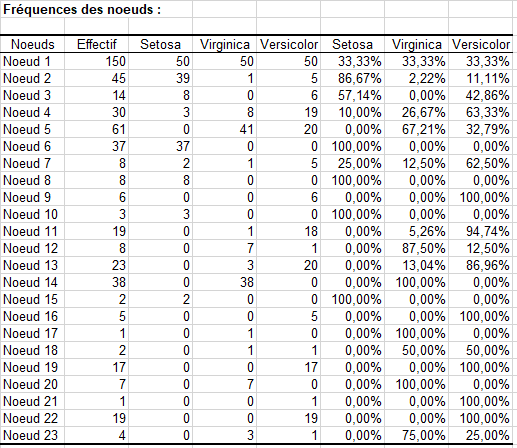
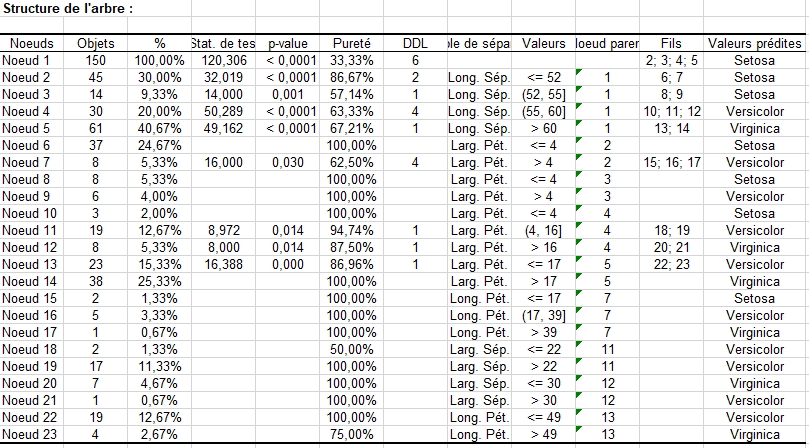
Vient ensuite la structure de l'arbre sous forme de tableau. Il décrit pour les différents nœuds, le nombre d'objets au niveau de chaque nœud, le % correspondant, la statistique de test, la p-value des tests calculés, la pureté qui mesure le % d'objets se trouvant dans la classe (ou modalité) dominante au niveau du nœud, les degrés de liberté du test, les nœuds parent et fils, la variable de séparation, la ou les valeurs correspondantes (des intervalles pour les variables quantitatives explicatives), et la classe prédite par le nœud.
Le tableau suivant présente une lecture de l'arbre sous forme de règles en langage naturel. Pour chaque nœud, la règle correspondant à la classe prédite est affichée. Le % correspondant à la classe au niveau du nœud étant lui donné par le % d’observations dans le nœud.
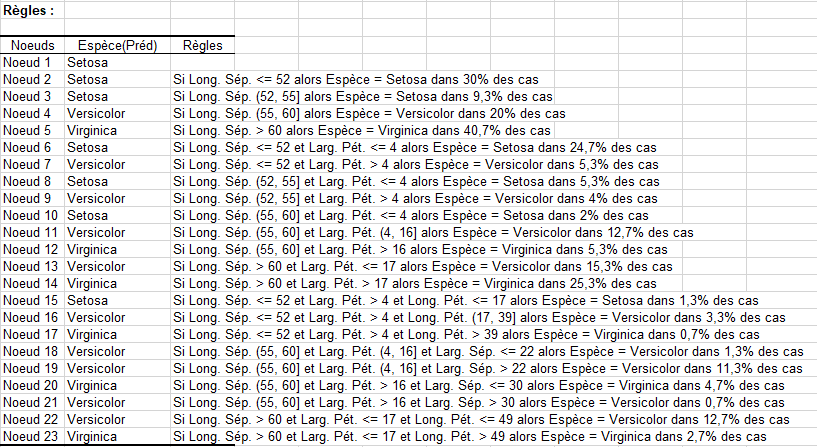
Ainsi on voit que : " Si Larg. Pét. <= 4 alors l’espèce est Setosa dans 32% des cas ", cette règle nous permet d’obtenir le nœud 2 et est vérifiée pour 48 fleurs (32% des données) avec une pureté au niveau du nœud de 100% comme indiqué dans le tableau structure de l’arbre. Nous avons donc l’ensemble des observations de ce nœud qui sont bien classées.
Une partie de l'arbre de classification générée est affichée ci-dessous.
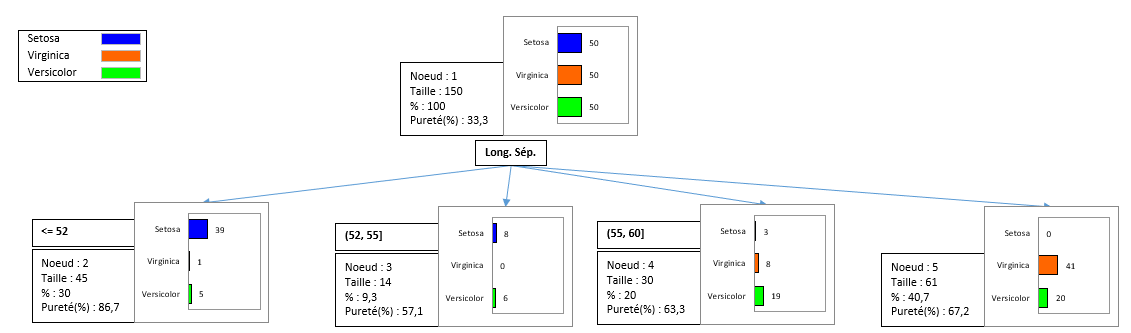
Ce diagramme permet de visualiser les étapes successives au cours desquelles l'algorithme CHAID identifie les variables qui permettent de séparer au mieux les différentes catégories de la variable dépendante.
Les différentes informations fournies au niveau de chaque nœud sont détaillées ci-dessous.
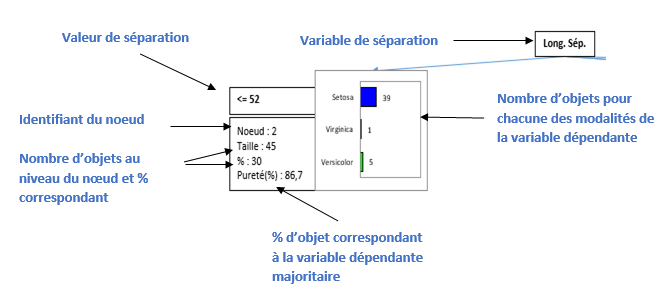
L'algorithme s'arrête lorsque plus aucune règle ne peut être trouvée, ou lorsque l'une des limites fixées par l'utilisateur est atteinte (nombre d'objets au niveau du nœud parent ou fils, profondeur de l'arbre, p-value limite pour retenir une variable de séparation).
Une visualisation alternative est proposée par XLSTAT. Au lieu de représenter les distributions au niveau de chaque nœud avec des diagrammes en bâtons, XLSTAT permet aussi de les représenter avec des diagrammes circulaires, qui s'avèrent plus lisibles lorsqu'il y a de nombreux nœuds et plus de 4 ou 5 modalités pour la variable dépendante. Le disque intérieur permet de visualiser la distribution des différentes modalités (ou intervalles) au niveau de ce nœud. L’anneau extérieur correspond à la distribution de ces mêmes modalités au niveau du nœud parent.
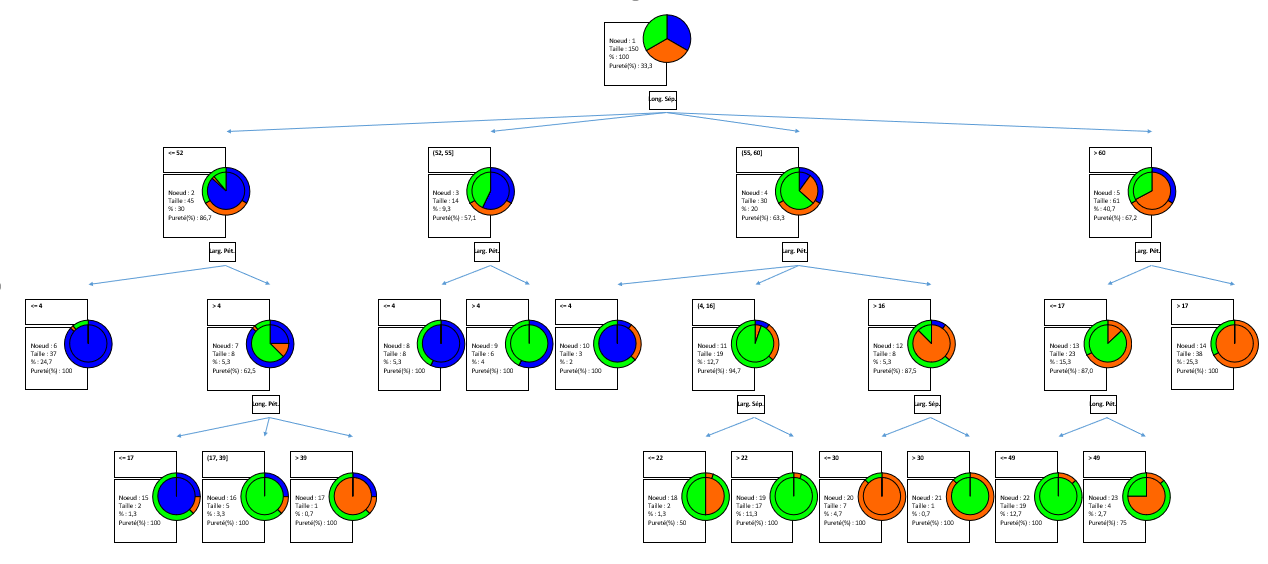
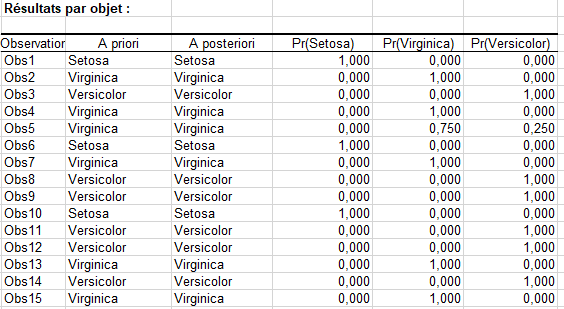
Les règles correspondant aux feuilles de l’arbre (les nœuds terminaux) permettent de calculer les prédictions pour chacune des observations, avec une probabilité dépendant de la distribution des modalités au niveau de chacune des feuilles. Ces résultats sont affichés dans le tableau des "résultats par objet".
Cet article vous a t-il été utile ?
- Oui
- Non